第3章 玩转索引
3.1 索引概述
不少读者可能对于“到底什么是索引?”“索引有哪些类型?”这几个问题仍有疑惑,本节将一一解答。
到底什么是索引
1. 为什么需要索引
上一章提到过,几乎所有的数据操作都在增、删、选、改的范围之内进行。
拿到一份数据后,我们可能想要增加某些列,删除一些冗余数据,根据需求选择某一部分数据,或者改变和调整部分数据。所有这些操作都是针对原始数据中的特定部分进行的。也就是说,数据处理的第一步是找到想要调整的对应部分,然后才是进行相关的操作。而 Pandas 索引的存在,就是为了帮助我们从原始数据中快速、灵活地选取所需要的部分,更好地满足数据处理的第一步。
2. 索引的概念
索引的概念可以用快递的编号来类比。如果没有编号,附近所有人的快递都杂乱地堆在快递站点,当我们想要取一个快递时,需要自己一个个查看,非常耗时费力,还不一定找得到。
正常情况下,小区的快递站点会有很多货架,每个货架都有对应的货架号。货架又会分成不同的层,每一层对应着层号。每一层存放着不同的快递包裹,包裹则有一个包裹号以便区分。我们取快递时,按照短信提示的“站点位置—货架号—层号—包裹号”来按“号”索骥,可以很快取到自己的包裹。
Pandas 索引本质上就相当于快递站点的“站点位置—货架号—层号—包裹号”。通过索引,我们快速定位并选择需要的数据。
两种索引类型
Pandas 索引操作有以下两种常见的类型。
-
基于位置(数字)的索引:通过指定要选哪几行和哪几列来筛选出目标数据。
-
基于名称(标签)的索引:既可以指定列具体的名称,又可以加上复杂的条件判断,筛选更加灵活。
在实际运用中,第一种索引只是偶尔会用到,应用范围远不如第二种广泛,只需要粗略了解一下,以方便我们阅读相关场景的代码。第二种索引则是我们学习的重点,因为它是后面进行数据清洗和分析的基石。
3.2 基于位置(数字)的索引
对于索引的练习,我们会用几个具体的案例场景来贯穿。首先通过以下代码导入案例数据集,预览结果如表 3-1 所示。
# 导入案例数据集
import pandas as pd
import os
# 记得切换自己的文件目录
os.chdir(r'C:\本书配套资料\第3章 玩转索引')
df = pd.read_excel('流量练习数据.xls')
# 和第 2 章中一样,把转化率从字符串变成可以处理的小数
df['支付转化率'] = df['支付转化率'].str.replace ('', '').astype(float)
df['支付转化率'] = df['支付转化率'] / 100
表 3-1 案例流量表预览
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 |
|---|---|---|---|---|
| 一级 | -A | 35188 | 0.0998 | 54.3 |
| 一级 | -B | 28467 | 0.1127 | 99.93 |
| 一级 | -C | 13747 | 0.0234 | 0.08 |
| 一级 | -D | 5183 | 0.0247 | 37.15 |
| 一级 | -E | 4361 | 0.0431 | 91.73 |
这里用的是与 2.3 节中一样的案例数据集,记录着不同流量来源、来源明细、访客数、支付转化率和客单价。案例数据集虽然简短,但有足够的代表性。
基于位置(数字)索引的操作用的是 iloc,其具体用法和参数如下。
df.iloc[行参数,列参数]
- 第一个位置是行参数,输入我们想要选取哪几行的位置参数;
- 第二个位置是列参数,输入我们想要选取哪几列的位置参数;
- Python 中,索引是从 0 开始的,含首不含尾。需要根据实际情况填入对应的行参数和列参数。
场景一:行选取
目标:选择“流量来源"等于“一级"的所有行。
思路:数一数原始数据,“流量来源"等于“一级"的渠道包含第 1~13 行,对应行索引是 0~12(从 0 开始计数),但 Python 切片默认是含首不含尾的,因此要想选取 0~12 的索引行,需要输入“0:13”。对于列,如果要选取所有的列,则可以只输入冒号“:”。
df. iloc[0:13,:]
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 |
|---|---|---|---|---|
| 0 一级 | -A | 35188 | 0.0998 | 54.30 |
| 1 一级 | -B | 28467 | 0.1127 | 99.93 |
| 2 一级 | -C | 13747 | 0.0254 | 0.08 |
| 3 一级 | -D | 5183 | 0.0247 | 37.15 |
| 4 一级 | -E | 4361 | 0.0431 | 91.73 |
| 5 一级 | -F | 4063 | 0.1157 | 65.09 |
| 6 一级 | -G | 2122 | 0.1027 | 86.45 |
| 7 一级 | -H | 2041 | 0.0706 | 44.07 |
| 8 一级 | -I | 1991 | 0.1652 | 104.57 |
| 9 一级 | -J | 1981 | 0.0575 | 75.93 |
| 10 一级 | -K | 1958 | 0.1471 | 85.03 |
| 11 一级 | -L | 1780 | 0.1315 | 98.87 |
| 12 一级 | -M | 1447 | 0.0104 | 80.07 |
场景二:列选取
目标:筛选出所有渠道的流量来源和客单价。
思路:所有流量渠道,也就是所有行,因此在行参数的位置输入“:”;再看列,流量来源是第 1 列,客单价是第 5 列,对应的列索引分别是 0 和 4:
df.iloc[:,[0,4]]
运行结果如下:
| 流量来源 | 客单价 | |
|---|---|---|
| 0 | 一级 | 54.30 |
| 1 | 一级 | 99.93 |
| 2 | 一级 | 0.08 |
| 3 | 一级 | 37.15 |
| 4 | 一级 | 91.73 |
| ... | ... | ... |
| 17 | 三级 | 82.97 |
| 18 | 四级 | 94.25 |
| 19 | 四级 | NaN |
| 20 | 四级 | NaN |
| 21 | 四级 | NaN |
值得注意的是:如果要跨列选取,则必须先把位置参数构造成列表形式,这里就是[0,4];如果要连续选取,则无须构造成列表,直接输入“0:5”(选取索引为 0 到 4 的列)即可。
场景三:行列交叉选取
目标:看一看二级和三级流量来源、来源明细、对应的访客数和支付转化率。
思路:先看行,二级和三级渠道对应的行索引是13:17,再次强调索引含首不含尾的原则,我们需要传入的行参数是13:18,再看列,我们需要流量来源、来源明细、访客数和支付转化率,也就是前 4 列,因此传入列参数0:4。
df.iloc[13:18,0:4]
运行效果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | |
|---|---|---|---|---|
| 13 | 二级 | -A | 39048 | 0.1160 |
| 14 | 二级 | -B | 3316 | 0.0709 |
| 15 | 二级 | -C | 2043 | 0.0504 |
| 16 | 三级 | -A | 23140 | 0.0969 |
| 17 | 三级 | -B | 14813 | 0.2014 |
3.3 基于名称(标签)的索引
为了与基于位置的索引进行横向对比,我们先沿用上面的 3 个场景,然后在此基础上拓展出场景四。
基于 loc 的行选取
目标:选择“流量来源"等于“一级"的所有行。
思路:这次我们不用一个个数位置了,要筛选“流量来源"等于“一级"的所有行,只需做一个判断,判断“流量来源"这一列,哪些值等于“一级”。
首先,看看哪些行的“流量来源"等于“一级”:
df['流量来源'] == '一级'
运行结果如下:
0 True
1 True
2 True
3 True
4 True
17 False
18 False
19 False
20 False
21 False
Name:流量来源,dtype:bool
返回的结果由 True 和 False(布尔型)构成,在这个例子中分别代表结果等于一级和不等于一级。在 loc 中,我们可以把这一列判断得到的值传入行参数位置,Pandas 会默认返回结果为 True 的行(这里是索引从 0 到 12 的行),而丢掉结果为 False 的行:
df.loc[df['流量来源'] == '一级',::]
结果和 iloc 实现的一样:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 |
|---|---|---|---|---|
| 0 | -级 | -A | 35188 | 0.0998 |
| 1 | -级 | -B | 28467 | 0.1127 |
| 2 | -级 | -C | 13747 | 0.0254 |
| 3 | -级 | -D | 5183 | 0.0247 |
| 4 | -级 | -E | 4361 | 0.0431 |
| 5 | -级 | -F | 4063 | 0.1157 |
| 6 | -级 | -G | 2122 | 0.1027 |
| 7 | -级 | -H | 2041 | 0.0706 |
| 8 | -级 | -I | 1991 | 0.1652 |
| 9 | -级 | -J | 1981 | 0.0575 |
| 10 | -级 | -K | 1958 | 0.1471 |
| 11 | -级 | -L | 1780 | 0.1315 |
| 12 | -级 | -M | 1447 | 0.0104 |
基于 loc 的列选取
目标:筛选出所有渠道的流量来源和客单价。
思路:所有渠道对应所有行,我们在行参数位置直接输入“:”。要提取“流量来源”和“客单价”列,直接在列参数位置输入列名称,由于这里涉及两列,所以要用中括号将名称包起来(作为列表):
df.loc[:,'流量来源','客单价']
运行结果依然和 iloc 相同:
| 流量来源 | 客单价 | |
|---|---|---|
| 0 | 一级 | 54.30 |
| 1 | 一级 | 99.93 |
| 2 | 一级 | 0.08 |
| 3 | 一级 | 37.15 |
| 4 | 一级 | 91.73 |
| ... | ... | ... |
| 17 | 三级 | 82.97 |
| 18 | 四级 | 94.25 |
| 19 | 四级 | NaN |
| 20 | 四级 | NaN |
| 21 | 四级 | NaN |
基于 loc 的交叉选取
目标:看一看二级和三级流量来源、来源明细、对应的访客数和支付转化率。
思路:行提取用判断方法,列提取输入具体名称参数。
df.loc[df['流量来源':'.isin(['二级','三级']),['流量来源','来源明细','访客数','支付转化率']]
运行结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | |
|---|---|---|---|---|
| 13 | 二级 | -A | 39048 | 0.1160 |
| 14 | 二级 | -B | 3316 | 0.0709 |
| 15 | 二级 | -C | 2043 | 0.0504 |
| 16 | 三级 | -A | 23140 | 0.0969 |
| 17 | 三级 | -B | 14813 | 0.2014 |
这里顺便介绍一下,isin() 方法能够帮助我们快速判断源数据中某一列的值是否等于列表中的值。
在以上代码中,df[流量来源]isin([二级,'三级]) 判断的是“流量来源"这一列的值是否等于“二级"或者“三级”,如果等于就返回 True,否则返回 False。再把这个布尔型判断结果传入行参数,就能够得到流量来源为二级或者三级的渠道。
loc 的应用场景十分广泛,下面再来看一个接地气的场景。
在进入场景之前,我们先花 30 s 的时间捋一捋 Pandas 中列向求值的用法,具体操作如下:
df['访客数'].mean() # 计算均值
df['访客数'].std() # 计算标准差
df['访客数'].median() # 计算中位数
df['访客数'].max() # 计算最大值
df['访客数'].min() # 计算最小值
只需要加个尾巴,均值、标准差等统计数值就都出来了。了解完这个,下面正式进入场景四。
场景四:多条件索引
目标:对于流量渠道的数据,我们真正应该关注的是优质渠道。这里定义访客数、支付转化率、客单价都高于均值的渠道是优质渠道,我们的目标是找到这些渠道。
思路:优质渠道必须同时满足访客数高于均值、支付转化率高于均值、客单价高于均值这 3 个条件,这是解题的关键。
先看看这 3 项指标的均值各是多少:
print('访客数均值:',df['访客数'].mean())
print('支付转化率均值:',df['支付转化率'].mean())
print('客单价均值':,df['客单价'].mean())
# 运行结果如下:
>>>
访客数均值:8498.0
支付转化率均值:0.0754772727273
客单价均值:72.86
再判断各指标是否大于均值,整体如图 3- 1 所示
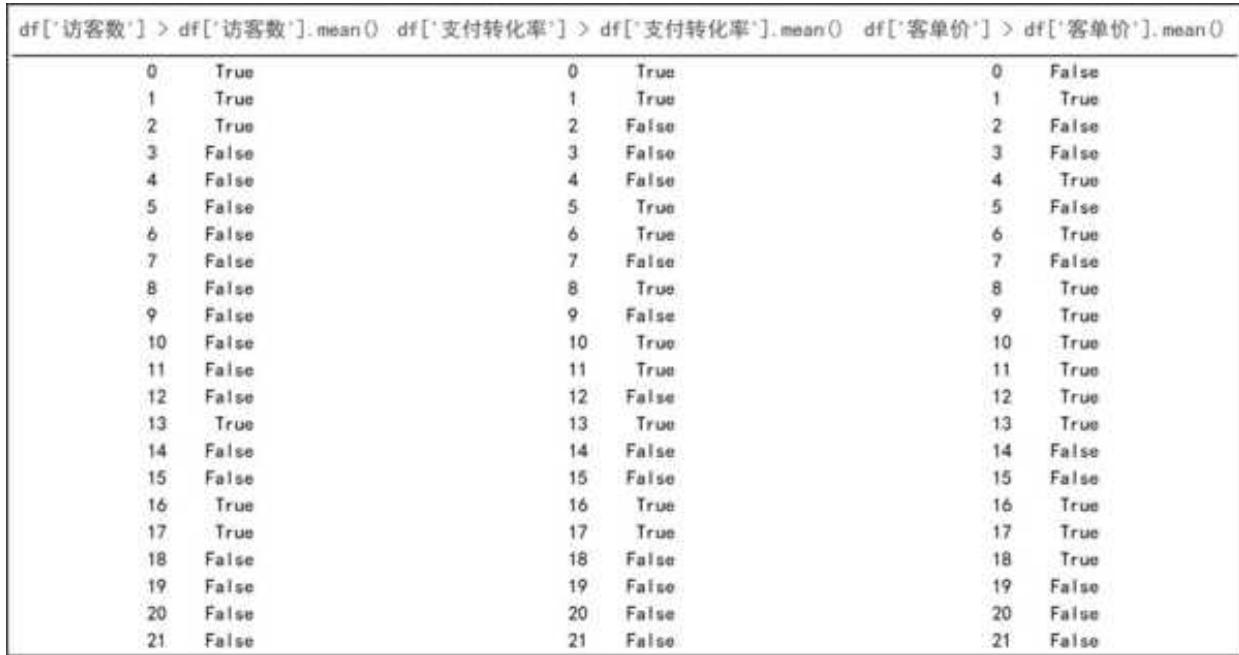
图 3-1 各指标是否大于均值的判断
这 3 个条件需要同时满足,因此它们之间是“且”的关系。在 Pandas 中,要表示同时满足,各条件之间要用“&”符号连接,每个条件最好用括号包裹起来。(如果是“或”的关系,即满足任意一个条件即可,则用“|”符号连接。)
(df['访客数']>df['访客数'].mean())&(df['支付转化率']>df['支付转化率'].mean())&(df['客单价'] > df['客单价'].mean())
# 运行结果如下:
>>>
0 False
1 True
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 True
14 False
15 False
16 True
17 True
18 False
19 False
20 False
21 False
dtype: bool
这样连接之后,返回 True 则表示渠道满足访客数、支付转化率、客单价都高于均值的条件,接下来我们只需要把对应的值传入行参数的位置。
df.loc[(df['访客数'] > df['访客数'].mean()) & (df['支付转化率'] > df['支付转化率'].mean()) & (df['客单价'] > df['客单价'].mean ()),:]
最终结果如下:
| 流量来源 | 来源明细 | 访客数 | 支付转化率 | 客单价 |
|---|---|---|---|---|
| 1 一级 | -B | 28467 | 0.1127 | 99.93 |
| 13 二级 | -A | 39048 | 0.1160 | 91.91 |
| 16 三级 | -A | 23140 | 0.0969 | 83.75 |
| 17 三级 | -B | 14813 | 0.2014 | 82.97 |
这样,我们就筛选出了 3 项关键指标都高于均值的优质渠道。
3.4 本章小结
在本章中,我们学习了两种索引方式:一是基于位置(数字)的索引,二是基于名称(标签)的索引。对于前者,我们只需理解其使用原理,以便于今后阅读相关的代码;而后者则是我们频繁使用的有力工具。
用好索引的关键在于,将我们要选取的行和列准确地映射到对应的行参数和列参数中去。只要多加练习,我们就能够使用 Pandas 随心所欲地选取自己想要的数据。