第1章 Python 数据分析准备
1.1 Python 数据分析基础
近些年来,数据分析和 Python 这两个词总是连在一起。那么,到底什么是数据分析?做数据分析为什么要选择 Python?Pandas 之于 Python 意味着什么?本节就来回答这些问题。
数据分析的基本概念
首先,我们来聊聊“什么是数据分析”这个常看常新的话题。
从定义上来看,数据分析是指通过工具处理和分析,从数据中得到有价值的洞察,给出建议并持续追踪的过程。
整个过程可以分为 6 个阶段:明确分析目标—数据获取—数据分析—结论输出—追踪验证。
1)明确分析目标:在展开分析之前,明确分析目标非常重要,甚至决定了分析的整体走向。最原始的需求方是谁?想解决什么问题?他描述的需求能否解决本质问题?如果不能,需求应该做怎样的调整?只有先和需求方多沟通,用一系列灵魂拷问找到最本质的分析目标,才能让分析有的放矢。
2)数据获取:从内外部获取数据,内部可以直接从数据库或留存的文件中获取,外部一般依赖于爬虫或付费购买。
3)数据清洗:原始数据经常会有各种问题,例如存在缺失值、重复值、格式错误、极端异常值等。我们需要清洗数据来解决这些问题,保证数据的“干净整洁”。
4)数据分析:利用合适的工具对数据做进一步处理和分析,包括建立模型、进行描述性分析、进行探索性分析等。需要注意的是,一切分析都要始终围绕分析目标进行。
5)结论输出:整理并汇总上一步数据分析的结果,用可视化的方式来呈现,并提炼出最关键的结论和建议。在结论输出的过程中,和需求方多轮沟通,适当引入业务的视角,避免就数论数。
6)追踪验证:给出建议并不是最后一步,数据分析师需要追踪建议的执行结果。建议被采纳了多少?执行效果具体怎样?有哪些经验或者问题可以总结?在复盘中验证和进步。
基于数据分析,我们可以量化决策、诊断现状、挖掘原因、预测未来,真正做到点“数”成金。
正如武林中的绝世剑客都有一把绝世好剑一样,一个优秀的数据分析师要想大显身手,也需要一把趁手的“武器”。接下来,我们一起来认识下这把“武器”——Python。
为什么选择 Python
很多读者在学习数据分析的过程中,都纠结过“到底应该学什么数据分析工具”这个问题。市面上数据处理、分析、可视化相关的工具非常多,比如 Excel、R 语言、SQL 和 Python 等。这些工具各有各的优势和应用场景,而 Python 凭借极其丰富的、导入即用的数据分析库以及极强的拓展性,成为数据分析领域非常流行的工具之一。
基于 Python,我们可以爬取数据,可以根据需求轻松地对大量数据进行处理和分析,可以绘制炫酷的图表,还可以把分析好的数据结果做成报表并自动用邮件发送给相关的同事,功能强大又便利。
Pandas 和 Python 的关系
Python 的强大之处在于非常灵活,而且有丰富的工具包(Python 中常叫作库)。做个类比,如果把 Python 当作一种万能的材料,有大神已经用 Python 打造出很多工具,例如汽车、空调、电脑。当我们要开车的时候,不用再花时间了解汽车的构造与组装原理,更不用自己重新制造汽车,只需要明确目的地,启动后控制好方向盘、油门和制动系统就好。
Pandas 就是基于 Python 打造的专门用来做数据处理和分析的“超级跑车”,它把数据处理的底层原理和复杂的实现过程已经封装好了,我们导入直接调用就好。所以,Pandas 学习的重点在于掌握驾驶这辆“跑车”的核心技术。
准备好,我们一起上车吧!
1.2 如何高效学习 Pandas
正确的方法对于技能的学习尤为重要,对于 Pandas 来说,逐个模块硬啃是一种学习方法,但我认为并不正确。那么,学习 Pandas 有哪些误区一定要避开,又有什么高效的学习方法呢?且听我一一道来。
Pandas 学习中的误区
在战场上,向敌人发起冲锋之前,把预期经过路线上的陷阱排掉,可以有效地保存实力。为了更高效地学习,在正式开始讲 Pandas 操作之前,我觉得有必要先和大家聊聊 Pandas 学习中的常见误区。
很多对 Python 数据分析感兴趣的学习者很快就熟悉了 Python 基础语法,然后下定决心,一头扎进好几百页的经典大部头中,硬着头皮啃完之后,好像自己什么都会了一点,然而实际操作起来要么无从下手,要么漏洞百出。
究其原因,理解不够、实践不够是两只经典的“拦路虎”,我们只能靠自己多想多练来克服。还有一个非常有意思且经常被忽视的因素——陷入举三反一的糊涂状态。
什么意思呢?假如我是只早鸭子,想去学游泳,教练很认真地给我剖析了蛙泳的动作,扶着我的腰让我在水里划拉了 5 分钟,接着马上给我讲解了蝶泳,又让我划拉了 5 分钟,然后又硬塞给我仰泳的姿势,依然让我划拉 5 分钟。最后,教练一下子把我丢进踩不到底的泳池,给我呐喊助威。
对于我这只还没入门的旱鸭子,教练倾囊传授给我 3 种游泳技巧,并让我分别实践了 5 分钟。这样做的结果就是我哪一种游泳技巧也没学会,只学会了喝水。
如果一个初学者一开始就陷入针对单个问题的多种解决方法,而对每一种方法的实践又浅尝辄止,那么他在面对具体问题时往往会手忙脚乱。
拿 Pandas 来说,它有多种构造方式、多种索引方式以及类似效果的多种实现方法,初学者如果上来就贪大求全地去挑战“某种操作的 N 种实现方法”,很容易陷入举三反一的糊涂状态,结果学了多种实现方式,但真到用的时候连一种都用不好。
所以,为了避免大家陷入各种操作实现的细节,我会结合数据分析工作中的实际使用情况,提炼出高频 Pandas 知识点,一切以数据分析应用为导向,让学习更加明确。
高效学习 Pandas
- 二八法则在 Pandas 中的应用
刚才我们了解了 Pandas 学习的误区,那些是不建议做的,但到底应该怎样做才能高效学习 Pandas 呢?
在二八法则的基础之上,我总结出了“二八学习法”,它适用于很多技能类的学习。拿 Pandas 学习来说:
第一步,以结果为导向,明确学习目的。很多人学习 Pandas 是为了提升数据处理和分析效率。
第二步,基于目标,花
第三步,花
一句话总结二八学习法:花
最终,我们虽然只掌握了某个技能或工具不到
- Pandas 学习路线
Pandas 学习路线应该是怎样的?为了更好地回答这个问题,以结果为导向,我带大家还原几个高频场景。
- 有数可用。数据是一切分析的基础,要用 Pandas 来做数据分析,首先得有数据。因此,第一个高频场景是熟悉 Pandas 的基础数据结构以及用 Pandas 打开各种常见类型的数据源。
- 认识数据。有了数据之后,常见的操作是先对数据做一个总览,比如数据长什么样子,包含多少行多少列,每一列的格式是怎样的,有没有缺失值等。对数据进行快速扫描是第二个高频场景。
- 操作数据。对数据有了基本的认知后,我们需要结合分析目的,对数据进行一系列操作,包括在原有数据基础上创建新的列,删除某些异常的行和空缺过多的列,基于某些分析条件筛选出我们想要的数据,以及对原有数据做其他处理。这些操作可以概括为增、删、选、改,其中最重要的是选。
- 高效灵活地处理数据。常规的增、删、选、改操作已经能够覆盖大部分的需求,但在有些场景下需要一定的自定义化,例如通过自定义函数和 apply 结合的方式,极其灵活地完成更复杂的数据处理。这些场景可以概括为 Pandas 的进阶操作。
总结一下,本书将会从数据创建和导入、数据预览、增删选改、进阶操作几个方面重点展开,以贴合实际的数据分析场景。
最后需要注意的是,Pandas 和 Excel、SQL 相比,只是调用、处理数据的方式不同,核心也是对数据进行一系列的处理和分析。在正式处理之前,更重要的是谋定而后动,明确分析的意义,厘清分析思路之后再处理和分析数据,一定会事半功倍。
1.3 Python 所需的环境搭建
Python 的使用需要配置对应的环境,本节将介绍 Python 环境的选择和相关环境的安装、配置。已经配置好 Python 编程环境的读者可以直接跳过本节。
Python 环境的选择
对于刚上手的新手来说,Python 的安装、环境配置和各种库的安装烦琐且容易出错。在这种情况下,Anaconda 是个不错的选择。它是一个 Python 的集成环境管理器,包含大部分数据分析中常用的库,如 NumPy、Pandas、scikit- learn 等。
简单地说,我们要用 Python 来做数据分析,Anaconda 就是一个贴心的管家,它已经准备好了绝大多数的东西,我们可以一键安装,直接“拎包入住”。
Anaconda 的下载和安装
- 下载
Anaconda 是开源的,可以直接从官网https://www.anaconda.com下载。在如图 1- 1 所示的界面中选择合适的操作系统。

图 1-1 Anaconda 官网下载页面
跳转之后,根据自己的操作系统和版本选择对应的地址,写作本书时默认是适配 Python 3.9 的版本,单击之后会自动开始下载。
- 安装
下载好了之后,双击打开安装包,先后单击 Next 和 I Agree 按钮,如图 1- 2 所示。
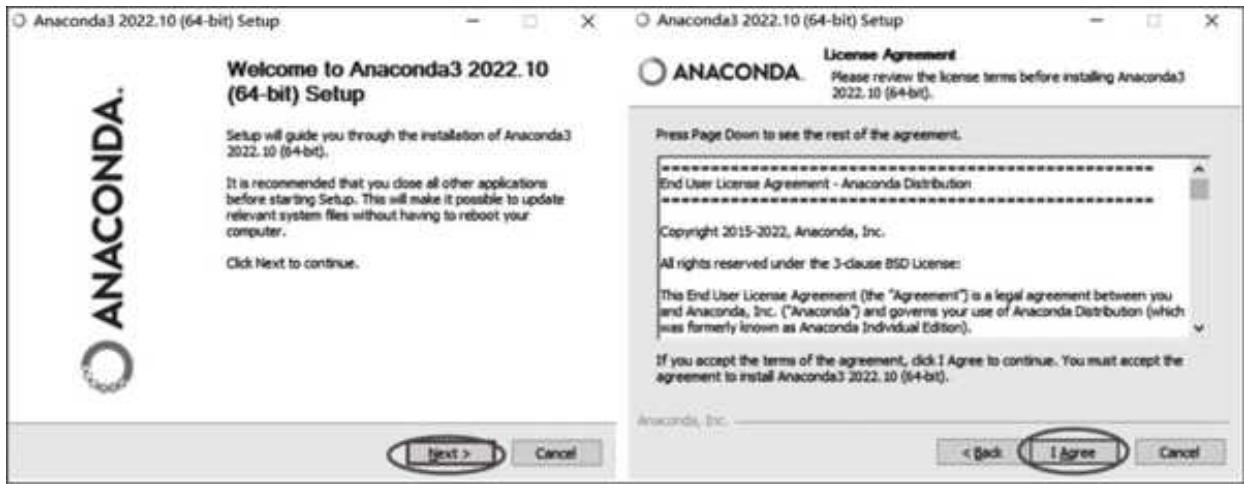
图 1-2 初始安装选择
在安装页面可以默认选择 All Users 选项,如图 1- 3 所示。因为我们一般都是用自己的计算机,所以选择 Just Me 还是 All Users 差别不大。
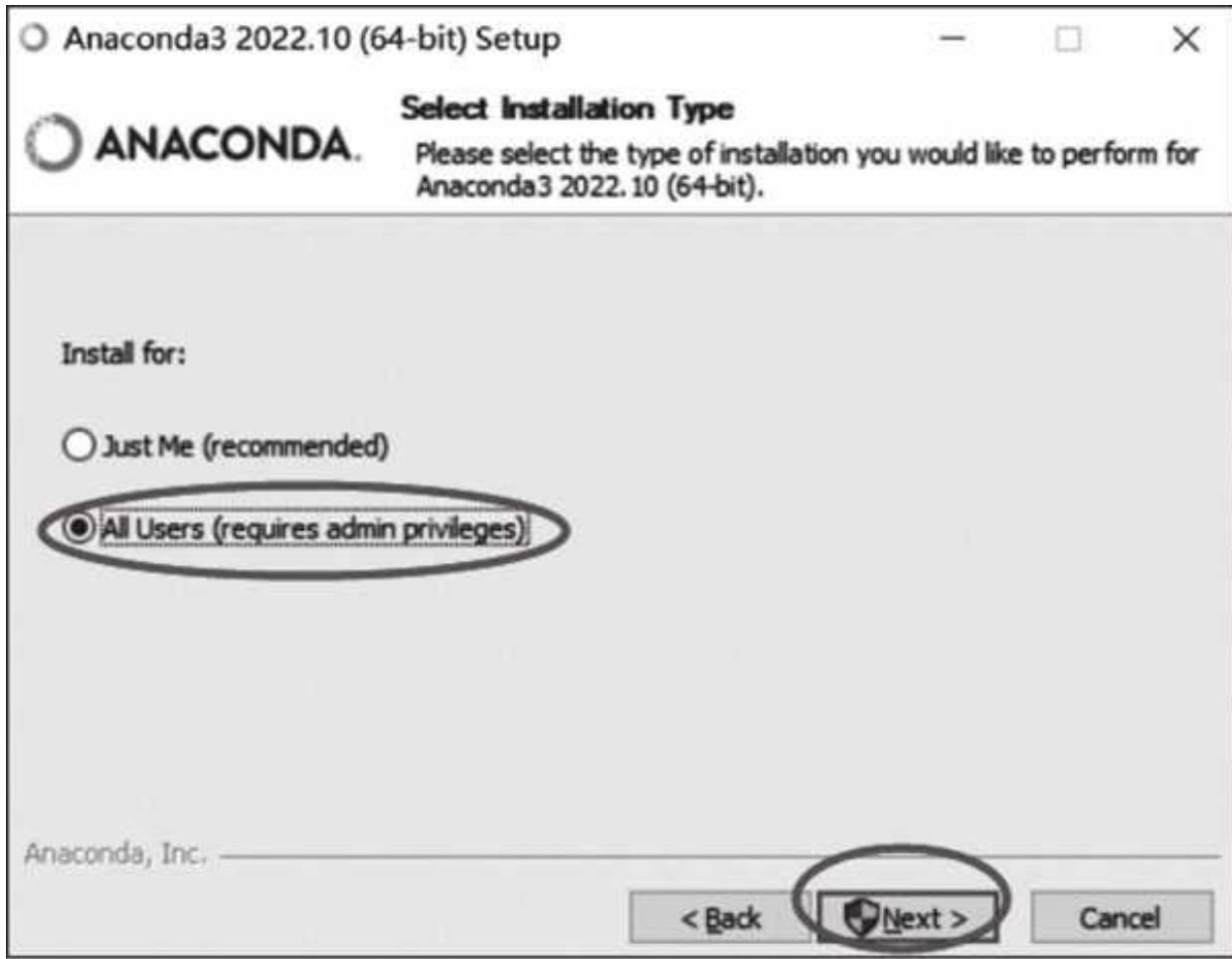
图 1-3 安装用户选择
接下来一步的选择比较重要,我们只勾选下面的那个选项,上面的不勾选,如图 1- 4 所示,否则可能会出现问题。
等待安装完毕,中间几步操作单击 Next 按钮即可。
最后有两个关于帮助和资源的选项(实际没什么用),不选,然后单击 Finish 按钮,如图 1- 5 所示。
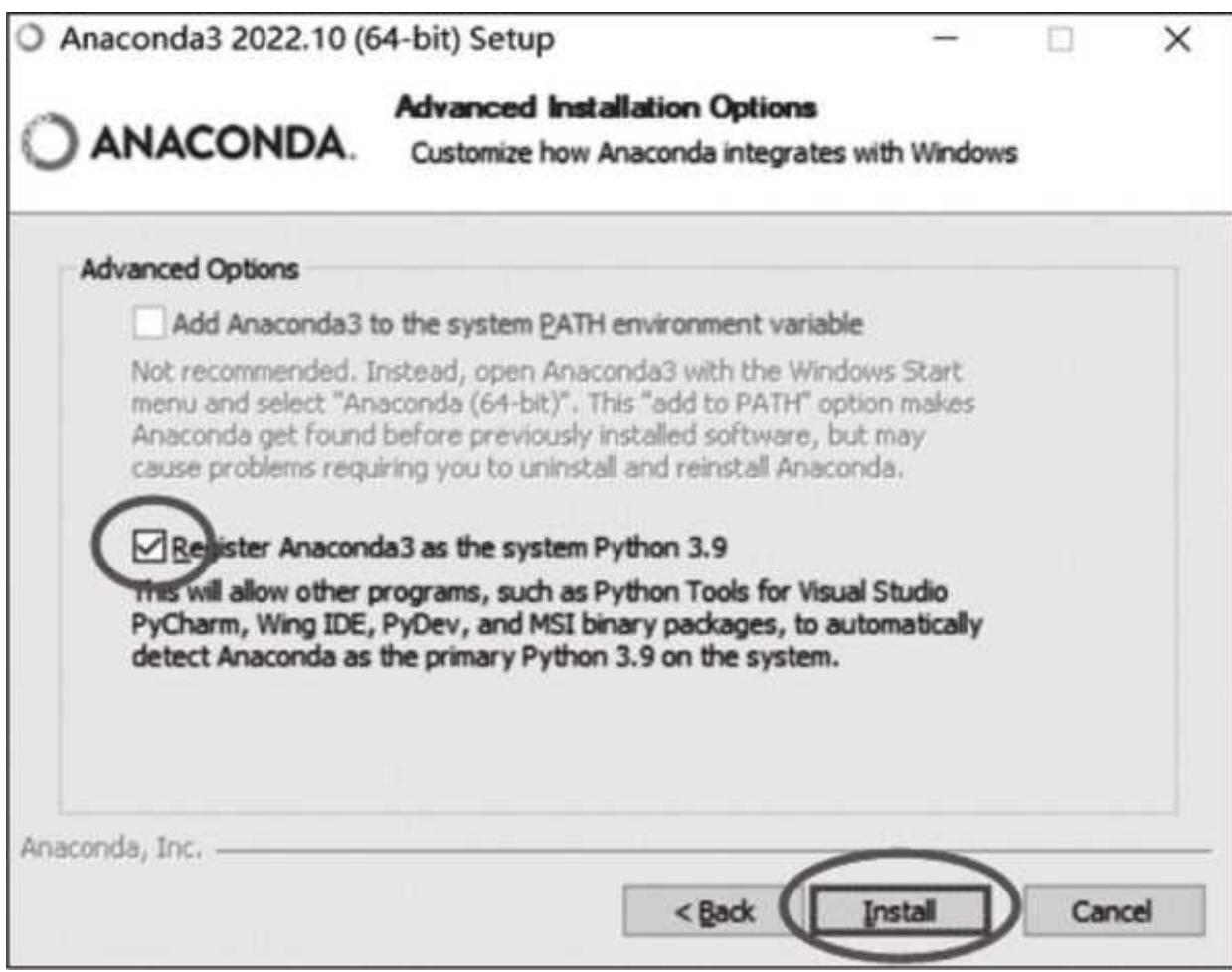
图 1-4 安装的进阶选项
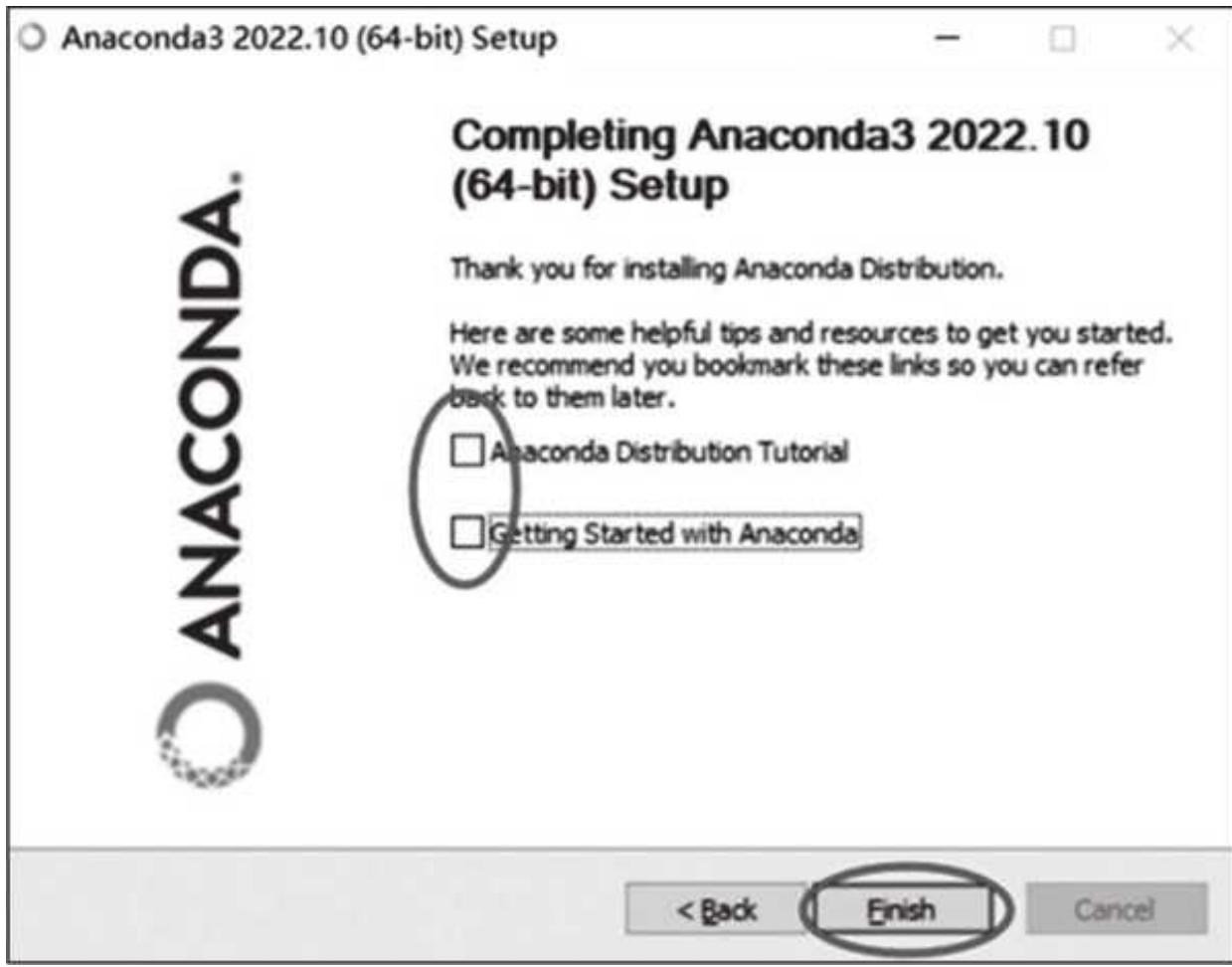
图 1-5 安装完成页面的选择
到这一步,我们已经成功安装了 Anaconda。
运行代码
- 什么是 Jupyter Notebook
安装 Anaconda 的时候,安装程序默认帮我们安装了 Jupyter Notebook。
Jupyter Notebook 是一个轻量级的程序(IDLE),它以网页的形式打开,让我们可以直接在网页中编写、导入及运行代码。它的交互性很强,分小模块运行代码可以马上在网页中反馈结果,非常方便。其轻便和易用的特点很好地契合了数据分析的使用场景,本书中所有的代码实践都是基于 Jupyter Notebook 进行的。
- 启动 Jupyter Notebook
由于我们刚安装好 Anaconda,单击计算机左下角(这里以 Windows 10 为例),“最近添加”模块显示了 Anaconda 相关的内容,如图 1- 6 所示。

图 1-6 Windows 10 的“最近添加”模块
也可以直接在搜索栏中搜索 Jupyter Notebook,打出前几个字母就会模糊匹配到,如图 1- 7 所示。
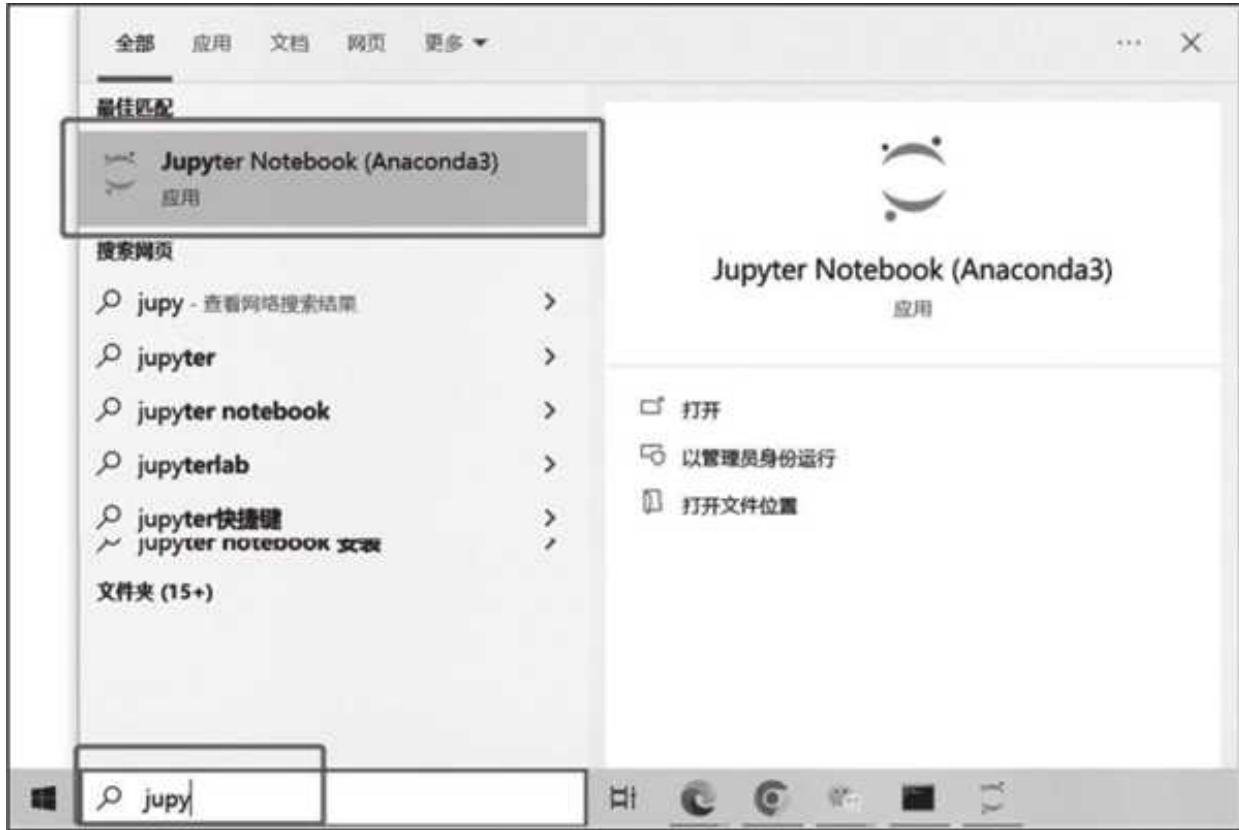
图 1-7 在 Windows 10 的搜索栏中搜索 Jupyter Notebook
单击 Jupyter Notebook 图标,正常情况下页面会自动跳转到如图 1- 8 所示的页面,中间还会弹出一个小黑框的后台程序,不要管它,将其最小化即可。
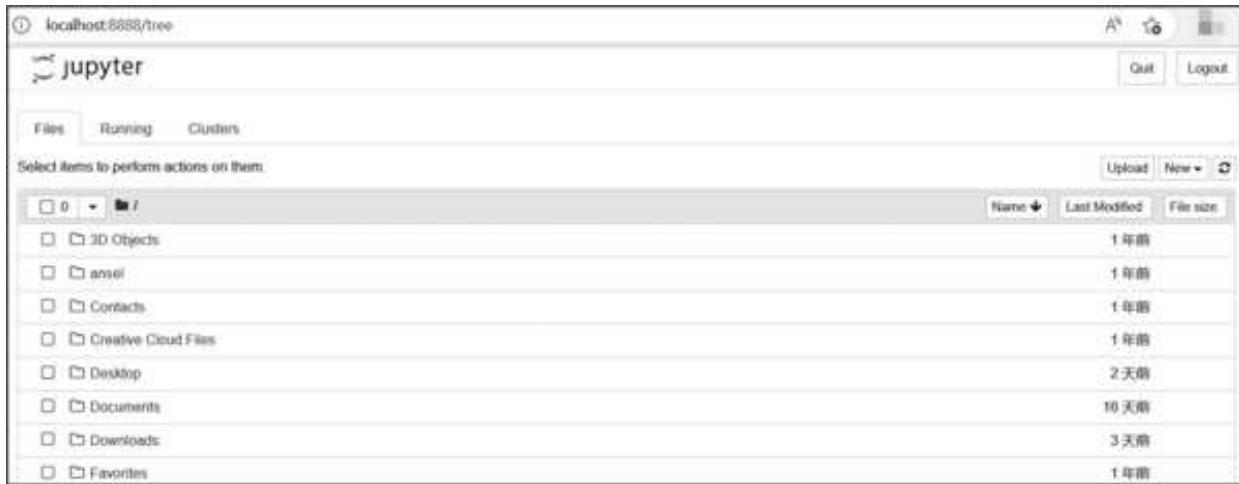
图 1-8 Jupyter Notebook 初始页面
- 创建一个文件
Jupyter Notebook 的功能和技巧有很多,我按照最主要的路径带大家熟悉一下。
在实际操作中,我们会产生很多的代码和文档,因此第一步是创建文件夹,以方便对代码进行分类。Jupyter Notebook 中创建文件夹(Folder)的按钮在右上角,如图 1- 9 所示。
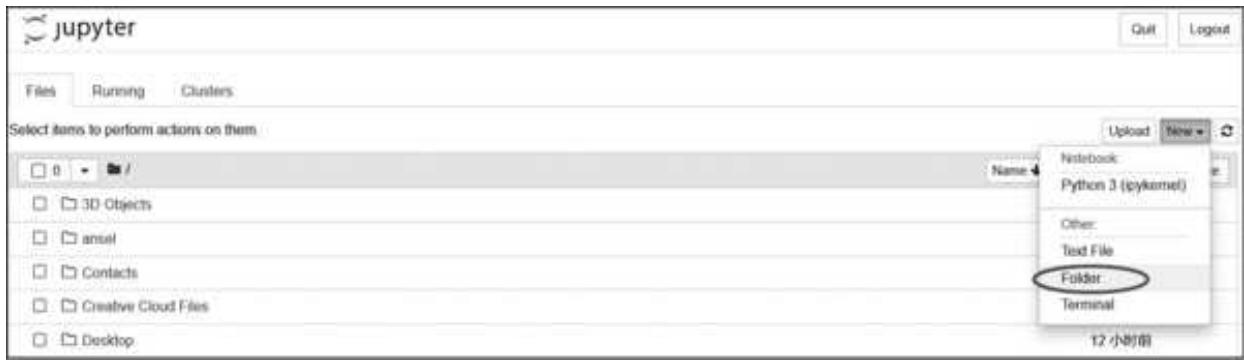
图 1-9 在 Jupyter Notebook 中创建文件夹
文件夹默认是未命名的,可以在选中文件夹之后单击 Rename 按钮来重命名,如图 1- 10 所示。

图 1-10 Jupyter Notebook 文件重命名
然后进入文件夹,创建一个 Python 文件,如图 1- 11 所示。
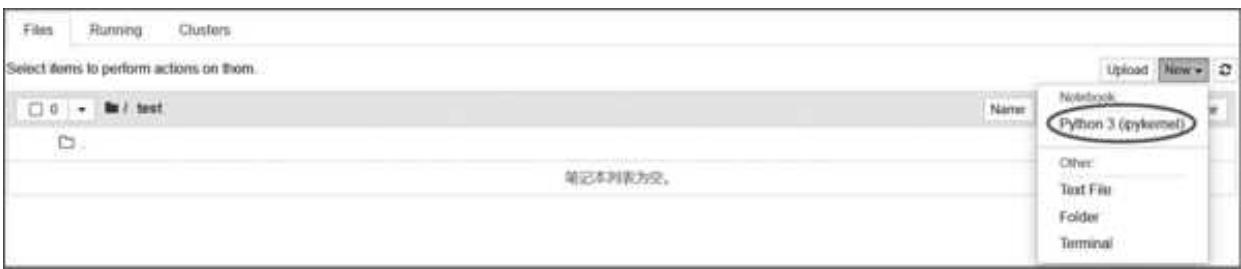
图 1-11 在 Jupyter Notebook 中创建 Python 文件
在打开 Python 文件的界面中有几个区域:最上面是文件名,单击即可重命名;中间是文件编辑区,不太常用,因为几乎都有对应的快捷操作来替代;下面的长条框就是我们编写和运行代码的“主战场”,如图 1- 12 所示。
- 运行代码
我们可以在代码编辑区直接输入代码 print('Talk is cheap,show me the code'),然后按Ctrl + Enter 来运行代码,如图 1- 13 所示。
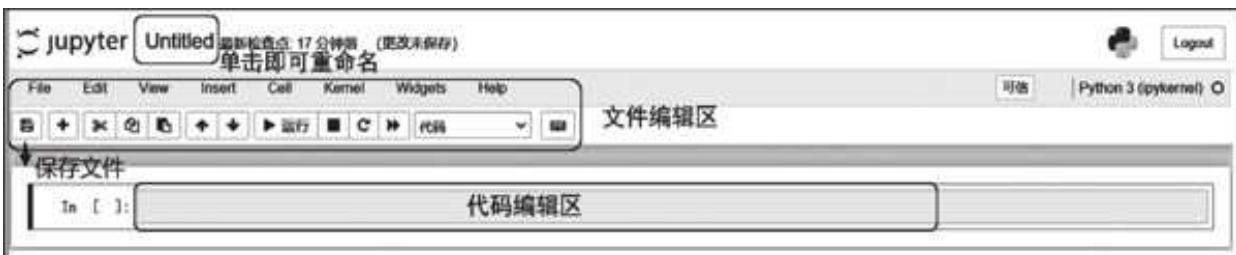
图 1-12 Jupyter Notebook 代码编辑页面

图 1-13 运行代码的效果
代码成功运行并反馈打印结果。一般情况下,我们运行完一个小模块的代码之后,还会在新增的代码框中继续编写。如果我们编写完上面的代码,按 Alt + Enter 组合键来运行,则会在运行代码的同时新增代码框,方便后续代码的编写,如图 1- 14 所示。

图 1-14 运行代码的效果
- 导入外部代码
除了自己编写代码,另一个常用的场景就是导入外部的代码。这本书所有的代码我已经整理并打包好了,大家可以通过前言中提供的方式直接下载。将下载后的代码导入 Jupyter Notebook 即可运行。
在 Jupyter Notebook 文件夹下,单击右上角的 Upload 按钮,如图 1- 15 所示。

图 1-15 导入文件的入口
再选择对应的路径和代码文件,如图 1- 16 所示。
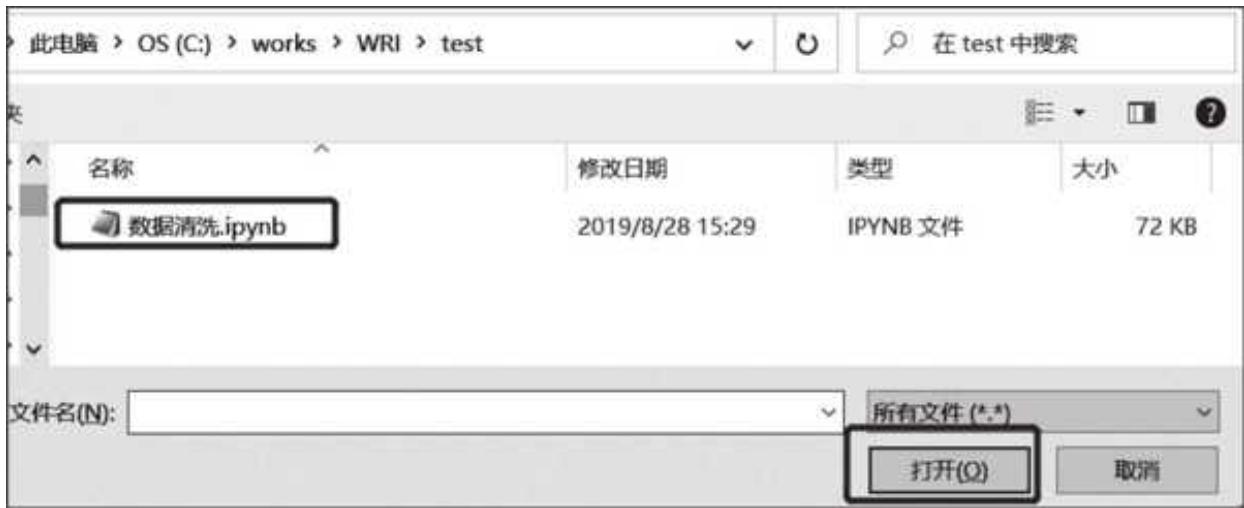
图 1-16 导入路径及文件选择
之后数据清洗. ipynb 文件被自动导入 Jupyter 中,此时只需单击“上传”按钮即可,如图 1- 17 所示。

图 1-17 最终上传选项
- 快捷操作一览
Jupyter Notebook 的快捷操作分为命令模式和编辑模式两种。
当我们单击代码区块左边的区域,或者在编辑之后按Esc键时,区块左侧边框是蓝色的,代表命令模式,如图 1- 18 所示。

图 1-18 命令模式效果
编辑模式则是我们单击区块编辑代码的模式,这时左侧边框呈现绿色,代码框里有光标闪烁,如图 1- 19 所示。

图 1-19 编辑模式效果
两种模式下的快捷键 Jupyter Notebook 已经整理好,分别如图 1- 20 和图 1- 21 所示。

图 1-20 命令模式快捷键

图 1-21 编辑模式快捷键
大家可以把这里的快捷操作一览看作字典,当在实践过程中遇到问题时,再来查阅。
为了更好地学习本书内容,读者最好具备一定的 Python 基础知识。不过别担心,学习本书所需的 Python 基础知识并不多,你只要了解 Python 中的基础变量、常见数据类型、判断与循环语句、函数就足够了。当然,就算你不熟悉这些也没关系,我特意写了一个 Python 极简教程,以帮助有需要的读者快速入门。由于 Python 基础不是本书的重点,因此不在这里展开,在我的微信公众号“数据不吹牛”后台回复关键字“Python 教程”即可获取该教程。
1.4 本章小结
数据分析流程分为 6 个阶段,分别是明确分析目标、数据获取、数据清洗、数据分析、结论输出和追踪验证。Python 凭借其丰富而强大的库和便捷、灵活的特性,成为数据分析领域的热门语言,而 Pandas 则是 Python 数据分析领域的“超级跑车”。
初学者在学习 Pandas 时很容易陷入细节而迷失方向,依据二八法则,花
Pandas 的学习可遵循有数可用、认识数据、操作数据以及高效灵活地处理数据这一主线,再结合实战案例,不断巩固和强化知识。
Anaconda 为我们免去了 Python 环境的配置问题,其配套的 Jupyter Notebook 则是编写和运行代码的“主战场”。