第5章 Pandas 两大进阶利器
5.1 数据透视表
什么是数据透视表
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和、求最大值和最小值、计数等。它能很方便地对原始数据进行分类、汇总和计算。与 groupby 的分组统计相比,数据透视表不仅能够单维度聚合,还能在行和列上同时拆分计算。
让数据透视表声名大噪的是 Excel,其内嵌的数据透视表功能(见图 5- 1)可谓是无人不知无人不晓,通过简单的拖曳就能实现复杂的数据处理分析,极大提升效率。
Pandas 也有对应的方法来实现数据透视表功能,而且在处理效率和性能上更胜一筹。
Pandas 数据透视表简介
Pandas 中实现数据透视表功能的是 pivot_table(),它的使用方法和参数如下:
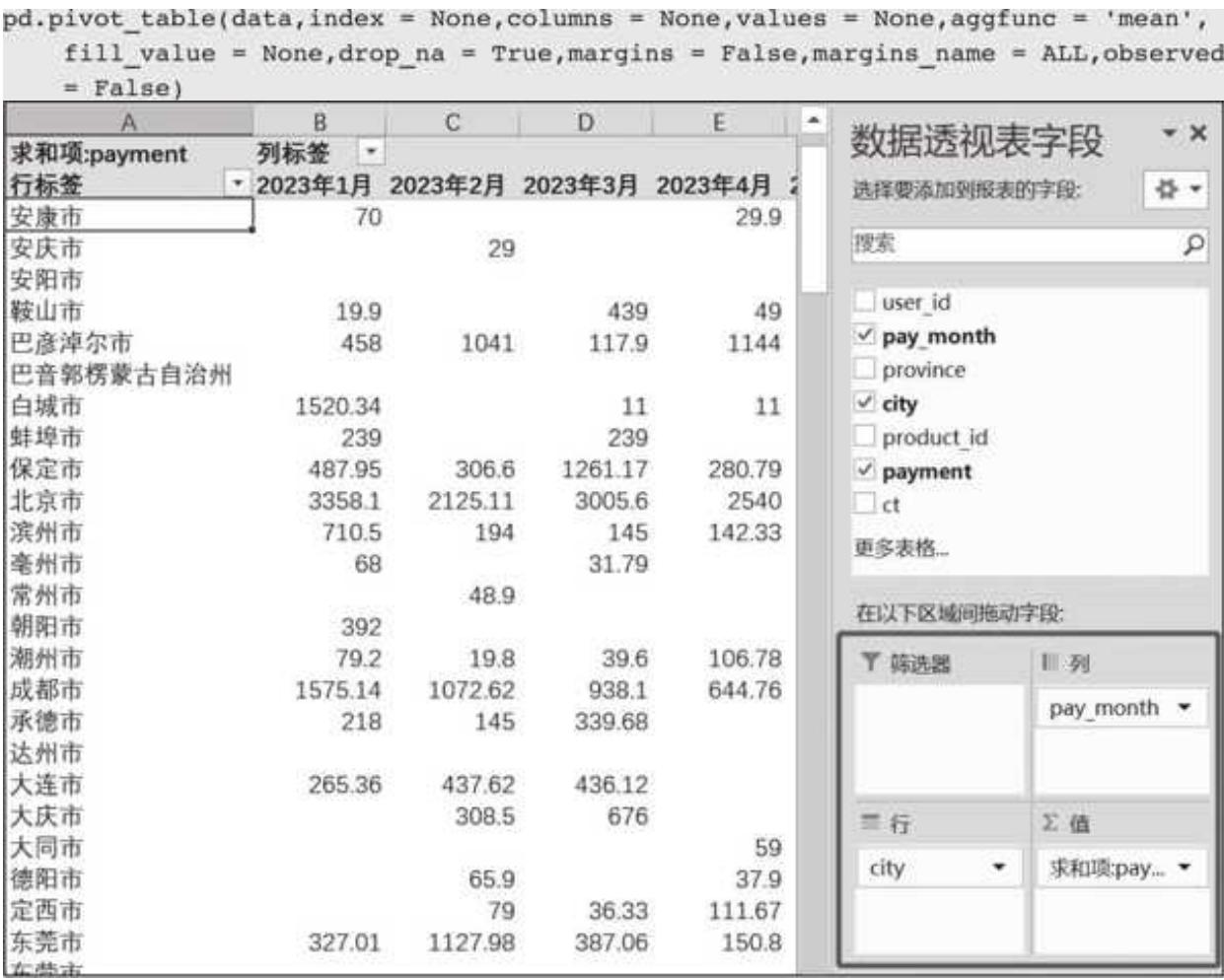
图 5-1 Excel 数据透视表样例
下面是 pivot_table() 的几个常用参数的介绍,后面会有实例来帮助理解。
- data:传入要进行透视的原始数据。
- index:行分组字段,用什么字段作为索引,可以是一个或多个字段,对应 Excel 数据透视表中行的位置。
- columns:列分组字段,用什么字段作为分类,也可以是一个或多个,对应 Excel 数据透视表中列的位置。
- values:值字段,传入哪个字段的值参与计算,对应 Excel 数据透视表中值的位置。
- aggfunc:用什么方式计算,默认用均值。
它还有几个不太常用的参数,大家了解其作用即可。
- fill_value:用什么填充缺失值。
- dropna:是否删除缺失值,值为 True 则删除。
- margins:是否显示合计的列。
- margins_name:如果显示合计列,对应的名称设置。
接下来,我们通过实例来感受一下 Pandas 数据透视表的实力。
数据透视表实例
先导入案例数据。案例数据是平行时空里一个电商平台中不同行业的关键数据:
import pandas as pd
import numpy as np
# 当数值过大时,Jupyter Notebook 会默认显示科学记数法,这行代码设置不显示科学记数法
pd.set_option ('display.float_format', lambda x:'0.2f' % x)
data = pd.read_excel('第5章 数据透视表案例数据.xlsx')
print(data.info())
data.head(6)
运行结果如下:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1944 entries, 0 to 1943 Data columns (total 7 columns): # Column Non- Null Count Dtype 0 user_id 1944 non- null object 1 pay_month 1944 non- null object 2 province 1944 non- null object 3 city 1944 non- null object 4 product_id 1944 non- null object 5 payment 1944 non- null float 64 6 ct 1944 non- null int 64 dtypes: float 64 (1), int 64 (1), object (5) memory usage: 105.4+ KB
user_id pay_month province city product_id payment ct 0 u 000027 2023 年 1 月浙江省金华市 PD 00054 10.01 11 u 000027 2023 年 1 月浙江省温州市 PD 00008 89.79 12 u 000056 2023 年 1 月浙江省绍兴市 PD 00176 211.08 13 u 000209 2023 年 1 月江苏省南京市 PD 00476 48.92 24 u 000231 2023 年 1 月江苏省徐州市 PD 00237 14.90 1
总共 1944 条交易数据,整体很规整,没有缺失值,每条数据包含用户 ID、支付月份、省份、城市、产品 ID、销售金额和购买商品件数等字段。
下面我们用几个需求来练习一下。
1. 计算各省总销售额(payment)和总购买件数(ct)
t 1 = pd. pivot_table (data, index = 'province', values = ['payment','ct'], aggfunc = 'sum') t 1. sort_values ('payment', ascending = False). head ()
运行结果如下:
| province | ct | payment |
| 上海市 | 233 | 85436.48 |
| 浙江省 | 395 | 59970.63 |
| 福建省 | 155 | 24312.67 |
| 山东省 | 130 | 19757.25 |
| 安徽省 | 200 | 18359.88 |
设置 index 指定按省份聚合,values 确认销售金额和购买商品件数参与计算,aggfunc 指定求和,很快得到了预期结果。
数据透视表返回的结果默认是不排序的,这里为了美观,对结果排了个序。
2. 计算各省份、城市平均销售金额
只需按照需求调整对应参数即可:
t2 = pd. pivot_table (data, index = ['province','city'], values = 'payment', aggfunc = 'mean')
t2.head(4)
分组参数加入了城市,求值参数只有销售金额,代码运行结果如下:
| province | city | payment |
| 上海市 | 上海市 | 540.74 |
| 云南省 | 昆明市 | 194.78 |
| 云南省 | 普洱市 | 69.00 |
| 云南省 | 曲靖市 | 72.27 |
3. 计算各省份、城市不同月份的销售金额
如果数据格式按照省份、城市、月份、销售金额来展示,数据会很长,显得臃肿;而如果把月份作为列,整体会直观很多:
t 3 = pd. pivot_table (data, index = ['province','city'], columns = 'pay_month', values = 'payment', aggfunc = 'sum', fill_value = 0) t 3. head (4)
运行结果如下:
| pay_month | 2023 年 1 月 | 2023 年 2 月 | 2023 年 3 月 | 2023 年 4 月 | 2023 年 5 月 | 2023 年 6 月 | |
| province | city | ||||||
| 上海市 | 上海市 | 20372.08 | 12855.85 | 12309.89 | 17910.81 | 12421.65 | 9566.20 |
| 云南省 | 昆明市 | 415.0 | 239.00 | 0.00 | 125.11 | 0.00 | 0.00 |
| 云南省 | 普洱市 | 0.00 | 0.00 | 0.00 | 69.00 | 0.00 | 0.00 |
| 云南省 | 曲靖市 | 161.50 | 214.70 | 195.10 | 168.00 | 128.00 | 0.00 |
当指定 columns='pay_month'时,支付月份会横向展开,和省份、城市做交叉,根据 aggfunc 计算对应的汇总值。案例中云南省有些城市的销售金额为空,我们设置了 fill_value 参数,把空值替换为 0。
5.2 强大又灵活的 apply
我们在这里单独用一节来讲 apply,有两个重要原因。
- apply 概念相对晦涩,需要结合具体的案例反复咀嚼和实践。
- apply 极其灵活、高效,甚至可以说它重新定义了 Pandas 的灵活。一旦熟练运用,我们在进行数据清洗和分析时可谓如鱼得水。
一些图书和网上资料会结合 lambda 语法来讲 apply 案例,这样虽格式优雅,但有理解门槛。为了让大家更好地吸收,这里我都采用最质朴的方式。
apply 初体验
apply()方法因为总是和 groupby() 方法一起出现,所以得了个“groupby 伴侣”的称号。它的主要作用是做聚合运算,以及在分组基础上根据实际情况来自定义一些规则,常见用法和参数如下:
data.groupby (['列名']). apply (func, args)
-
func: 核心参数,它接收一个函数,会把分组后的数据根据函数定义进行处理。
-
args: 向函数传入的参数,这个参数仅作了解,使用频率较低。
总体来看,如果把源数据比作面粉,用 groupby 进行分组就是把面粉揉成一个个面团的过程,apply 起到的作用是根据数据需求来调馅,并且把每一个面团包成我们喜欢的包子。接下来,我们通过两个场景更深入地感受 apply 的优雅迷人之处。
计算最好、最差成绩
1. 背景和思路
背景:我们拿到了一份 4 位同学 3 次模拟考试的成绩,想知道每位同学历次模拟中最好成绩和最差成绩分别是多少。
思路:最好和最差分别对应着 max 与 min,我们先按姓名分组,再用 apply() 方法返回对应的最大值和最小值,最后将结果合并。
2. 导入和处理
先导入源数据:
score = pd. read_excel ('第 5 章 apply 案例数据. xlsx', sheet_name = '成绩表') score.head (6)
运行结果如下:
| 姓名 | 科目 | 综合成绩 | |
| 0 | 李华 | 一模 | 651 |
| 1 | 李华 | 二模 | 579 |
| 2 | 李华 | 三模 | 580 |
| 3 | 王雷 | 一模 | 475 |
| 4 | 王雷 | 二模 | 455 |
| 5 | 王雷 | 三模 | 432 |
看一看每位同学的最高成绩:
max_score = score.groupby ('姓名')['综合成绩']. apply (max). reset_index () max_score
运行结果如下:
姓名综合成绩 0 张建国 6911 李华 6512 李子明 5773 王雷 475
我们指定“综合成绩”列,然后将 max 函数直接传入 apply()方法,返回了对应分组内成绩的最大值。max、min、len 等常见函数可以直接传入 apply()方法。
groupby()方法默认会把分组依据列(姓名)变成索引,这里用 reset_index()方法重置(取消)姓名索引,将它保留在列的位置,维持 DataFrame 格式,方便后续匹配。
再筛选出每位同学的最低成绩:
min_score = score.groupby ('姓名')['综合成绩']. apply (min). reset_index () min_score
运行结果如下:
姓名综合成绩 0 张建国 5531 李华 5792 李子明 4903 王雷 432
将两张表按姓名合并:
score_comb = pd.merge (max_score, min_score, left_on = '姓名', right_on = '姓名', how = 'inner') score_comb. columns = ['姓名','最好成绩','最差成绩']score_comb
运行结果如下:
| 姓名 | 最好成绩 | 最差成绩 | |
| 0 | 张建国 | 691 | 553 |
| 1 | 李华 | 651 | 579 |
| 2 | 李子明 | 577 | 490 |
| 3 | 王雷 | 475 | 432 |
得到了我们预期的结果,只是列名略丑,可以通过更改 columns 来实现。这个场景比较死板和严肃,下面的场景我们换个更接地气的风格。
筛选每个分组下的第 3 名
1. 背景和思路
背景:老板发过来一份省份、城市销售表,里面包含省份、城市、近 1 个月销售额 3 个字段,没等你开口问需求,老板就开腔了:“我最近对 3 这个数字有执念,我想看看近 1 个月每个省份销售额排名第 3 的分别是哪些城市,以及它们的销售额情况。对了,这个需要尽快实现!”
思路:问题的关键是找到近 1 个月每个省份销售排名第 3 的城市。首先应该对省份、城市按销售额进行降序排列,然后找到对应排名第 3 的城市。如果是找排名第 1 的城市,我们可以通过排序后去重实现,但是要找排名第 3 的城市,有点难度。
正在疯狂挠头、一筹莫展之际,你想起了一句诗,“假如数据清洗难住了你,不要悲伤,不要心急,忧郁的日子里需要 apply”,瞬间豁然开朗。
2. 导入数据
先导入数据源,对数据做个初步了解:
order = pd. read_excel ('第 5 章 apply 案例数据. xlsx', sheet_name = '省、市销售数据') print (order.info ()) order.head ()
运行结果如下:
<class 'pandas.core.frame.DataFrame'>RangeIndex: 210 entries, 0 to 209 Data columns (total 3 columns): # Column Non- Null Count Dtype 0 省份 210 non- null object 1 城市 210 non- null object 2 近 1 个月销售额 210 non- null int 64 dtypes: int 64 (1), object (2) memory usage: 5.0+ KB 省份城市近 1 个月销售额 0 重庆重庆市 255343 1 浙江省金华市 302624 2 浙江省台州市 147853 3 浙江省井山市 136547 4 浙江省杭州市 109073
数据源有省份、城市、近 1 个月销售额 3 个字段,一共 210 行数据,乱序排列,且都没有缺失值,整体比较规整。
3. 操作详解
要获取销售额排名第 3 的城市,必须先进行排序,这里我们用省份、近 1 个月销售额两个关键字段进行降序排列,得到我们期望的顺序:
order_rank = order. sort_values (['省份', '近 1 个月销售额'], ascending = False) order_rank.head ()
运行结果如下:
| 省份 | 城市 | 近 1 个月销售额 | |
| 37 | 陕西省 | 西安市 | 450490 |
| 38 | 陕西省 | 延安市 | 120161 |
| 39 | 陕西省 | 安康市 | 60456 |
| 40 | 陕西省 | 汉中市 | 59391 |
| 41 | 陕西省 | 咸阳市 | 47411 |
接着,在 apply 登场前,我们先详细剖析一下整个过程,如图 5- 2 所示。
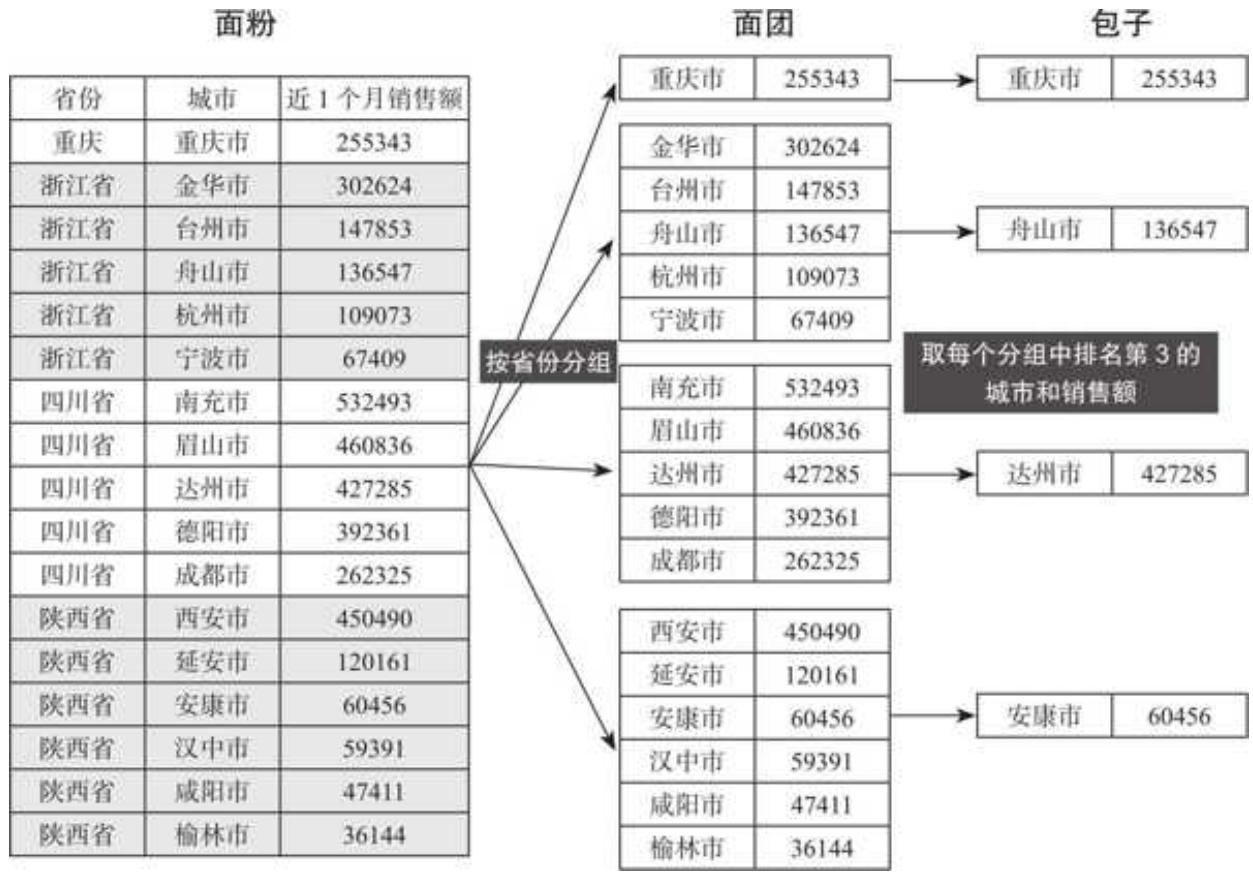
图 5-2 apply 分组过程详解
apply 的精髓在于 groupby 分组以及 apply 自定义函数并应用。为了便于理解,这里以做包子来类比。在做包子时,我们需要先把面粉揉成一个个面团,再调馅,把一个个面团包成我们想要口味的包子。对应到 apply 的使用中,面粉就是源数据,揉面成团的过程就是 groupby 分组,而调馅做包子就是 apply 自定义函数并应用。
结合我们的目标,揉面是按省份进行分组,得到每个省份各个城市及其对应销售额这些“面团”;调馅做包子是在每个“面团”中取每个省份销售额排名第 3 的城市及其销售额字段。
分组非常简单,按省份分组即可。而取第 3 名的城市及其销售额表明我们需要城市和销售额两个字段,所以在分组后指明这两列:
order_rank. groupby(省份)[「城市,近 1 个月销售额']
这一步,我们已经揉好了面,原始的“面团”(分组)也初步成形,虽然返回的结果有点晦涩(是一个分组对象),但是我们可以在脑海中构建一下这些“面团”,图 5- 3 展示了部分“面团”。
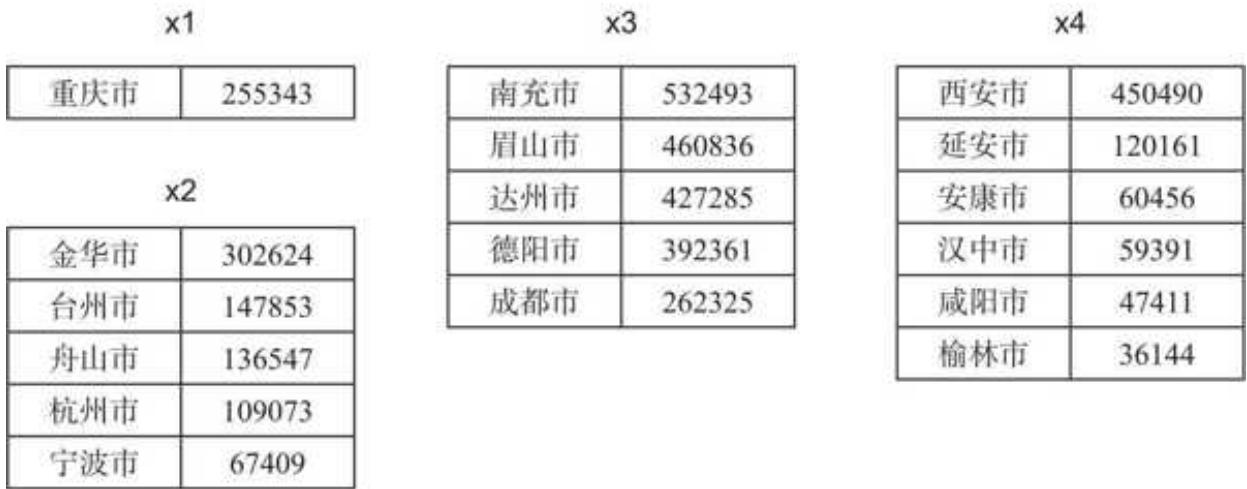
图 5-3“面团”(分组)样例
要把这些“面团”包成“包子”,就要取出每个“面团”(省份销售额)中排名第 3 的城市。有个问题需要注意,直辖市是和省同级的,而其下的城市只有一行数据,对于这样的城市,我们就默认返回其本身的数据。对于非直辖市省份来说,就需要定位和筛选。
拿 x 2 来举例,要找到这个“面团”中排名第 3 的城市及其销售额,应该怎么做呢?答案是直接用索引,把它看作一个 DataFrame 格式的表,要选取第 3 行的所有值,包括城市和销售额。这里用 iloc 索引,代码如下:
x 2. iloc[2,:]
下面把直辖市的判断逻辑和非直辖市的筛选逻辑整合成一个函数:
def get third (x): # 如果分组长度小于或等于 1,意味着该省份为直辖市 if len (x) <= 1: # 返回第 0 行的所有值,即直辖市本身 return x.iloc[0,:] # 针对非直辖市 else: # 返回第 3 行(排名第 3,索引是 2)的所有值(城市,近 1 个月销售额) return x.iloc[2,:]
这个函数将会在 apply 的作用下对每一个分组进行批量化处理,抽取出排名第 3 的城市及其销售额,应用起来很简单:
运行结果如下:
| 省份 | 城市 | 近 1 个月销售额 |
| 上海 | 上海市 | 139261 |
| 云南省 | 昆明市 | 203210 |
| 内蒙古自治区 | 兴安盟 | 258106 |
| 北京 | 北京市 | 154682 |
| 四川省 | 达州市 | 427285 |
| 天津 | 天津市 | 510720 |
| 安徽省 | 合肥市 | 179518 |
| 山东省 | 菏泽市 | 187375 |
| ... | ... | ... |
| 浙江省 | 舟山市 | 136547 |
| 湖北省 | 襄阳市 | 194910 |
| 湖南省 | 长沙市 | 163263 |
| 甘肃省 | 天水市 | 119378 |
| 福建省 | 莆田市 | 209084 |
| 辽宁省 | 葫芦岛市 | 392363 |
| 重庆 | 重庆市 | 255343 |
| 陕西省 | 安康市 | 60456 |
通过上述代码,每个省份销售额排名第 3 的城市已经筛选出来。回顾整个操作流程,先排序,后分组,最后通过定义函数传入 apply()方法,提取出我们的目标值。分组后数据的抽象形态以及如何判断和取出我们需要的值,是解决问题的关键与难点。
5.3 本章小结
本章我们学习了数据透视表和 apply 两大进阶利器。
-
数据透视表帮助我们对数据进行分组、交叉等处理,进行灵活的计算。index、columns、values、aggfunc 是它的几个常用的参数。
-
apply 则以一种十分优雅的方式,让我们可以根据需求自定义函数并应用,给了数据处理极大的自由度和想象空间。
熟练运用这两大进阶利器,就能够让看似不可能实现的数据处理需求成为现实,让你在 Pandas 数据处理的路上难觅敌手。