第4章 数据清洗四大核心操作
本章我们学习了 Pandas 数据清洗的核心操作,分别如下:
- 增:拓展数据维度。纵向合并用 concat(),横向连接用 merge(),也学习了 inner、left、right 和 outer 几种不同的横向连接方式。
- 删:dropna() 可以快速删掉缺失值,fillna() 则能够高效填补缺失值,重复值的处理用的是 duplicated()。
- 选:基于标签的 loc 索引是我们完成数据筛选的基本操作。sort_values() 能够对数据进行排序。
- 改:改变数据形态。df.T 转置是最简单的方式;分组用的是 groupby(),结合 agg(),分组聚合汇总变得十分灵活;cut() 则可以把数据切分成不同的组,并快速打上标签。
4.1 增:拓展数据维度
很多时候,我们获取到的源数据是多张数据表。在处理之前,需要先把相关的数据纵向合并或横向连接。
纵向合并
首先,导入我们的案例数据集。因为案例数据存放在同一个 Excel 工作簿的不同工作表(Sheet)下,所以需要指定 sheet_name 分别进行读取:
import pandas as pd
import os
os.chdir (r'C:\本书配套资料\第4章 数据清洗四大核心操作')
d1 = pd.read_excel('Pandas 数据清洗原始数据.xlsx', sheet_name = '一级流量')
d2 = pd.read_excel('Pandas 数据清洗原始数据.xlsx', sheet_name = '二级流量')
d3 = pd.read_excel('Pandas 数据清洗原始数据.xlsx', sheet_name = '三级流量')
print(d1.head(2))
print(d2.head(2))
print(d3.head(2))
运行结果如下:
d1.head(2)
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| d2.head(2) |
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| d3.head(2) |
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | NaN | 74.48 | 17204.50 |
这 3 个工作表的数据维度完全一致,表头都是“流量级别、投放地区、访客数、支付转化率、客单价、支付金额”的结构,纵向合并起来分析十分方便。
说到纵向合并,就不得不提 concat() 方法,它的用法简单明了—— pd.concat([表1, 表2, 表3])。对于列字段统一的数据,我们只需把表依次传入参数:
df = pd.concat([d1,d2,d3])
df
合并效果如下:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 4 | 一级 | E 区 | 3769 | 0.0573 | 92.91 | 20068.20 |
| 5 | 一级 | F 区 | 2424 | 0.2207 | 89.33 | 47791.60 |
| 6 | 一级 | G 区 | 2412 | 0.0821 | 56.04 | 11096.42 |
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| 2 | 二级 | C 区 | 8870 | 0.0078 | 44.52 | 3072 |
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | NaN | 74.48 | 17204.50 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
| 3 | 三级 | D 区 | 31 | 0.0000 | NaN | NaN |
| 4 | 三级 | E 区 | 17 | 0.0000 | NaN | NaN |
对于 contact() 方法,其实将其参数 axis 设置成 1,它就可以进行横向连接了,但横向连接有更好的方法—— merge()。Pandas 的很多方法十分强大,能够实现多种功能,但对于初学者来说,过多甚至交叉的功能往往会造成混乱,所以这里对于一种功能先只用一种方式来实现。
横向连接
横向连接是 Pandas 数据处理中的高频操作,为了方便理解,我们构造一些更有代表性的数据集来练手:
h1 = pd.DataFrame ({'姓名': ['韩梅梅', '李雷', '李华', '王明', '铁蛋'], '语文': [93, 80, 85, 76, 58], '数学': [87, 99, 95, 85, 70], '英语': [80, 85, 97, 45, 88]})
h2 = pd.DataFrame ({'姓名': ['李华', '王明', '铁蛋', '刘强'], '篮球': [93, 80, 85, 76], '舞蹈': [87, 99, 95, 85]})
print(h1.head())
print(h2.head())
>>>
姓名 语文 数学 英语
0 韩梅梅 93 87 80
1 李雷 80 99 85
2 李华 85 95 97
3 王明 76 85 45
4 铁蛋 58 70 88
姓名 篮球 舞蹈
0 李华 93 87
1 王明 80 99
2 铁蛋 85 95
3 刘强 76 85
两个 DataFrame 是两张成绩表,表 h1 是 5 位同学的语文、数学、英语成绩,表 h2 是 4 位同学的篮球和舞蹈成绩。
如果想找到并合并在两张表中同时出现的同学及其成绩,可以用 merge() 方法:
pd.merge (left = h1, right = h2, left_on = '姓名', right_on = '姓名', how = 'inner')
>>>
姓名 语文 数学 英语 篮球 舞蹈
0 李华 85 95 97 93 87
1 王明 76 85 45 80 99
2 铁蛋 58 70 88 85 95
详解 merge() 参数:
left 和 right 分别对应着需要连接的左表和右表,这里语文、数学、英语成绩表是左表,篮球、舞蹈成绩表是右表。
left_on 与 right_on 参数指定左表和右表中用于匹配的列,left_on='姓名' 表示左表用“姓名”列作为连接的条件或者说桥梁。right_on='姓名' 也是一样的道理,表示右表也用“姓名”列作为匹配列。
how 用于指定连接方式,现在我们基于姓名来匹配,这里用的 inner,即只返回两个表中共同出现的姓名所对应的数据。连接操作中,连接方式的选择至关重要,下面我们来图解以下几种连接方式:inner、left、right、outer。
1. 内连接:inner
表 h1 和表 h2 是根据姓名来匹配的,使用内连接时,返回两张表中同时存在的姓名及所对应的数据。李华、王明、铁蛋这三位同学的姓名同时在两张表中出现,最终会返回他们的成绩连接结果,如图 4-1 所示。
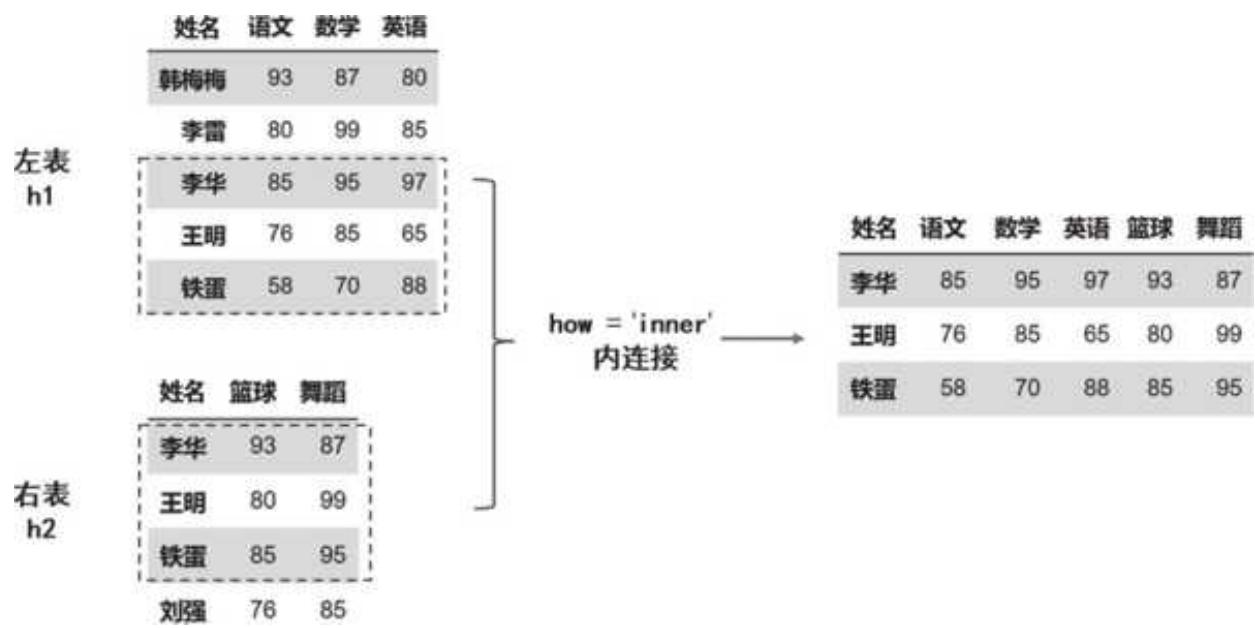
图 4-1 内连接 inner 的效果
2. 左连接:left
对于左连接(left)和右连接(right),我们可以直观地理解为以哪边的表为大,以谁为大就听谁的(所有行全部保留)。先看左连接,左表 h1 原封不动,右表根据左表进行合并:如果存在相关的名字,就正常返回数据;如果不存在(韩梅梅、李雷),就返回空值。
代码只需要调整 how 的值:
pd.merge(left = h1, right = h2, left_on = '姓名', right_on = '姓名', how = 'left')
左连接的效果如图 4- 2 所示。
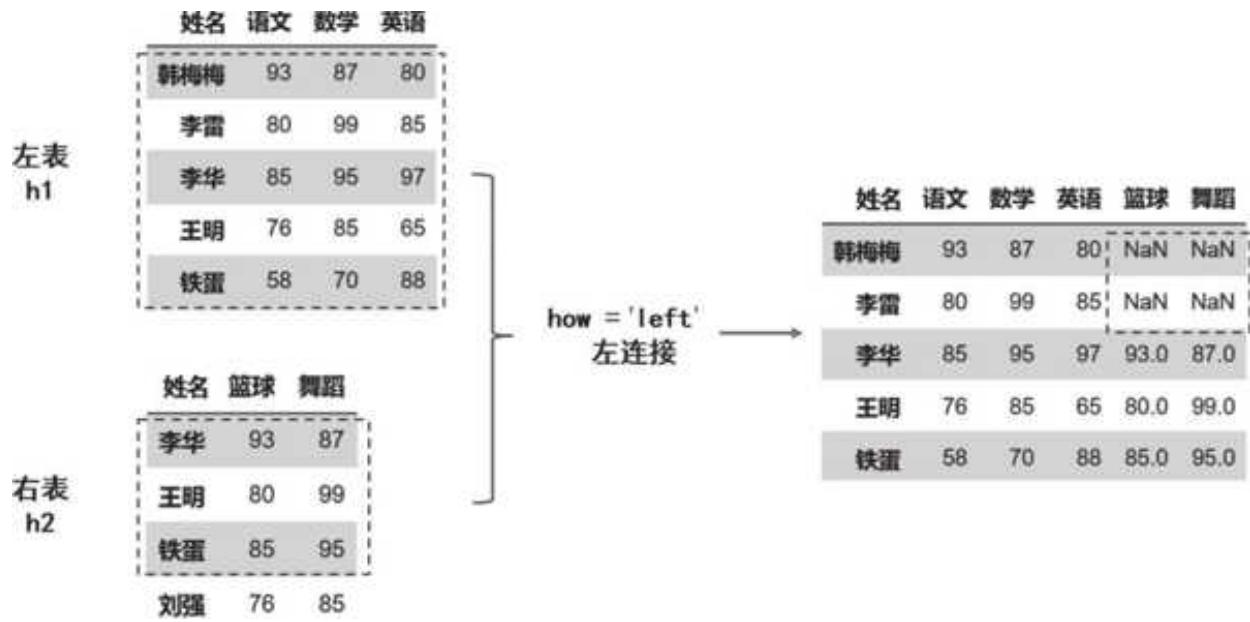
图 4-2 左连接 left 的效果
3. 右连接:right
右连接就是听右表的,完整保留右表的数据,左表能匹配上则返回对应的数据,如果匹配不上则为空,代码如下:
pd.merge (left = h1, right = h2, left_on = '姓名', right_on = '姓名', how = 'right')
匹配逻辑和结果如图 4- 3 所示。
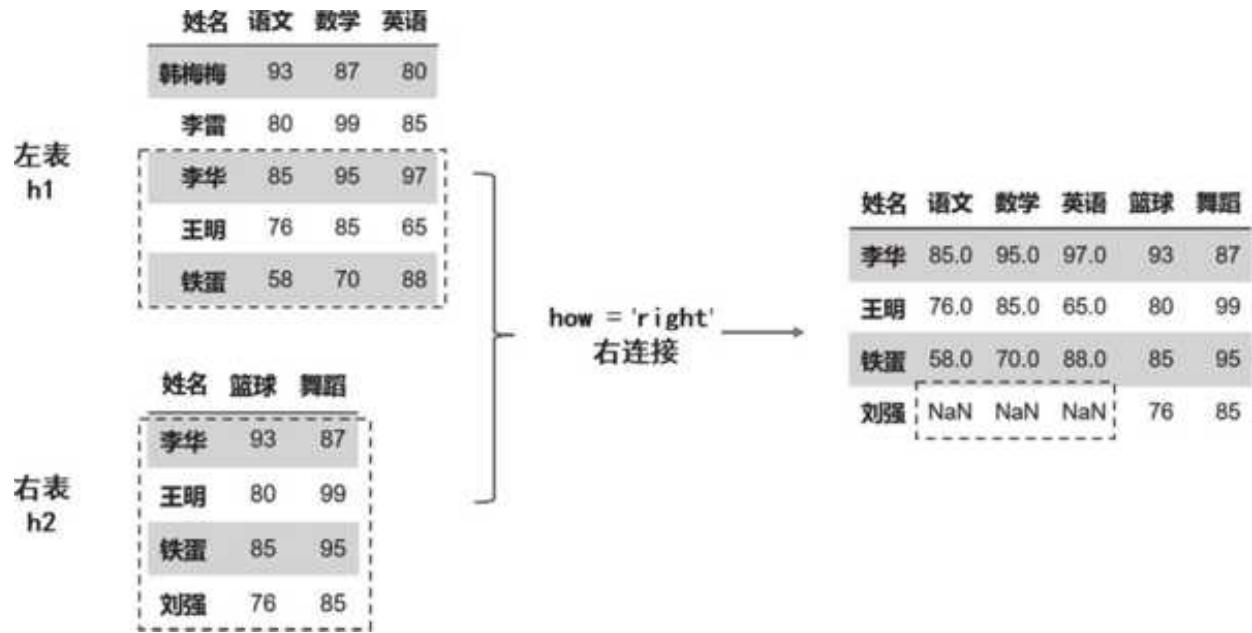
4. 外连接:outer
对于外连接,只需将 how 的值设置为 outer 即可:
pd.merge (left = h1, right = h2, left_on = '姓名', right_on = '姓名', how = 'outer')
外连接是两张表妥协的产物,我的数据全保留,你的也全保留,你有我无的就空着,你无我有的也空着,如图 4- 4 所示。
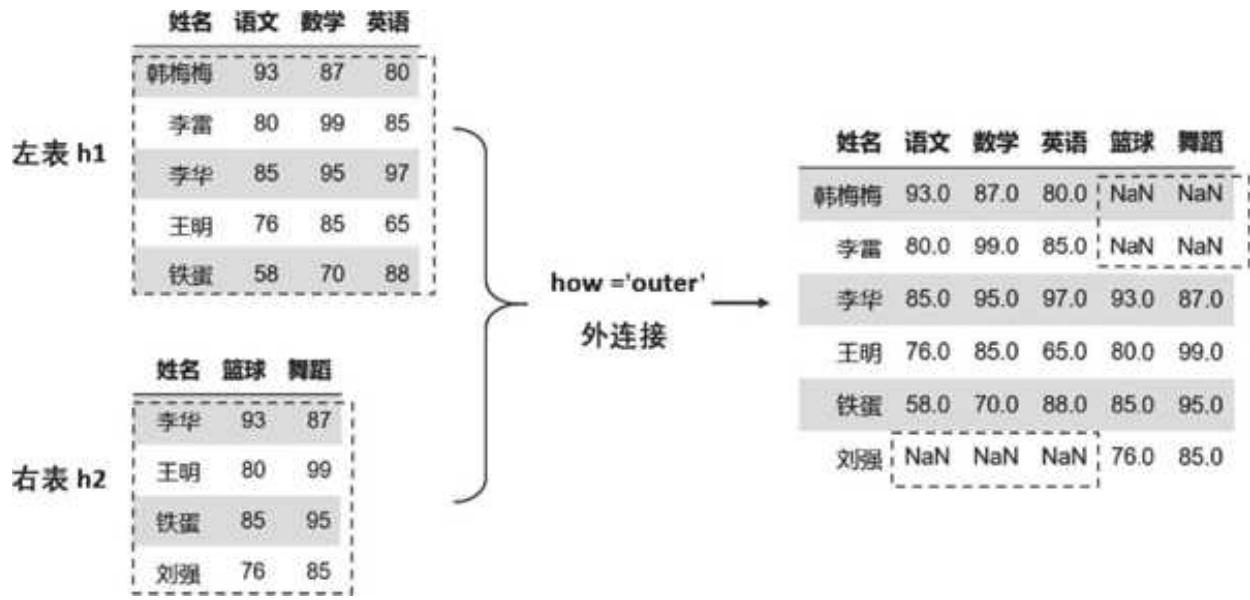
图 4-3 右连接 right 的效果图 4-4 外连接 outer 的效果
关于横向连接,重点是要确定左、右表根据什么字段来匹配(left_on 和 right_on)以及按照什么方式连接(how)。在有些情况下,也会用数据的索引作为匹配列,这个时候只需要把 left_on='姓名'、right_on='姓名',分别替代成 left_index 和 right_index 即可。
4.2 删:剔除噪声数据
缺失值处理
缺失值的处理主要有删除和补全两种方式:
1. 删除缺失值
在很多业务和商业分析场景下,缺失值的存在对分析来说是很大的干扰,而且很多时候不能通过均值、中位数等来补全,因为一旦用统计或机器学习的方法补全,反而影响了数据本身的结构,所以需要统一删除缺失值。
在 4.1.1 节中,合并后的 df 数据集倒数第 4 行和最后两行是有缺失数据的:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 4 | 一级 | E 区 | 3769 | 0.0573 | 92.91 | 20068.20 |
| 5 | 一级 | F 区 | 2424 | 0.2207 | 89.33 | 47791.60 |
| 6 | 一级 | G 区 | 2412 | 0.0821 | 56.04 | 11096.42 |
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| 2 | 二级 | C 区 | 8870 | 0.0078 | 44.52 | 3072 |
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | NaN | 74.48 | 17204.50 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
| 3 | 三级 | D 区 | 31 | 0.0000 | NaN | NaN |
| 4 | 三级 | E 区 | 17 | 0.0000 | NaN | NaN |
要删除缺失值,使用 dropna() 方法即可: |
df.dropna()
运行结果如下:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 4 | 一级 | E 区 | 3769 | 0.0573 | 92.91 | 20068.20 |
| 5 | 一级 | F 区 | 2424 | 0.2207 | 89.33 | 47791.60 |
| 6 | 一级 | G 区 | 2412 | 0.0821 | 56.04 | 11096.42 |
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| 2 | 二级 | C 区 | 8870 | 0.0078 | 44.52 | 3072.00 |
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
对比上面的数据可以发现,三级流量有 3 行数据存在缺失值,都被删掉了。
需要注意的是,dropna() 方法默认删除所有存在缺失值的行,即只要一行中任意一个字段为空,就会被删除。我们可以设置 subset 参数,例如 dropna(subset=['支付金额']),来指定当一行中的某一个字段(如“支付金额”)为空时,才会被删除,其他字段为空则不受影响。
df.dropna(subset=['支付金额'])
运行效果如下:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 4 | 一级 | E 区 | 3769 | 0.0573 | 92.91 | 20068.20 |
| 5 | 一级 | F 区 | 2424 | 0.2207 | 89.33 | 47791.60 |
| 6 | 一级 | G 区 | 2412 | 0.0821 | 56.04 | 11096.42 |
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| 2 | 二级 | C 区 | 8870 | 0.0078 | 44.52 | 3072.00 |
| 0 | 二级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | NaN | 74.48 | 17204.50 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
可以发现,当指定 subset=['支付金额'] 时,三级流量 B 区虽然支付转化率为空,但是满足支付金额不为空的条件,因而被保留。
2. 缺失值的补全
fillna() 方法常用来补全缺失值,在括号内输入想要补全的值即可:
df.fillna(0)
运行结果如下:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | 0.0000 | 74.48 | 17204.50 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
| 3 | 三级 | D 区 | 31 | 0.0000 | 0.00 | 0.00 |
| 4 | 三级 | E 区 | 17 | 0.0000 | 0.00 | 0.00 |
三级流量中支付转化率、客单价、支付金额为空的值都被替换成了 0。fillna()方法还可以通过{}来指定列填充:
df.fillna({'客单价:666,'支付金额:df['支付金额'].min()})
运行结果如下:
| 流量级别 | 投放地区 | 访客数 | 支付转化率 | 客单价 | 支付金额 | |
|---|---|---|---|---|---|---|
| 0 | 一级 | A 区 | 44300 | 0.1178 | 58.79 | 306887.83 |
| 1 | 一级 | B 区 | 30612 | 0.1385 | 86.64 | 367338.10 |
| 2 | 一级 | C 区 | 18389 | 0.0250 | 0.28 | 129.58 |
| 3 | 一级 | D 区 | 4509 | 0.1073 | 64.12 | 31035.14 |
| 4 | 一级 | E 区 | 3769 | 0.0573 | 92.91 | 20068.20 |
| 5 | 一级 | F 区 | 2424 | 0.2207 | 89.33 | 47791.60 |
| 6 | 一级 | G 区 | 2412 | 0.0821 | 56.04 | 11096.42 |
| 0 | 二级 | A 区 | 29111 | 0.1066 | 87.40 | 271189.23 |
| 1 | 二级 | B 区 | 17165 | 0.2271 | 91.22 | 355662.39 |
| 2 | 二级 | C 区 | 8870 | 0.0078 | 44.52 | 3072.00 |
| 0 | 三级 | A 区 | 45059 | 0.1366 | 90.11 | 554561.22 |
| 1 | 三级 | B 区 | 2133 | NaN | 74.48 | 17204.50 |
| 2 | 三级 | C 区 | 899 | 0.0990 | 92.99 | 8276.50 |
| 3 | 三级 | D 区 | 31 | 0.0000 | 666.00 | 129.58 |
| 4 | 三级 | E 区 | 17 | 0.0000 | 666.00 | 129.58 |
| 三级流量中客单价的缺失值已经用指定的 666 补全,支付金额则用支付金额最小值填充。由于没有指定支付转化率的填充,支付转化率的缺失值依然为 NaN。 |
去除重复项
案例数据比较干净,没有两行数据是完全一样的,不过这里我们要制造点困难,增加几行重复值:
repeat = pd.concat([df,df])
print('有重复项的数据集一共有多少行:',len(repeat))
>>>
有重复项的数据集一共有多少行:30
把源数据与其自身进行纵向拼接,相当于将源数据再重复了一遍,然后赋值给 repeat,这样每一行数据就都有了重复的数据。
要把重复数据删掉,可以用 duplicated() 方法:
repeat.duplicated()
运行之后,返回了一列与源数据等长的布尔值:
False
False
False
False
False
False
···
True
True
True
True
True
True
True
dtypedtype: bool
duplicated() 方法执行时,Pandas 会从上至下扫描数据,判断每一行数据是否与前面的重复,如果不重复返回 False,重复则返回 True。剔除重复数据,本质上是筛选出不重复的数据,即布尔值结果为 False 的行:
# 把duplicated ()==False 的结果当作索引,筛选出不重复的值
unique = repeat.loc[repeat.duplicated()== False,:]
print('去重后的数据集一共有多少行:',len(unique))
>>>
去重后的数据集一共有多少行:15
duplicated() 方法默认会删掉完全重复即每个值都一样的行。如果要删除指定列重复的数据,可以通过 subset 参数指定列名来实现。假如我们有个奇怪的想法,要基于“流量级别”这列进行去重,则可以使用以下代码:
repeat.loc[repeat.duplicated(subset = '流量级别') == False,:]
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额
0 一级 A 区 44300 0.1178 58.79 305667.00
0 二级 A 区 29111 0.1066 87.40 271189.23
0 三级 A 区 45059 0.1366 90.11 554561.22
我们会发现,流量有 3 个级别,通过指定列名,我们删除了“流量级别”这个字段重复的行,保留了各自不重复的第 1 行。
继续展开讲,在源数据中,流量级别为“一级“”的有 7 行数据,每行数据的其他字段都不相同。这里我们删除了后 6 行,只保留了第 1 行,但如果我们想在去重的过程中删除前 6 行,保留最后一行数据,怎么操作呢?答案很简单,指定 keep 参数即可:
# 在 duplicated() 中,传入的第一个参数默认就是 subset 参数指定的列名
repeat.loc[repeat.duplicated(subset = '流量级别', keep ='last') == False,:]
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额
6 一级 G 区 2412 0.0821 56.04 11096.42
2 二级 C 区 8870 0.0078 44.52 3072.00
4 三级 E 区 17 0.0000 NaN NaN
keep 值等于'last',即当数据重复时会保留最后一行数据。不输入 keep 值时,系统默认会给 keep 赋值为'first',即保留第 1 行数据而删掉其他行。
4.3 选:基于条件选择数据
第 3 章我们对索引进行了详细讲解,这里除了对索引进行简单回顾外,还会介绍排序的用法。
按条件索引/筛选
这次的需求是筛选出访客数大于 10000 的一级渠道,用 loc 筛选很方便:
df.loc[(df['访客数'] > 10000) & (df['流量级别'] == '一级'), :]
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额
0 一级 A 区 44300 0.1178 58.79 305667.00
1 一级 B 区 30612 0.1385 86.64 361814.00
2 一级 C 区 18389 0.0250 0.28 129.58
在行参数的位置设置好满足访客数大于 10000 且流量级别为一级这两个条件,将每一个条件写在小括号内,然后用&符号连接即可。
排序
很多情况下,我们查询的时候需要通过排序来观察数据规律,以及快速筛选出前 N 个数据项。对于案例数据,怎样按支付金额进行排序并筛选出前三的渠道呢?解决问题的关键就在于排序,这个时候 sort_values() 方法就派上用场了:
sort_df = df.sort_values('支付金额', ascending = False)
print(sort_df)
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额
0 三级 A 区 45059 0.1366 90.11 554561.22
1 一级 B 区 30612 0.1385 86.64 361814.00
1 二级 B 区 17165 0.2271 91.22 355662.39
0 一级 A 区 44300 0.1178 58.79 305667.00
0 二级 A 区 29111 0.1066 87.40 271189.23
5 一级 F 区 2424 0.2207 89.33 47791.60
3 一级 D 区 4509 0.1073 64.12 31035.14
4 一级 E 区 3769 0.0573 92.91 20068.20
1 三级 B 区 2133 NaN 74.48 17204.50
6 一级 G 区 2412 0.0821 56.04 11096.42
2 三级 C 区 899 0.0990 92.99 8276.50
2 二级 C 区 8870 0.0078 44.52 3072.00
2 一级 C 区 18389 0.0250 0.28 129.58
3 三级 D 区 31 0.0000 NaN NaN
4 三级 E 区 17 0.0000 NaN NaN
顾名思义,sort_values() 是按照数值进行排序。首先要传入的参数是列参数,即根据哪一列的数值来进行排序;如果是多列排序的话,需要用[]括起来。ascending 参数决定了排序顺序,值为 False 表示降序,值为 True 则表示升序。
排序完之后,筛选出前三的渠道,可以直接用 head() 方法:
sort_df.head(3)
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额
0 三级 A 区 45059 0.1366 90.11 554561.22
1 一级 B 区 30612 0.1385 86.64 361814.00
1 二级 B 区 17165 0.2271 91.22 355662.39
这里补充一个知识点,大家会发现,无论删空的 dropna() 还是排序的 sort_values(),在对源数据进行操作后,源数据并未改变,这是因为我们没有对这几个方法的 inplace 值进行设置,如果设置 inplace=True,删空和排序都会在源数据上生效。
但为了避免出现不必要的错误而无法更改,这里更建议大家把操作后的源数据赋值给新的变量,如 new_value=df.dropna(),而不是直接将源数据的 inplace 参数设置为 True。
4.4 改:改变数据形态
前 3 节的操作其实在某种程度上已经对原始数据做了修改,而这一节的改,并不是传统意义上改变数据的值,而是改变数据的形态。转置、分组和切分是 Pandas 中常见的 3 个改变数据形态的操作。
转置
转置,就是把数据表的行列进行互换,即将原来的行数据变成列数据,将原来的列数据变成行数据。转置常用 df.T 方法来实现,非常简单:
# 以 d2 流量表为例
print(d2)
print(d2.T)
运行结果如图 4- 5 所示。

图 4-5 数据转置结果
分组
关于分组,我们重点介绍 groupby() 和 agg() 方法。
1. groupby()
在案例数据中,流量级别有三级,每一级下又有多个投放地区,如果我们想汇总看看每个级别流量所对应的总访客数和支付金额,就需要用到分组了。
groupby() 是分组方法,其最主要的参数是列参数,即按照哪一列或者哪几列(多列要用 [] 括起来)进行汇总。这里按照流量级别进行汇总:
df.groupby('流量级别')
>>>
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000213F8734160>
可以看到,直接分组之后,没有返回任何我们期望的数据,返回的是一个分组对象。要进一步得到数据,需要在分组的时候对相关字段进行计算(常用的计算方法有 sum、max、min、mean、std、count):
df.groupby('流量级别').sum()
>>>
流量级别 访客数 支付转化率 客单价 支付金额
一级 106415 0.7487 448.11 784346.87
三级 48139 0.2356 257.58 580042.22
二级 55146 0.3415 223.14 629923.62
groupby() 后面加上了 sum(),代表我们先按照流量级别进行分组,再对分组内的字段进行求和。由于没有指定求和的列,所以对所有数值型字段进行了求和。此处我们只想汇总各级别流量下的访客数和支付金额,因此需要指明具体的列名:
df.groupby('流量级别')['访客数','支付金额'].sum()
>>>
流量级别 访客数 支付金额
一级 106415 784346.87
三级 48139 580042.22
二级 55146 629923.62
流量级别作为汇总的依据列,会被默认转换为索引列。在实践中依据列变成索引列处理起来不够方便,如果我们不希望它变成索引列,在分组处理后加上 reset_index() 即可:
df.groupby('流量级别')['访客数','支付金额'].sum().reset_index()
>>>
流量级别 访客数 支付金额
0 一级 106415 777601.94
1 三级 48139 580042.22
2 二级 55146 629923.62
2. agg()
agg() 方法能够让 groupby() 分组变得更加灵活,实现分组后的多种汇总计算,例如:
df.groupby('流量级别')['支付转化率','客单价'].agg({'mean','sum'})
>>>
支付转化率 客单价
mean sum mean sum
流量级别
一级 0.106957 0.7487 64.015714 448.11
三级 0.058900 0.2356 85.860000 257.58
二级 0.113833 0.3415 74.380000 223.14
agg() 中指定了 mean 和 sum 两种统计方式,数据在按流量级别分组之后,分别计算了支付转化率、客单价的均值与汇总值。
agg() 还可以对不同字段采用不同的汇总方式。例如,想要计算每种流量级别分组下访客数的最大值、支付金额的中位数,也可以用一行代码实现:
df.groupby('流量级别').agg({'访客数': 'max','支付金额': 'median'})
>>>
流量级别 访客数 支付金额
一级 44300 31035.14
三级 45059 17204.50
二级 29111 271189.23
切分
切分操作常用于一维数组的分类和打标,cut()方法能够高效完成任务。它的用法和主要参数如下。
pd.cut (x, bins, right, labels)
- x:代表要传入用于切分的一维数组,可以是列表,也可以是 DataFrame 的一列。
- bins:表示切分的方式
- 可以传入数值,如传入 5 表示整个数据会按照取值范围切分为 5 组;
- 也可以自定义传入列表,如传入
[0,100,200,300],方法会自动按照(0,100],(100,200],(200,300]的区间来切分。
- right:值可以是 True 或 False。
- 当值为 True 时,表示分组区间为左开右闭(不含左含右);
- 当值为 False 时,则分组区间为左闭右开。
- labels:标签参数,把数据切分成 N 组,可以为每一组设置一个标签,如低、中、高。不要被复杂的解释所迷惑,我们通过一个例子来理解。
以案例数据为例,每个渠道都有对应的访客数,我们现在希望对各渠道的访客级别进行评估,按照访客数大小,分成忽略级(访客数少于 100)、百级、千级和万级的渠道:
pd.cut(x=df['访客数'], bins=[0,100,1000,10000,100000])
>>>
0 (10000, 100000]
1 (10000, 100000]
2 (10000, 100000]
3 (1000, 10000]
4 (1000, 10000]
5 (1000, 10000]
6 (1000, 10000]
0 (10000, 100000]
1 (10000, 100000]
2 (1000, 10000]
0 (10000, 100000]
1 (1000, 10000]
2 (100, 1000]
3 (0, 100]
4 (0, 100]
Name: 访客数, dtype: category
Categories (4, interval[int64, right]):
[(0, 100] < (100, 1000] < (1000, 10000] < (10000, 100000]]
因为我们想对流量级别按照百、千、万进行归类,所以把分组数值标准传入 bins 参数。从结果可以看到,在不设置 right 值的情况下,分组区间默认是左开右闭的,而我们希望的是左闭右开,所以需要将 right 值设置为 False。
下面我们对分组后的数据进行打标,访客数在 0~99 设置为忽略级,100~999 设置为百级,千级和万级以此类推,同时将打好标签的数据作为新列提供给源数据:
df['分类打标'] = pd.cut(x = df['访客数'], bins = [0,100,1000,10000,100000], right = False, labels = ['忽略级','百级','千级','万级'])
>>>
流量级别 投放地区 访客数 支付转化率 客单价 支付金额 分类打标
0 一级 A 区 44300 0.1178 58.79 305667.00 万级
1 一级 B 区 30612 0.1385 86.64 361814.00 万级
2 一级 C 区 18389 0.0250 0.28 129.58 万级
3 一级 D 区 4509 0.1073 64.12 31035.14 千级
4 一级 E 区 3769 0.0573 92.91 20068.20 千级
5 一级 F 区 2424 0.2207 89.33 47791.60 千级
6 一级 G 区 2412 0.0821 56.04 11096.42 千级
0 二级 A 区 29111 0.1066 87.40 271189.23 万级
1 二级 B 区 17165 0.2271 91.22 355662.39 万级
2 二级 C 区 8870 0.0078 44.52 3072.00 千级
0 三级 A 区 45059 0.1366 90.11 554561.22 万级
1 三级 B 区 2133 NaN 74.48 17204.50 千级
2 三级 C 区 899 0.0990 92.99 8276.50 百级
3 三级 D 区 31 0.0000 NaN NaN 忽略级
4 三级 E 区 17 0.0000 NaN NaN 忽略级
只用一行代码就完成了分组、判断和打标的过程。