第8章 Python 报表自动化
8.1 行业数据报表自动化
案例背景
在另一个平行世界,有一家专注于户外运动的巨头公司。公司旗下有 20 个品牌,这些品牌涉及 128 个类目(行业),涉猎范围之广令人咋舌,可谓遍地开花。
优秀的你,就是这家巨无霸公司的数据分析师,今天刚来公司就接到了老板的需求:下班前务必做一张汇总报表,包含 2023 年销售总额排名前五的品牌以及对应的销售额。
2023 年,前五,这么简单的需求也算需求?直接排个序不就好了,还用一天时间?不急不急,先来一杯咖啡,再看看新闻。
一眨眼的工夫,时间来到了17:30,你觉得今天的需求可以开动了,做完之后再简单分析一下,应该能赶在18:00整点下班。
当你打开同事共享的表格文件(见图 8- 1)时,你才体会到什么叫绝望。
图 8-1 原始数据文件
业务部门的同事总共发来了 128 张表,每张表里是一个细分行业的数据,各类户外服装、垂钓装备、救生装备,应有尽有。
每张表都以月的维度,从 2022 年 1 月到 2023 年 12 月,时间跨度为 2 年,记录着每个品牌的日期、访客数、客单价、转化率、所属类目(细分行业)等数据,如图 8- 2 所示。(很多时候,行业的数据格式就是这样凌乱,当然,因为是平行世界,我们假定 2023 年已经过完。)
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 | |
| 0 | 2023-12 | 品牌-17 | 343731 | 0.030086 | 40 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 1 | 2023-12 | 品牌-12 | 21850 | 0.022896 | 286 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2 | 2023-12 | 品牌-20 | 117047 | 0.076255 | 14 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 3 | 2023-12 | 品牌-13 | 132785 | 0.018543 | 50 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 4 | 2023-12 | 品牌-1 | 37010 | 0.045507 | 54 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
你开始盘算,最终需求是筛选出 2023 年销售总额排名前 5 的品牌,这一摊子数据,对单张表进行分类汇总,能够得到该细分行业各品牌的销售额,想要得到所有行业的销售总额,需要分类汇总 128 次,最后对 128 次结果再次合并。
你清楚地知道,如果手动用 Excel 操作,手会磨破皮不说,时间也绝对不允许。于是,你想起了 Pandas,虽然刚学了基础,还不是很熟练,但事到临头,黑暗中的一缕微光,便是唯一的希望。
用 Python 解决批量问题的核心在于梳理并解决单个问题,然后批量自动循环。
单张表的处理
首先,导入模块,打开单张表:
import pandas as pdimport osos.chdir (r'C:\本书配套资料\第 8 章 Python 报表自动化\相关数据') name
运行代码,得到前 5 行数据的预览:
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 | |
| 0 | 2023-12 | 品牌-17 | 343731 | 0.030086 | 40 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 1 | 2023-12 | 品牌-12 | 21850 | 0.022896 | 286 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2 | 2023-12 | 品牌-20 | 117047 | 0.076255 | 14 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 3 | 2023-12 | 品牌-13 | 132785 | 0.018543 | 50 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 4 | 2023-12 | 品牌-1 | 37010 | 0.045507 | 54 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
其次,汇总不同品牌在这个细分行业下的销售额,我们要汇总的是各品牌 2023 年(2023 年 1 月~2023 年 12 月)的销售额,先看看日期是否正确:
df['日期']-unique ()
选中某一列,然后用 unique()方法就可以得到这一列的去重结果。运行结果如下:
array(['2023- 12','2023- 11','2023- 10','2023- 09','2023- 08','2023- 07','2023- 06','2023- 05','2023- 04','2023- 03','2023- 02','2023- 01','2022- 12','2022- 11','2022- 10','2022- 09','2022- 08','2022- 07','2022- 06','2022- 05','2022- 04','2022- 03','2022- 02','2022- 01'],dtype=object)
为了筛选出 2023 年相关的数据,需要用索引对数据做个筛选:
df_2023=df. loc[df['日期']- str[: 4] == '2023',:] print (df_2023)
运行结果如下:
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 | |
| 0 | 2023-12 | 品牌-17 | 343731 | 0.030086 | 40 | 绑物器 | 垂钓装备& amp; 绑物器 |
| 1 | 2023-12 | 品牌-12 | 21850 | 0.022896 | 286 | 绑物器 | 垂钓装备& amp; 绑物器 |
| 2 | 2023-12 | 品牌-20 | 117047 | 0.076255 | 14 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 3 | 2023-12 | 品牌-13 | 132785 | 0.018543 | 50 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 4 | 2023-12 | 品牌-1 | 37010 | 0.045507 | 54 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 235 | 2023-01 | 品牌-18 | 16487 | 0.024031 | 52 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 236 | 2023-01 | 品牌-19 | 5542 | 0.055630 | 52 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 237 | 2023-01 | 品牌-12 | 4378 | 0.040304 | 71 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 238 | 2023-01 | 品牌-11 | 10898 | 0.020246 | 56 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
| 239 | 2023-01 | 品牌-3 | 36468 | 0.018165 | 18 | 牌钩器 | 垂钓装备& amp; 绑钩器 |
正要汇总销售额,你发现没有销售额的字段,但销售额是可以通过访客数、转化率、客单价三者的乘积来计算的:
df_2023['销售额'] = df_2023['访客数'] * df_2023['转化率'] * df_2023['客单价'] df_2023. head ()
运行结果如下:
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 | 销售额 |
| 0 | 2023-12 | 品牌-17 | 343731 | 0.030086 | 40 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 1 | 2023-12 | 品牌-12 | 21350 | 0.022896 | 286 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2 | 2023-12 | 品牌-20 | 117047 | 0.076255 | 14 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 3 | 2023-12 | 品牌-13 | 132785 | 0.018543 | 50 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 4 | 2023-12 | 品牌-1 | 37010 | 0.045507 | 54 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
按品牌来汇总销售额,得到近一年各品牌的销售总额:
pd. set_option ('display. float_format', lambda x: '%. 2 f' % x) df_sum = df_2023.groupby ('品牌')['销售额']. sum (). reset_index () df_sum.head ()
set_option()的设置是为了让销售额正常显示,否则销售额会因为数值过大而显示科学记数法。运行结果如下:
| 品牌 | 销售额 | |
| 0 | 品牌-1 | 1160411.73 |
| 1 | 品牌-10 | 476567.07 |
| 2 | 品牌-11 | 720308.05 |
| 3 | 品牌-12 | 1069478.32 |
| 4 | 品牌-13 | 955096.04 |
df_sum 的结果是 2023 年绑钩器类目下各品牌的销售总额。需要注意的是,现在我们得到了单表的品牌、销售额数据,最终要整合所有类目的数据,最好加一个类目标签加以区分,这对于后续出了问题进行数据校验和处理临时增加的需求都有帮助。
df_sum['行业'] = name.replace ('. xlsx', '') df_sum.head ()
这样我们得到了如下结果:
| 品牌 | 销售额 | 行业 | |
| 0 | 品牌-1 | 1160411.73 | 垂钓装备& amp; 绑钩器 |
| 1 | 品牌-10 | 476567.07 | 垂钓装备& amp; 绑钩器 |
| 2 | 品牌-11 | 720308.05 | 垂钓装备& amp; 绑钩器 |
| 3 | 品牌-12 | 1069478.32 | 垂钓装备& amp; 绑钩器 |
| 4 | 品牌-13 | 955096.04 | 垂钓装备& amp; 绑钩器 |
到这一步,单张表就已处理完成,只需要把这一系列操作推而广之即可。
批量循环执行
批量操作时,os. listdir()以列表的形式返回了对应文件夹下所有的文件名称,供我们批量循环读取文件名。例如我们想获取文件夹下前 5 张表的名称,可以这样:
print (os. listdir()[: 5])
返回结果如下:
[专理户外运动装备&冰系. x 1 sx',专理户外运动装备&呼吸管- 呼吸器. x 1 sx',专理户外运动装备&安全带. x 1 sx',专理户外运动装备&救生衣. x 1 sx',专理户外运动装备&气瓶. x 1 sx']
批量循环读取文件,并参考上面的单张表处理代码。我们还可以导入 time 库来计时,看一看对于 128 张表,Python 完成这些操作到底能有多快。具体代码如下:
import time #开始时间start
整个过程一气呵成,最近一次运行结果是 4 s,平均一张表用时 0.03 s,何等快速!
为了确保数据正常,来预览一下:
final.head()
运行结果如下:
| 品牌 | 销售额 | |
| 15 | 品牌-5 | 2814286376.98 |
| 8 | 品牌-17 | 2735897004.88 |
| 2 | 品牌-11 | 2617557159.86 |
| 4 | 品牌-13 | 2614862151.29 |
| 3 | 品牌-12 | 2590192538.85 |
期望的结果已经浮现:2023 年销售额排名前五的品牌及其对应的销售额。从数据结果来看,公司旗下的品牌全面开花,以品牌- 5 为先锋,销售额高达 28.14 亿元,排名第 5 的品牌体量也达到了 25.9 亿元,前五品牌的单品牌平均销售额为 26.75 亿元。
“做得不错,不过我以后每周都会关注销售总额排名前五品牌的数据,源数据每周给你一次,表有点多,别被这个需求频率吓到了啊!”老板收到你的结果补充道。
“任务重一点没关系,一定保证完成!”你憋着笑回复他,心里琢磨着:“只要数据格式和需求本质不变,自动化代码已经有了,改改细节就好。别说每周一看,一天两看也不在话下。”
8.2 报表批量处理与品牌投放分析
新的需求背景
一个好消息和一个坏消息。
好消息,你昨天的需求完成得不错,今天一进公司老板就笑脸相迎。
坏消息,他又开口了:“这几年,公司秘密孵化了 50 个品牌,在线上各渠道做了大量品牌宣传,现在要进行复盘。你帮我找到近一年(2023 年)投放效果还不错的品牌,分析分析,年度表彰的时候用。记住,这个现在是机密项目,给你的是所有的数据。”
数据预览
你打开他发来的源数据,如图 8- 3 所示
一共 24 张 Excel 表,按月存储,涵盖了从 2022 年 1 月到 2023 年 12 月的数据。
图 8-3 源数据相关文件
表内部的数据大同小异,打开一张预览一下:
这里的文件夹与上一个案例中的不一样,需要切换 os. chdir(rC:\本节配套资料\第 8 章 Python 报表自动化\投放数据)data
运行结果如下:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50 entries, 0 to 49 Data columns (total 4 columns):# Column Non- Null Count Dtype 0 品牌 50 non- null object 1 品牌搜索人数 50 non- null int 642 点击人数 50 non- null int 643 支付人数 50 non- null int 64 dtypes: int 64 (3), object (1) memory usage: 1.7+ KB 品牌品牌搜索人数点击人数支付人数 0 七喜 6896 3841 1401 万迅 6394 3014 832 东方 16453 11114 14453 九方 53371 36682 9424 佳禾 52686 28308 818 每张表对应一个月的数据,有 50 个品牌,包括品牌、品牌搜索人数、点击人数和支付人数这几个关键字段。
每张表对应一个月的数据,有 50 个品牌,包括品牌、品牌搜索人数、点击人数和支付人数这几个关键字段。
分析思路
目前能够拿到的只有品牌、品牌搜索人数、点击人数和支付人数这几个指标。要找到最近一年投放效果还不错的品牌,可以用漏斗思维,从量级(人数)和效率(转化率)两个角度来考虑,如图 8- 4 所示。
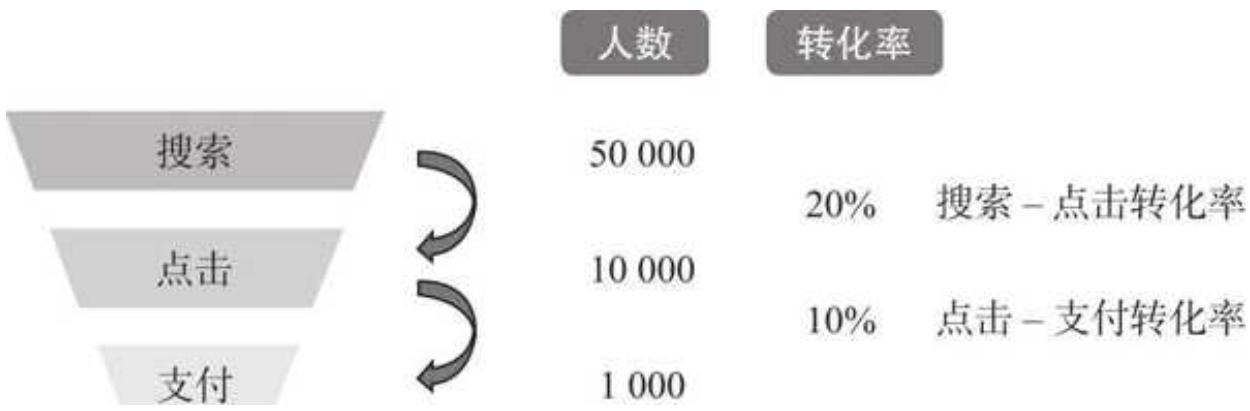
图 8-4 漏斗思维
在费用无差别的情况下:人群基数大(搜索人数),表示投放的心智效果不错,让更多用户看到广告后,在平台主动搜索相关的品牌;搜索- 点击转化率高,代表搜索结果的精准度高,搜索后展示页面的吸引力大等;点击- 支付转化率高,说明用户更有可能受产品详情页面、活动力度等的影响。
理论上,这三个指标越高越好。接下来,我们就结合搜索人数、搜索- 点击转化率和点击- 支付转化率,用 Pandas 做报表并进行分析。
数据处理
要对最近一年的数据进行分析,我们先把 2023 年的所有数据合并,拿到汇总表。核心逻辑依然是遍历读取数据:
final
运行结果如下:
数据行数:600
| 品牌 | 品牌搜索人数 | 点击人数 | 支付人数 | 日期 | |
| 0 | 七喜 | 96885 | 46896 | 4692 | 2023 |
| 1 | 万迅 | 30070 | 21386 | 4393 | 2023 |
| 2 | 东方 | 354060 | 72224 | 7544 | 2023 |
| 3 | 九方 | 244846 | 103363 | 17097 | 2023 |
| 4 | 佳禾 | 6547 | 3257 | 337 | 2023 |
再按品牌的维度进行指标汇总:
gp
运行结果如下:
| 品牌 | 品牌搜索人数 | 点击人数 | 支付人数 | |
| 12 | 双敏 | 1604198 | 571399 | 61244 |
| 3 | 九方 | 1552916 | 712139 | 101217 |
| 20 | 巨奥 | 1417267 | 512847 | 45790 |
| 15 | 商软 | 1002679 | 544392 | 72050 |
| 24 | 戴硕 | 920350 | 540284 | 30371 |
下一步,计算对应的搜索- 点击转化率、点击- 支付转化率:
gp['搜索- 点击转化率
运行结果如下:
| 品牌 | 品牌搜索人数 | 点击人数 | 支付人数 | 搜索-点击转化率 | 点击-支付转化率 | |
| 12 | 双敏 | 1604198 | 571399 | 61244 | 0.36 | 0.11 |
| 3 | 九方 | 1552916 | 712139 | 101217 | 0.46 | 0.14 |
| 20 | 巨奥 | 1417267 | 512847 | 45790 | 0.36 | 0.09 |
| 15 | 商软 | 1002679 | 544392 | 72050 | 0.54 | 0.13 |
| 24 | 戴硕 | 920350 | 540284 | 30371 | 0.59 | 0.06 |
至此,获取了最近一年各品牌的关键指标,基础数据已经完备。
数据分析
从仅有的前 5 条数据可以看到,双敏品牌以 160 万的搜索人数独占鳌头,但是排名第二的九方虽然搜索人数少了 4 万多,却能凭借明显更高的搜索- 点击转化率和点击- 支付转化率,在支付人数上远超双敏,成为支付人数之王。
表格展示略微晦涩,我们用 Matplotlib 来可视化一下:
from matplotlib import pyplot as plt plt. rcParams['font. sans- serif'] = ['SimHei'] %config InlineBackend. figure_format = 'svg' %matplotlib inline
筛选出 TOP 15 的品牌 draw_data
设置画布大小 plt.figure (figsize
筛选对应的 x,y 值和标签名 x
绘制气泡图
plt.scatter (x, y, s=z/1000, c=x, cmap
为每个值打上对应品牌名
for i.txt in enumerate (text): plt.text (x=x[i], y=y[i], s=txt, size=11, horizontalalignment
添加黑色虚线作为水平辅助线
plt.axhline (y=0.12, color='black', linestyle=- - - ', alpha = 0.5)
添加黑色虚线作为垂直辅助线
plt.axvline (x=0.465, color=black', linestyle=- - - ', alpha = 0.5)
plt. xlabel("搜索- 点击转化率")plt. ylabel("点击- 支付转化率")plt. title("TOP 15 品牌搜索分布", size=15)
运行效果如 8- 5 所示。
说明:因为分析背景是无差别投放,所以搜索人数重要性非常高。为了使可视化结果简洁清晰,我们只筛选 TOP 15 品牌来绘图,气泡大小代表着品牌搜索人数的量级。
根据气泡图,我们按照搜索- 点击转化率和点击- 支付转化率的高低划分了 4 个区间。
口右上角的区间 1:高搜索- 点击转化率,高点击- 支付转化率。口左上角的区间 2:低搜索- 点击转化率,高点击- 支付转化率。口左下角的区间 3:低搜索- 点击转化率,低点击- 支付转化率。口右下角的区间 4:高搜索- 点击转化率,低点击- 支付转化率。这时候再结合之前处理的数据结果,用 Excel 条件格式表示,如图 8- 6 所示,可以看得更加清楚。
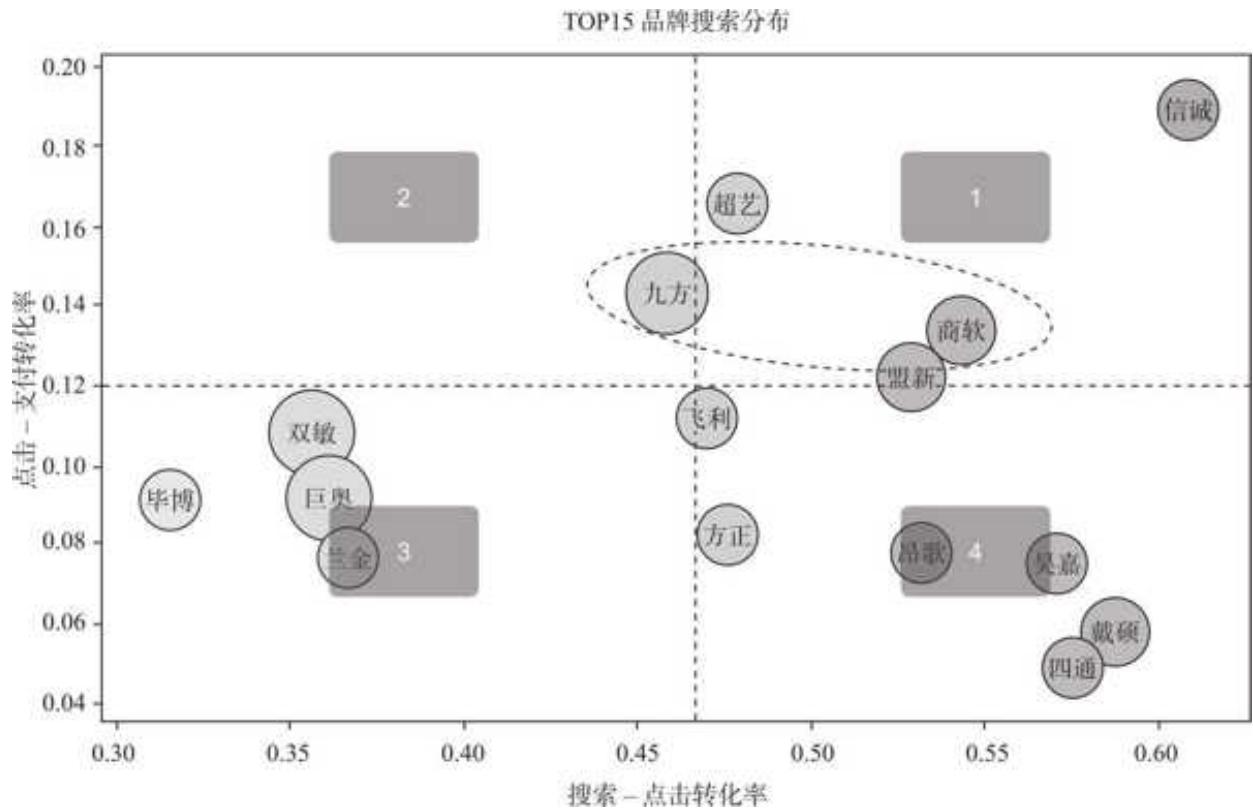
图 8-5 最终运行效果
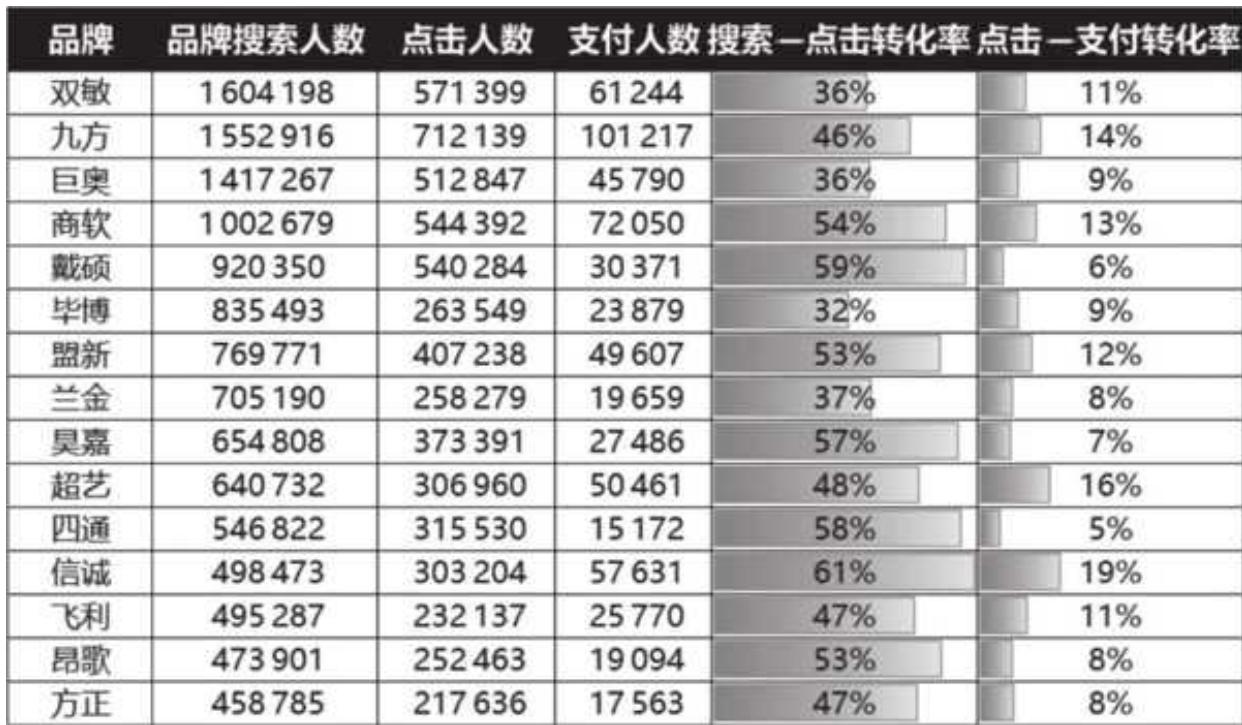
图 8-6 TOP 15 品牌的具体数据
结果显示而易见,高搜索量级的品牌主要呈现出两种形态。
口以双敏(排名第 1)、巨奥(排名第 3)为代表的品牌主要分布在第三区间,量级较大,但两种转化效率均需要进一步提升,品牌没能较好地承接汹涌澎湃的流量。
口九方(排名第 2)、商软(排名第 4)则是高搜索量级、高转化效率的代表,从现有数据看,它们才是年度应该表彰的对象,是大家学习的榜样。
若数据字段更丰富,可以进行更立体的分析,如结合支付人数的金额贡献、留存率、LTV,以及引入两年增速的维度,结合业务动作来定位深层原因。
8.3 本章小结
本章用两个简单又复杂的场景切入,简单是指需求本身并不复杂,而复杂则是基础数据涉及的表格多而杂。
代码和逻辑也不难,主要为了抛出一块砖,帮助敲开大家用批量处理表格的思维藩篱,以引出大家实践中,在合适场景下用 Python 来化繁为简、实现报表自动化的玉。
我们只要明确最本质的需求,抓住“单表突破,批量循环”这个 Python 批量处理数据的要诀,无论需求、数据源如何多变和复杂,都能够轻松解决。