第2章 Pandas 快速入门
2.1 Pandas 的两大数据结构
初识 Pandas
首先,我们从 Pandas 的核心数据结构讲起。Pandas 主要有两种类型的数据结构,分别是 Series 和 DataFrame。这两种数据结构像两个可塑性极强的容器,能把遇到的各类数据都装进去,并按照容器的规则对数据进行高效处理。
为了便于理解,这里拿 Excel 表格来做类比,如表 2-1 Excel 类比样例表所示。
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 李雷 | 80 | 100 | 92 |
| 韩梅梅 | 98 | 91 | 90 |
| 阿粥 | 90 | 99 | 90 |
| Series 可以看作表中的某一列,这里的语文、数学、英语成绩对应的列都是一个 Series。DataFrame 则是整张数据表,由多列构成。Pandas 的几乎所有操作都是基于这些列和表进行的。下面分别认识一下 Series 和 DataFrame。 |
Series 和 DataFrame
1. 表格的三要素
Series 和 DataFrame 的存在是为了更有效率地容纳和处理数据。实际应用中,我们遇到的大部分数据是以表格形式存在的,而在处理的时候往往以列的方式来进行。
在介绍如何创建数据之前,先明确表格的基本要素,能够帮助我们更好地理解 Series 和 DataFrame 的特征与原理,知其然并知其所以然,更快地抓住重点。
想象一下,现在有一张数据表,我们需要知道哪些基本信息才能随心所欲地操作它?
1)想要自由地操作任意一列数据,首先要知道每一列数据叫什么,即列名。
2)知道数据的总行数及每一行对应的序号也很重要,毕竟处理 10 条数据与处理 100 万条数据需要的资源和工具是不一样的。
3)知道表格里的每个值具体是多少,这对于我们的统计分析结果来说至关重要。
总结一下,表格的三要素如下。
- 列名(column):对应着列名,指定操作哪列数据。
- 索引(index):代表索引,告诉我们有多少行数据,索引默认从 0 开始。
- 值(value):指代具体的数据值。
这 3 个基本要素贯穿 Pandas 数据分析的始终,作用是让我们更加灵活地处理和分析数据。
接下来我们动手在 Pandas 中尝试创建数据。
2. 创建 DataFrame 和 Series
如果想在 Pandas 中创建一张如表 2- 2 所示的表,应该如何操作?
表 2-2 创建表样例
| 工资 | 绩效分 | 备注 | |
|---|---|---|---|
| 阿粥 | 15000 | 95 | 优秀 |
| 老六 | 7000 | 59 | 不及格 |
| 老王 | 12000 | 82 | 良好 |
| 老黄 | 23000 | 100 | 最佳 |
Pandas 操作的第一步一定是导入库,命令为:import pandas as pd。 |
创建 DataFrame 最常用的方式是字典+列表,语句很简单,先用花括号{}创建一个字典,然后在其中依次输入每一列的列名及其对应的列值(此处一定要用列表)。这里对应关系重要,列的顺序并不重要。代码示例如下:
import pandas as pd
df1 = pd.DataFrame ({'工资':[15000,7000,12000,23000],'绩效分':[95,59,82,100],'备注':['优秀','不及格','良好','最佳']}, index=['阿粥','老六','老王','老龚'])
print(df1)
# 运行结果如下:
>>>
工资 绩效分 备注
阿粥 15000 95 优秀
老六 7000 59 不及格
老王 12000 82 良好
老龚 23000 100 最佳
上面代码的结果对应到 Excel 表格中,如图 2- 1 所示。值得注意的是,如果我们在创建时不指定 index 参数,系统会自动生成从 0 开始的索引。

图 2-1 表格三要素样例
还可以通过改变索引、列名和值来控制数据,这和前文讲的表格三要素——列名、索引、值是对应的。
对于 Series 的创建,在创建好 DataFrame 之后选择对应的列即可。在上述实例中,选择刚创建好的 df1 中的工资列作为新的 Series:
# 把 df1 里的工资列作为新的 Series 创建
s1 = df1['工资']
# 查看 s1 的类型
print(type(s1))
s1
# 运行结果如下:
>>>
<class 'pandas.core.series.Series'>
阿粥 15000
老六 7000
老王 12000
老龚 23000
Name: 工资, dtype: int 64
也可以通过指定值和索引的方式来单独创建一列:
s1 = pd.Series ([1,2,3,4,5,6],index = ['A', 'B', 'C', 'D', 'E', 'F'])
s1
# 运行结果如下:
>>>
A 1
B 2
C 3
D 4
E 5
F 6
dtype: int64
DataFrame 和 Series 的创建非常便捷,不过在实际运用中,单独创建数据的场景较少,更多是直接读取现有数据源。
2.2 数据读取和存储
Excel 文件的读取
1. 文件路径的切换
要读取某一个文件中的数据,必须先告诉 Python 这个文件所在的位置,即输入文件路径。
现有一个名为 data1 的 Excel 文件,存放在如图 2- 2 所示的位置。
图 2-2 样例文件路径位置
通过导入 os 系统模块,把 Python 切换到这个文件路径下:
import os
os.chdir(r'C:\本书配套资料\第2章 Pandas 快速入门')
os.chdir() 是实现系统文件路径切换的方法,可在其括号中输入我们从系统中复制的文件地址。
需要注意的是,路径前面加了一个 r。文件路径一般都包含斜杠,而斜杠在 Python 中会有其他含义(如转义),在路径前加 r 相当于告诉 Python 路径里的内容没有其他意思,从而保证路径被程序完整、准确地理解。
2. readexcel() 的用法
切换完路径之后,用 Pandas 的 pd.read_excel('具体文件名')(这里为 data1.xlsx)来读取 Excel 文件:
data1 = pd.read_excel('data1.xlsx')
data 1
运行结果如下:
| 姓名 | 语文 | 数学 | 英语 | |
|---|---|---|---|---|
| 0 | 小明 | 80 | 90 | 95 |
| 1 | 小王 | 90 | 100 | 66 |
| 2 | 小张 | 100 | 68 | 67 |
上面只赋予 Excel 名称的读取方式,默认打开的是第一个工作表(sheet)。当一个 Excel 文件包含多个工作表时,通过指定具体 sheet_name 的方式实现更精准的读取:
data1 = pd.read_excel('data1.xlsx', sheet_name = 'Sheet1')
data1
读取结果如下:
| 姓名 | 语文 | 数学 | 英语 | |
|---|---|---|---|---|
| 0 | 小明 | 80 | 90 | 95 |
| 1 | 小王 | 90 | 100 | 66 |
| 2 | 小张 | 100 | 68 | 67 |
3. header 和 names
data1.xlsx 中 sheet1 的数据源如表 2- 3 所示
表 2- 3 data1.xlsx 中 sheet1 的数据源
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 小明 | 80 | 90 | 95 |
| 小王 | 90 | 100 | 66 |
| 小张 | 100 | 68 | 67 |
Pandas 在读取的时候很智能地把第一行当作了表头来处理,数据则从第二行开始。
假如我们遇到了 sheet 2 中的数据,当时在 Excel 文件中只保存了数据,而没有保存表头,如表 2- 4 所示。
表 2-4 data 1. xlsx 中 sheet 2 的数据源
| 小明 | 80 | 90 | 95 |
|---|---|---|---|
| 小王 | 90 | 100 | 66 |
| 小张 | 100 | 68 | 67 |
如果用 Pandas 直接读取,默认将第一行当作表头的规则就显得不那么智能了,读取和展示结果如图 2- 3 所示。
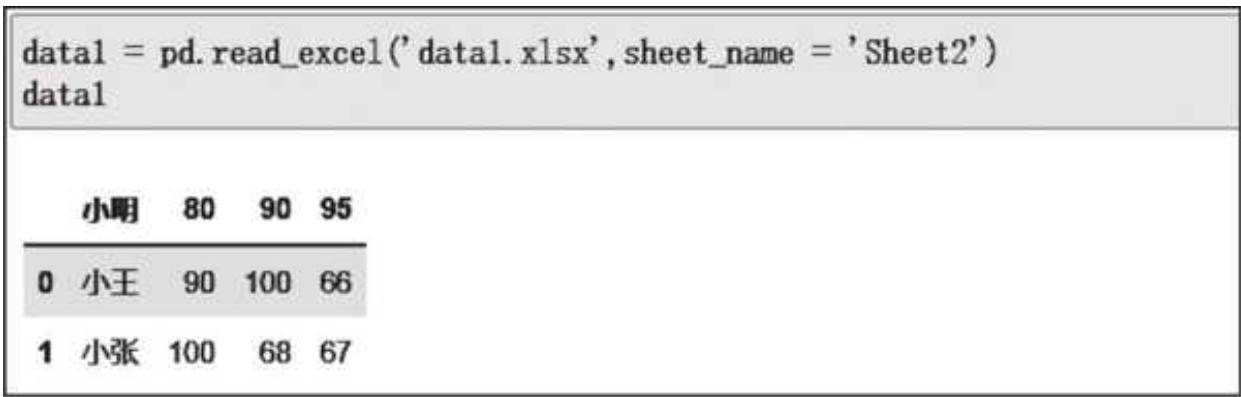
图 2-3 读取没有表头的数据
这个时候可以把 header 参数设置成 None,来告诉 Pandas 源数据中没有表头,效果如图 2- 4 所示。
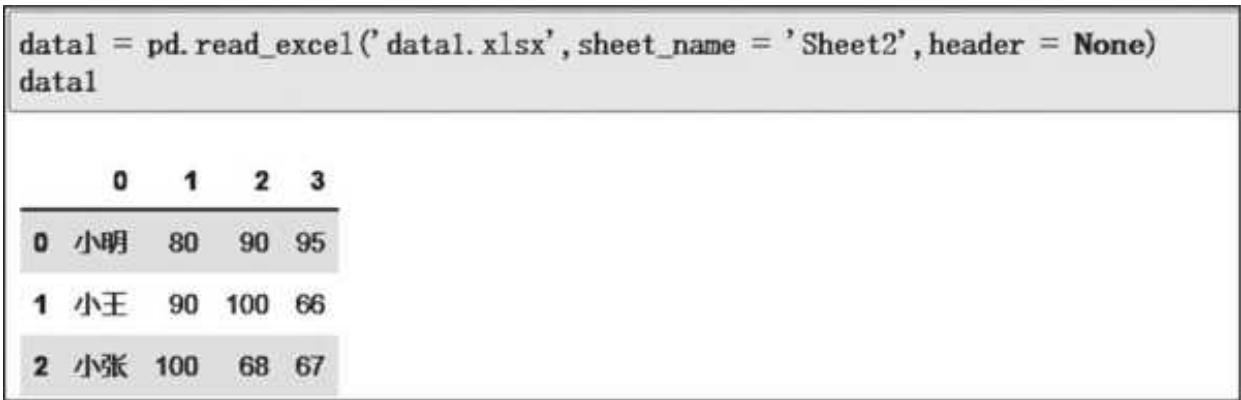
图 2-4 设置 header 读取无表头数据
如果将 header 设置成 None,默认的表头是从 0~3 的几个数字,很不美观。我们可以在读取的时候通过 names 参数,把表头设置成我们期望的内容,如图 2- 5 所示。

图 2-5 读取时设置表头
当然,header 除了设置成 None,还可以设置成数字,代表在读取时把第几行数据作为表头。假如我们想要把 Sheet 1 中的小明所在的第二行作为表头,只需把 header 设置成 1(Python 中计数从 0 开始)即可,如图 2- 6 所示。
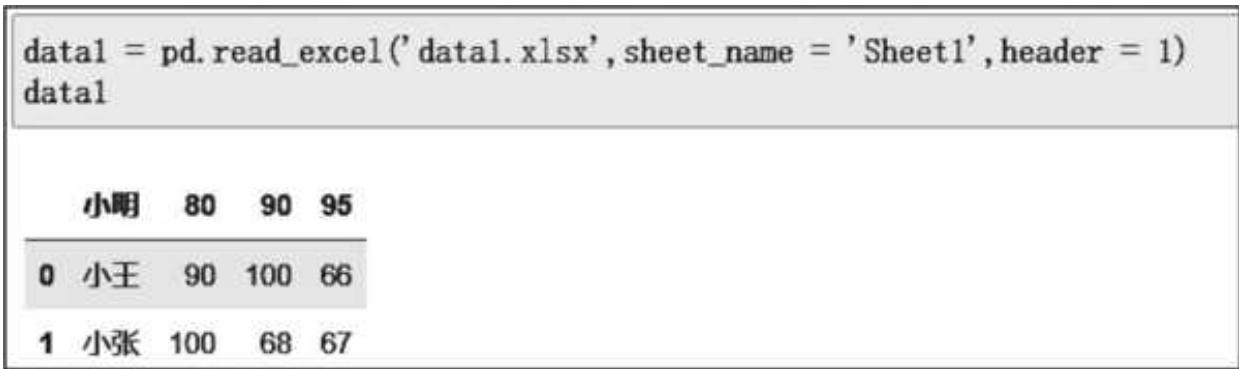
图 2-6 用 header 指定表头
这样一来,小明对应的数据行就成了表头。
4. 其他参数
除了默认或指定 Sheet 读取、设置数据表头,Pandas 读取数据还有很多灵活操作的参数,例如:
index_col指定索引列;usecols指定读取部分列;nrows指定读取部分行;prefix给表头设置前缀;dtype和字典结合,读取时为每一列数据设置格式。
参数非常丰富,不过我们的 Pandas 学习之旅有一个重要原则是“抓大放小”,为了避免陷入细节的泥沼无法自拔,比较琐碎且不常用的参数不展开介绍,只是告诉大家有相关的参数,读者在需要的时候可以自行查阅。
CSV 文件的读取
Pandas 读取 CSV 文件用的是 pd.read_csv('具体文件名') 方法。不过 Pandas 在 Excel 和 CSV 文件的读取上有很高的相似性,上一小节讲的大多数规则和参数也适用于 CSV 文件的读取。
需要注意的是,在实际操作中 Excel 文件的读取一般不会有什么问题,但由于中文路径和编码等问题,CSV 的读取是报错的高发区。接下来,重点看看 CSV 文件的 3 个注意点以及如何避免错误。
1. 中文路径
当文件路径是中文时,如果直接读取,在一些 Python 版本里会报错。因为 Python 默认的读取引擎是 C 语言,它在处理中文时容易出问题。这个时候把读取引擎参数 engine 设置为 Python 就可以解决:
data = pd.read_csv('data1.csv',engine = 'python')
2. 编码设置
CSV 文件有不同的编码形式,utf-8 和 gbk 是两种最常见的编码形式。类似于一把钥匙对一个锁,如果文件是 gbk 编码,那么用 utf-8 就打不开。Pandas 在读取文件时默认采用 utf-8 的编码格式。
用默认的方式打开我们 CSV 的案例数据,可能会报错,如图 2- 7 所示。
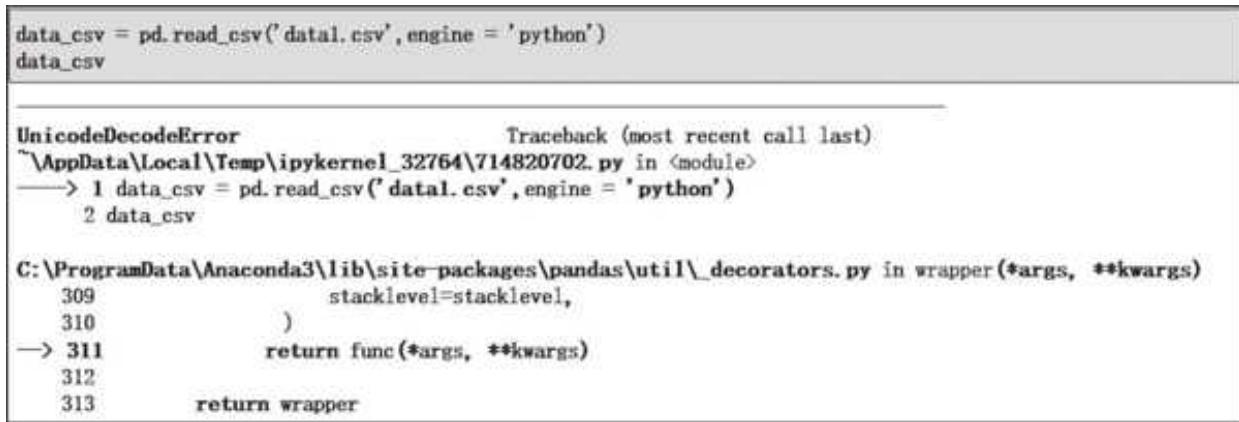
图 2-7 读取数据报错
通过设置 encoding 参数来指定文件编码格式,在读取 gbk 和其他编码文件的时候设置成对应编码即可解决问题:
data_csv = pd.read_csv('data1.csv', engine = 'python', encoding = 'gbk')
data_csv
结果如下:
| 姓名 | 语文 | 数学 | 英语 | |
|---|---|---|---|---|
| 0 | 小明 | 80 | 90 | 95 |
| 1 | 小王 | 90 | 100 | 66 |
| 2 | 小张 | 100 | 68 | 67 |
3. 分隔符的处理
pd.read_csv() 方法在读取 CSV 文件时,默认是以逗号作为分隔符来打开的(这也是绝大部分 CSV 文件使用的分隔方式),但如果文件在存储时使用的是其他分隔符,那么就需要在读取时设置好 sep 参数:
# 这个文件使用的 '\t' 分隔符,因此需要设定
data_csv = pd.read_csv('data_sep_t.csv', sep = '\t')
以上代码打开的文件是以 \t 为分隔符的。
其他文件类型的读取
1. TXT 文件的读取
Pandas 读取 TXT 文件用的是 pd.read_table() 方法,需要在读取时输入 TXT 文件的名称和分隔符(这里必须指定):
# 假设这里的 TXT 文件使用的是 '\t' 分隔符
data.txt = pd.read_table ('具体文件名', sep = '\t')
2. JSON 文件的读取
JSON 文件是一种类字典形式的文件,在读取时用 pd.read_json() 方法。
Excel 和 CSV 是两种最为常见的文件类型,其他文件类型的读取这里只简单提及,因为它们只有打开的方法有所差异,大部分参数对它们也是通用的。
存储数据
当对数据进行读取、处理和分析之后,往往需要把结果数据存储起来。
在 Pandas 中存储数据非常方便,用的是 data.to_ XXX() 方法(XXX 是你期望存储的文件类型):
data.to_excel('data_excel.xlsx')
data.to_csv('data_csv.csv')
默认的存储方式会把索引也作为一列存储,如果不希望存储索引,设置 index=False 即可:
data.to_excel('xxx.xlsx',index = False)
2.3 快速认识数据
用 Pandas 读取数据之后,对数据做一个快速的全局扫描以掌握关键信息,会让后续的处理和分析工作更有的放矢。
这里以流量案例数据为例,学习查看 N 行、数据格式概览以及基础统计数据等常用的扫描数据操作。案例数据是一份结构清晰的流量数据,包括流量来源、来源明细、访客数、支付转化率和客单价 5 个字段。
查看数据
很多时候,我们想要查看数据的某个片段以确认读取或者处理之后的数据是否符合预期,应该如何操作?
用 df.head() 可以查看前 5 行。与之对应,用 df.tail() 可以查看数据尾部的 5 行数据。这两个方法都可以传入一个数值来自定义查看的行数,例如 df.head(6) 表示查看前 6 行数据,df.tail(4) 表示查看后 4 行数据,结果如图 2- 8 所示。
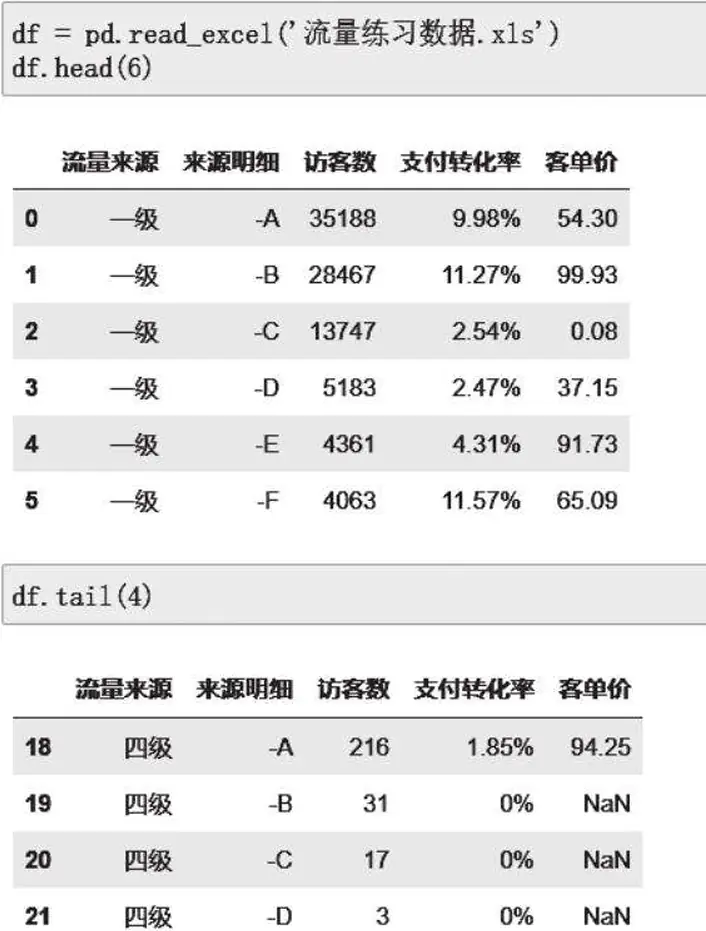
图2-8 查看前6行和后4行数据
查看数据类型
数据的行数、列数,每一列是否有空缺值,各列的数据类型分别是什么,这些信息对于数据分析师来说至关重要。用 df.info() 方法可以一步摸清各列数据的类型及缺失情况,如图 2- 9 所示。

图 2-9 查看数据类型信息
上面的信息全面描述了数据集的行列数、对应名称、每一列的数据类型、有多少条非空数据以及数据集的大小,查看起来非常方便。
统计信息概览
在查看了数据样例,了解数据类型和空缺值情况后,我们经常还会对数据某些列做统计层面的分析。这项工作用 Pandas 依然可以轻松完成,它的 df.describe() 方法可以快速计算数值型数据的关键统计指标,如平均数、分位数、标准差等。
df.describe()
运行结果如下:
| 访客数 | 客单价 | |
|---|---|---|
| count | 22.00000 | 19.000000 |
| mean | 8498.00000 | 72.860000 |
| std | 12015.23756 | 26.888032 |
| min | 3.00000 | 0.080000 |
| 25% | 1824.50000 | 59.695000 |
| 50% | 2082.50000 | 82.970000 |
| 75% | 11606.00000 | 91.820000 |
| max | 39048.00000 | 104.570000 |
| 但是,我们本来有 5 列数据,为什么返回结果只有访客数和客单价这两列?那是因为这个操作只针对数值型的列,非数值型的列本身无法得出完整的统计信息。其中,count 统计每一列有多少个非空数值,mean、std、min、max 对应的分别是该列的均值、标准差、最小值和最大值,25%、50%、75%对应的则是具体分位数大小。 |
2.4 数据处理初体验
对数据整体有了初步了解后,接下来我们采用数据分析四大法宝——增、删、选、改的逻辑来梳理数据的基本处理方式。这四个字涵盖了我们会遇到的绝大部分 Pandas 操作。不过,为了帮助读者快速理解这四大法宝,本节中的案例都采用了极简的风格。
需要强调的是,使用 Pandas 时,要尽量避免用行或者 Excel 操作单元格的思维来处理数据,要逐渐养成一种列向思维,每一列都同宗同源,处理起来简洁高效。
增
最常见的增就是在原始数据上增加新的列。增加列用的是 df['新列名'] = 新列值 的方式,在原数据基础上赋值即可:
df['新增的列'] = range (1,len(df) + 1)
df.head ()
预览结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | 新增的列 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | -A | 35188 | 9.98% | 54.30 | 1 |
| 1 | 一级 | -B | 28467 | 11.27% | 99.93 | 2 |
| 2 | 一级 | -C | 13747 | 2.54% | 0.08 | 3 |
| 3 | 一级 | -D | 5183 | 2.47% | 37.15 | 4 |
| 4 | 一级 | -E | 4361 | 4.31% | 91.73 | 5 |
删
如果想要删除一些列,可以用 drop() 方法指定要删除的列。参数 axis=1 表示针对列的操作,inplace=true,则直接在源数据上进行修改,否则源数据会保持原样。
df.drop('新增的列', axis = 1, inplace = True)
df.head()
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | |
|---|---|---|---|---|---|
| 0 | 一级 | -A | 35188 | 9.98% | 54.30 |
| 1 | 一级 | -B | 28467 | 11.27% | 99.93 |
| 2 | 一级 | -C | 13747 | 2.54% | 0.08 |
| 3 | 一级 | -D | 5183 | 2.47% | 37.15 |
| 4 | 一级 | -E | 4361 | 4.31% | 91.73 |
选
在 Pandas 操作中,更多的情况是从原始数据中选择我们需要的数据。如果想要选取某一列数据,应该怎么操作?用 df['列名'] 即可:
df['客单价']
代码前 5 行结果如下:
0 54.30
1 99.93
2 0.08
3 37.15
4 91.73
如果要选取多列呢?需要用括号内的列表来传递,即 df['第一列','第二列','第三列'...]]:
df['流量来源','访客数','支付转化率']]
前 5 行结果如下:
流量来源 访客数 支付转化率
0 一级 35188 9.98%
1 一级 28467 11.27%
2 一级 13747 2.54%
3 一级 5183 2.47%
4 一级 4361 4.31%
改
数据的更改和新增操作很相近,用 df['旧列名'] =某个值或者某列值(列值的数量必须和原数据行数相等),就完成了对原列数值的修改。
本节用极为简洁的方式介绍了 Pandas 中的增删选改操作。增删选改是一个大筐,几乎所有的数据操作都可以往里装。针对特定应用场景行列的筛选、修改等复杂操作将在后续章节中结合案例展开讲解。
2.5 常用数据类型及操作
字符串
字符串类型是最常用的格式之一,Pandas 中字符串的操作和 Python 原生字符串操作几乎一模一样,唯一不同的是需要在操作前加上“. str”。
值得注意的是,在上一节我们用 df.info() 查看数据类型时,非数值型的列都显示的是 object 类型。object 类型和 str 类型在深层机制上的区别这里就不展开了,在常规的实际应用中,我们可以暂且这样理解:object 对应的就是 str 类型、int 64 对应的就是 int 类型,float 64 对应的就是 float 类型。
在案例数据中,我们发现来源明细那一列,可能是因为系统导出的历史遗留问题,每一个字符串前面都有一个“- ”符号,既不美观又无用处,所以把它拿掉:
df['来源明细']. str.replace ('- ',')
运行结果如下:
0 A
1 B
2 C
3 D
4 E
5 F
6 G
7 H
8 I
9 J
10 K
需要注意的是,上面的操作只是显示了处理完之后的结果,并未更改源数据,要更改源数据,必须用清洗之后的列替换掉原来的列:
df['来源明细'] = df['来源明细'].str.replace('-','') df.head()
显示结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | |
|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 9.98% | 54.30 |
| 1 | 一级 | B | 28467 | 11.27% | 99.93 |
| 2 | 一级 | C | 13747 | 2.54% | 0.08 |
| 3 | 一级 | D | 5183 | 2.47% | 37.15 |
| 4 | 一级 | E | 4361 | 4.31% | 91.73 |
2.5 常用数据类型及操作
字符串
字符串类型是最常用的格式之一,Pandas 中字符串的操作和 Python 原生字符串操作几乎一模一样,唯一不同的是需要在操作前加上“. str”。
值得注意的是,在上一节我们用 df.info() 查看数据类型时,非数值型的列都显示的是 object 类型。object 类型和 str 类型在深层机制上的区别这里就不展开了,在常规的实际应用中,我们可以暂且这样理解:object 对应的就是 str 类型、int 64 对应的就是 int 类型,float 64 对应的就是 float 类型。
在案例数据中,我们发现来源明细那一列,可能是因为系统导出的历史遗留问题,每一个字符串前面都有一个“- ”符号,既不美观又无用处,所以把它拿掉:
df['来源明细'].str.replace ('-','')
运行结果如下:
0 A
1 B
2 C
3 D
4 E
5 F
6 G
7 H
8 I
9 J
10 K
需要注意的是,上面的操作只是显示了处理完之后的结果,并未更改源数据,要更改源数据,必须用清洗之后的列替换掉原来的列:
df['来源明细'] = df['来源明细'].str.replace ('-','') df.head ()
显示结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | |
|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 9.98% | 54.30 |
| 1 | 一级 | B | 28467 | 11.27% | 99.93 |
| 2 | 一级 | C | 13747 | 2.54% | 0.08 |
| 3 | 一级 | D | 5183 | 2.47% | 37.15 |
| 4 | 一级 | E | 4361 | 4.31% | 91.73 |
数值型
对于数值型数据,常见的操作是计算,分为与单个值的运算、长度相等列的运算。以上述案例数据为例,源数据访客数我们是知道的,现在想把所有渠道的访客都加上 10000,如何操作?
df['访客数']+10000
Jupyter Notebook 自动反馈如下结果:
0 45188
1 38467
2 23747
3 15183
4 14361
5 14063
只需要选中访客数所在列,然后加上 10000 即可,Pandas 自动将 10000 和每一行数值相加。针对单个值的其他运算(减、乘、除)也是如此。
列之间的运算语句也非常简洁。源数据包含访客数、转化率和客单价,而实际工作中我们对每个渠道贡献的销售额(销售额
对应操作语句为 df['销售额' = df['访客数']*df['转化率']*df['客单价'],如图 2- 10 所示。
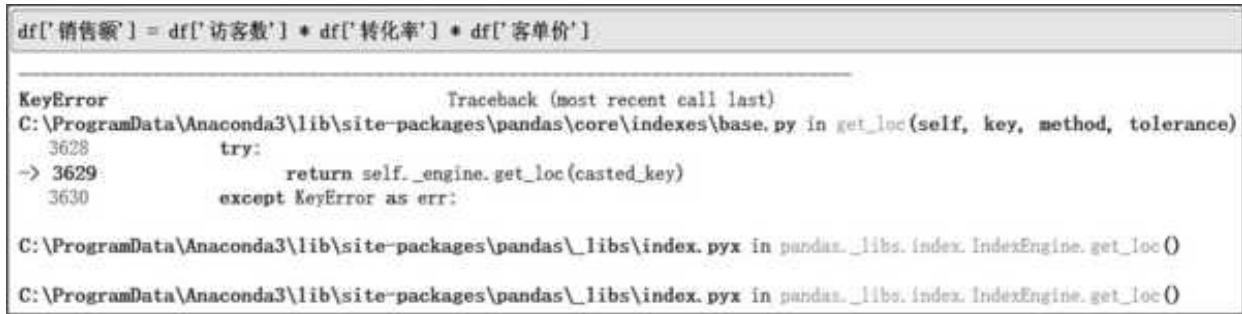
图 2-10 直接计算销售额报错反馈
为什么会报错?报错是数值型数据和非数值型数据相互计算导致的。Pandas 把带%符号的转化率识别成字符串类型,我们需要先拿掉%符号,再将这一列转化为浮点型数据:
df['支付转化率'] = df['支付转化率'].str.replace('%','').astype(float)
df.head ()
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | |
|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 9.98 | 54.30 |
| 1 | 一级 | B | 28467 | 11.27 | 99.93 |
| 2 | 一级 | C | 13747 | 2.54 | 0.08 |
| 3 | 一级 | D | 5183 | 2.47 | 37.15 |
| 4 | 一级 | E | 4361 | 4.31 | 91.73 |
| 需要注意的是,这样操作把 9.98% 变成了 9.98,所以我们还需要将支付转化率除以 100,以还原百分数的真实数值: |
df['支付转化率'] = df['支付转化率'] / 100
df.head()
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | |
|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 0.0998 | 54.30 |
| 1 | 一级 | B | 28467 | 0.1127 | 99.93 |
| 2 | 一级 | C | 13747 | 0.0254 | 0.08 |
| 3 | 一级 | D | 5183 | 0.0247 | 37.15 |
| 4 | 一级 | E | 4361 | 0.0431 | 91.73 |
| 然后,再用 3 个指标相乘计算销售额: |
df['销售额'] = df['访客数'] * df['支付转化率'] * df['客单价']
df.head()
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | 销售额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 0.0998 | 54.30 | 190688.698320 |
| 1 | 一级 | B | 28467 | 0.1127 | 99.93 | 320598.513837 |
| 2 | 一级 | C | 13747 | 0.0254 | 0.08 | 27.933904 |
| 3 | 一级 | D | 5183 | 0.0247 | 37.15 | 4755.946715 |
| 4 | 一级 | E | 4361 | 0.0431 | 91.73 | 17241.488243 |
时间类型
Pandas 中与时间序列相关的内容非常复杂,这里先对日常用到的基础时间格式进行讲解,对时间序列感兴趣的读者可以自行查阅相关资料,深入了解。
以上述案例数据为例,这些渠道数据是在 2022 年 12 月 24 日提取的,后面可能涉及其他日期的渠道数据,所以需要加一列时间予以区分。在 Excel 中常用的时间格式是 2022- 12- 24 或者 2022/12/24,我们用 Pandas 来实现一下:
df['日期列'] = '2022-12-24'
df.head()
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 | 销售额 | 日期列 | |
|---|---|---|---|---|---|---|---|
| 0 | 一级 | A | 35188 | 0.0998 | 54.30 | 190688.698320 | 2022-12-24 |
| 1 | 一级 | B | 28467 | 0.1127 | 99.93 | 320598.513837 | 2022-12-24 |
| 2 | 一级 | C | 13747 | 0.0254 | 0.08 | 27.933904 | 2022-12-24 |
| 3 | 一级 | D | 5183 | 0.0247 | 37.15 | 4755.946715 | 2022-12-24 |
| 4 | 一级 | E | 4361 | 0.0431 | 91.73 | 17241.688243 | 2022-12-24 |
在实际业务中,有时 Pandas 会把文件中日期格式的字段读取为字符串格式,这里我们先将字符串'2022- 12- 24 赋值给新增的日期列,然后用 to_datetime()方法将字符串类型转换成时间格式:
df['日期'] = pd.to_datetime(df['日期列'])
df['日期'].head()
# 运行结果如下:
>>>
0 2022-12-24
1 2022-12-24
2 2022-12-24
3 2022-12-24
4 2022-12-24
Name: 日期, dtype: datetime 64[ns]
转换成时间格式(这里是 datetime 64)之后,我们可以用处理时间的思路高效处理这些数据。比如,我现在想知道提取数据这一天离年末还有多少天('2022- 12- 31'),直接做减法(该方法既接受时间格式的字符串序列,也接受单个字符串):
pd.to_datetime ('2022-12-31') - df['日期']`
# 运行结果前几行如下:
>>>
0 7 days
1 7 days
2 7 days
3 7 days
4 7 days
2.6 本章小结
本章用极简的方式介绍了 Pandas 数据结构和常用操作。最后,我们一起来回顾一下本章的重点内容。
1)认识了 Pandas 核心的数据结构 DataFrame 和 Series,也知道了最关键的三要素以及三要素为什么存在。
2)学习如何读取、存储数据,以及读取数据中可能遇到的问题。
3)拿到数据之后,知道怎样快速查看数据的关键信息。
4)对数据有了基础认知,开始熟悉最简单的增删选改操作。(接下来的章节会提取其中高频操作并结合案例展开讲解。)
5)在了解基础操作之后,和 Pandas 中常用的基础数据类型打了个招呼。
每个内容都先从还原实践流程的角度出发,带大家认识这些模块,然后通过案例实践检验、巩固、沉淀相关操作与分析思路。