第9章 行业机会分析与权重确定
9.1 案例背景介绍
还记得第 8 章中提到的那个专注于户外运动的巨头公司吗?对,那个旗下有 20 个品牌、涉及 128 个类目(行业)的公司。作为这家公司的数据分析师,你又收到了老板的消息:“有个很重要且紧急的需求,公司准备根据类目发展趋势对资源分配进行重大调整。你帮我看一下,根据上次的数据,有哪些细分行业发展比较好,将来可能有更多的机会。”
你对数据源充满疑惑:“老板,可是我只有我们自己品牌的相关类目数据,看整体类目发展趋势,还要有其他竞争品牌的数据吧?”
老板很轻蔑地说:“这些行业竞争对手不值一提,我们这些品牌的销售额是可以代表整个行业的。不说了,我马上还有个会议。哦,对了,这个需求非常重要。你可以参考之前的思路。”
9.2 传统的解题方法
之前的传统思路
很久以前你曾处理过类似于“哪些细分类目发展趋势好”的需求,那时你刚入职不久,对于这种模糊需求没有什么头绪,你主要抓住了两个重点:
1)采用销售增速作为衡量发展趋势的指标;2)筛选出每个大类目下销售增速最快的细分类目,照顾到每个大类目。最终结果还不错,你从中发现了一些趋势。不过,当时你的所有操作都是基于 Excel 进行的,花了非常长的时间,而现在你可以用 Pandas 来快速实现。
数据预览和汇总
我们的数据依然是之前的 128 张行业数据,每张表都包含日期、品牌、访客数、转化率、客单价、类目等字段,如下所示。
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 |
| 2023-12 | 品牌-17 | 343731 | 0.030085833 | 40 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2023-12 | 品牌-12 | 21850 | 0.022895508 | 286 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2023-12 | 品牌-20 | 117047 | 0.076255288 | 14 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2023-12 | 品牌-13 | 132785 | 0.01854347 | 50 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
| 2023-12 | 品牌-1 | 37010 | 0.045507188 | 54 | 绑钩器 | 垂钓装备& amp; 绑钩器 |
要实现最终的需求,首先需要按照类目和年份来汇总数据。参考第 8 章中批量处理的代码逻辑,只需要调整每个类目下的汇总逻辑即可。
result = pd.DataFrame ()
遍历表格名称
for name in os.listdir (): df $=$ pd. read_excel(name) #提取年度标签 ,即 2022 或 2023 df['年份'] $=$ df['日期']. str[: 4] df['销售额 $\mathrm{\bf\Phi}^{\prime}\mathrm{\bf\Phi}^{\prime}\mathrm{\bf\Phi} = \mathrm{\bf\Phi}$ df['访客数']\*df['转化率']\*df['客单价'] #每个行业 (类目)数据内,按照年度汇总 df_sum $=$ df. groupby('年份')['销售额']. sum(). reset_index() df_sum['类目'] $=$ name. replace('. xlsx',') result $=$ pd.concat ([result, df_sum])
result.head ()
运行结果如下:
| 年份 | 销售额 | 类目 | |
| 0 | 2022 | 7884578.41 | 专项户外运动装备& amp; 冰爪 |
| 1 | 2023 | 30163749.95 | 专项户外运动装备& amp; 冰爪 |
| 0 | 2022 | 7173132.43 | 专项户外运动装备& amp; 呼吸管-呼吸器 |
| 1 | 2023 | 17198793.49 | 专项户外运动装备& amp; 呼吸管-呼吸器 |
| 0 | 2022 | 19393866.43 | 专项户外运动装备& amp; 安全带 |
已经得到了每个类目下 2022 年和 2023 年各自的销售额数据。为了使数据更好处理,这里按照类目和年份做一个透视。
final = pd. pivot_table (result, index = '类目', columns = '年份', values = '销售额', aggfunc = 'sum'). reset_index () final. columns=['类目', '2022 年销售额', '2023 年销售额']print (final)
运行结果如下:
| 类目 | 2022 年销售额 | 2023 年销售额 | ||
| 0 | 专项户外运动装备& amp; 冰爪 | 7884578.41 | 30163749.95 | |
| 1 | 专项户外运动装备& amp; 呼吸管-呼吸器 | 7173132.43 | 17198793.49 | |
| 2 | 专项户外运动装备& amp; 安全带 | 19393866.43 | 66140160.84 | |
| 3 | 专项户外运动装备& amp; 救生衣 | 23820417.15 | 98807893.65 | |
| 4 | 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | |
| ... | ... | ... | ... | ... |
| 123 | 防护-救生装备& amp; 防护面罩 | 3464970.97 | 11843236.83 | |
| 124 | 防潮垫-地席-枕头& amp; 地布-地席 | 3828998.31 | 12738643.79 | |
| 125 | 防潮垫-地席-枕头& amp; 枕头 | 52704583.51 | 214983856.48 | |
| 126 | 防潮垫-地席-枕头& amp; 防潮垫 | 64294811.64 | 260637588.07 | |
| 127 | 防潮垫-地席-枕头& amp; 防潮垫-地席-枕头 | 114956693.58 | 434554583.83 |
每个类目增长最快的细分类目
看每个细分类目的增长,首先要计算出增速。
final['销售增速'] = (final['2023 年销售额'] - final['2022 年销售额']) / final['2022 年销售额']final.head ()
运行结果如下:
| 类目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | |
| 0 | 专项户外运动装备& amp; 冰爪 | 7884578.41 | 30163749.95 | 2.83 |
| 1 | 专项户外运动装备& amp; 呼吸管-呼吸器 | 7173132.43 | 17198793.49 | 1.40 |
| 2 | 专项户外运动装备& amp; 安全带 | 19393866.43 | 66140160.84 | 2.41 |
| 3 | 专项户外运动装备& amp; 救生衣 | 23820417.15 | 98807893.65 | 3.15 |
| 4 | 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | 3.51 |
为了方便排序,提取出大类目和对应的细分类目,这里按照类目字段的&分隔符来提取。
final['大类目'] = final['类目']. str.split (&'). str[0]final['细分类目'] = final['类目']. str.split (&'). str[1]final.head ()
把类目字段按照&符号切分成两段,大类目取前面的字段,细分类目则取后面的字段,结果如下:
| 类目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 大类目 | 细分类目 | |
| 0 | 专项户外运动装备& amp; 冰爪 | 7884578.41 | 30163749.95 | 2.83 | 专项户外运动装备 | 冰爪 |
| 1 | 专项户外运动装备& amp; 呼吸管-呼吸器 | 7173132.43 | 17198793.49 | 1.40 | 专项户外运动装备 | 呼吸管-呼吸器 |
| 2 | 专项户外运动装备& amp; 安全带 | 19393866.43 | 66140160.84 | 2.41 | 专项户外运动装备 | 安全带 |
| 3 | 专项户外运动装备& amp; 救生衣 | 23820417.15 | 98807893.65 | 3.15 | 专项户外运动装备 | 救生衣 |
| 4 | 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | 3.51 | 专项户外运动装备 | 气瓶 |
接下来,为了筛选出每个大类目下增速最快的细分类目,先按照每个大类目下细分类目的销售增速进行降序排列:
r = final. sort_values (['大类目', '销售增速'], ascending = False)r.head ()
运行结果如下:
| 类目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 大类目 | 细分类目 | |
| 125 | 防潮垫-地头& amp; 枕头& amp; 枕头 | 52704383.51 | 214983836.48 | 3.08 | 防潮垫-地头-枕头 | 枕头 |
| 126 | 防潮垫-地席-枕头& amp; 防潮垫 | 64294811.64 | 260637588.07 | 3.05 | 防潮垫-地席-枕头 | 防潮垫 |
| 127 | 防潮垫-地头& amp; 防潮垫-地席-枕头 | 114956693.58 | 434554583.83 | 2.78 | 防潮垫-地席-枕头 | 防潮垫-地席-枕头 |
| 124 | 防潮垫-地席-枕头& amp; 地头-地席 | 3828998.31 | 12738643.79 | 2.33 | 防潮垫-地席-枕头 | 地市-地席 |
| 122 | 防护-救生装备& amp; 防护-救生装备 | 103906995.09 | 516112688.85 | 3.97 | 防护-救生装备 | 防护-救生装备 |
最后,筛选出每个大类目下增速排序第一的数据即可。用 groupby()和 head()的组合,十分方便。
r.groupby ('大类目'). head (1)
结果如图 9-1 所示
| 类目 2022 年销售额 2023 年销售额销售增速 | 大类目 | 细分类目 | |||
| 防潮垫-地基-枕头& amp; 枕头 | 52704583.51 | 21498356.48 | 3.08 | 防潮垫-地基-枕头 | 枕头 |
| 防护-救生装备& amp; 防护-救生装备 | 103906995.09 | 516112688.85 | 3.97 | 防护-救生装备 | 防护-救生装备 |
| 睡袋& amp; 睡袋 | 193959076.88 | 594014206.98 | 2.06 | 睡袋 | 睡袋 |
| 登山杖-手杖& amp; 登山杖-手杖 | 77763133.79 | 295317365.32 | 2.80 | 登山杖-手杖 | 登山杖-手杖 |
| 洗漱清洁-护理用品& amp; 防虫-防蚊用品 | 223484997.36 | 75632462.16 | 2.22 | 洗漱清洁-护理用品 | 防虫-防蚊用品 |
| 望远镜-夜视仪-户外眼镜& amp; 望远镜-夜视仪-户外眼镜 | 220271388.35 | 1025433112.52 | 3.66 | 望远镜-夜视仪-户外眼镜 | 望远镜-夜视仪-户外眼镜 |
| 旅行便携装备& amp; 晾衣绳 | 4306504.60 | 18455947.82 | 3.29 | 旅行便携装备 | 晾衣绳 |
| 户外鞋靴& amp; 滑雪鞋-雪地靴 | 79046497.00 | 364683981.78 | 3.61 | 户外鞋靴 | 滑雪鞋-雪地靴 |
| 户外照明& amp; 营地灯-帐篷灯 | 21839003.61 | 104666693.76 | 3.79 | 户外照明 | 营地灯-帐篷灯 |
| 户外服装& amp; 抓绒衣 | 101650296.49 | 454712444.95 | 3.47 | 户外服装 | 抓绒衣 |
| 户外休闲家具& amp; 户外桌椅套 | 14235575.41 | 66832433.35 | 3.69 | 户外休闲家具 | 户外桌椅套装 |
| 垂钓装备& amp; 鱼钩 | 55895341.31 | 299165733.63 | 4.35 | 垂钓装备 | 鱼钩 |
| 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | 3.51 | 专项户外运动装备 | 气瓶 |
图 9-1 筛选出的细分趋势类目
根据上一步大类目- 销售增速排序后的结果,用 groupby(‘大类目’). head(1)得到每个大类目分组下排序第一的细分类目,并返回数据本身,即每个大类目下增速排名第一的细分类目。
9.3 权重确定方法
对于“有哪些细分类目发展比较好”的需求,能不能为销售额、增速等关键指标赋予不同的权重,最终计算出一个类似于发展指数的综合指标呢?答案是肯定的。
在这一节,我们先了解有哪些确定权重的方法。
级别法
级别法,即根据自己的经验和主观判断来决定权重大小。它也常叫作拍脑袋法,可以说是实际中最常用的权重确定方法了。
举个例子,假如某业务方要做一个分析,涉及确定 2022 年和 2023 年各自年份销售额的权重,应该定多少合适呢?
实习生级别:“我觉得 2023 年是更近的年份,对现在的影响更大,应该权重更高,因此 2022 年权重可以是 0.4,2023 年权重是 0.6。”
业务方:“你没什么经验,不能太主观了,为什么 2023 年的权重是 0.6,而不是 0.65?”
专家级别:“之前有过类似的场景,2022 年和 2023 年权重分别是 0.4 和 0.6,在这里可以沿用。”
业务方:“我记不太清之前是怎么确定的,不过既然有过往经验,也可以用起来。”
老板级别:“基于我的多年行业经验和二八法则等经典理论,我认为,2022 年和 2023 年增速的权重,就应该是 0.4 和 0.6。”
业务方:“既然是老板说的,一定有他的专业判断,0.4 和 0.6 看上去非常科学。”
之所以我把这种方法叫作级别法,是因为级别法的效果很容易受使用者级别的影响,且级别越高越不容易被质疑。上面的例子便是明证。
权值因子判表法
权值因子判表法也属于主观赋权法的一种。但这种方法在专家意见、多方权衡和相对量化等方面有一定的优势,结论的可信度也更高。
举一个具体的案例:要找对象,相貌、身材、涵养、家庭背景的重要度应该怎么量化和排序?婚恋公司召集了 4 个极其权威的情感专家,要通过权值因子判表法来解决这个问题。
首先,结合 4 个考量维度,为每个专家制定判表,如图 9- 2 所示。
其次,把每张表分发至专家,让其独立完成打分。打分逻辑很简单,用行的属性和列的属性做比较,如果认为行属性比对应的列属性更重要,则填上 1,否则填 0,如图 9- 3 所示。
| 专家 1 | 相貌 | 身材 | 涵养 | 家庭背景 |
| 相貌 | ||||
| 身材 | ||||
| 涵养 | ||||
| 家庭背景 |
| 专家 2 | 相貌 | 身材 | 涵养 | 家庭背景 | |
| 相貌 | |||||
| 身材 | |||||
| 涵养 | |||||
| 家庭背景 | |||||
| 专家 3 | 相貌 | 身材 | 涵养 | 家庭背景 | |||||
| 相貌 | |||||||||
| 身材 | |||||||||
| 涵养 | |||||||||
| 家庭背景 | 专家 4 | 相貌 | 身材 | 涵养 | 家庭背景 | ||||
| 相貌 | 相貌 | ||||||||
| 身材 | 身材 | ||||||||
| 涵养 | 涵养 | ||||||||
| 家庭背景 | 家庭背景 |
图 9-2 打分表样例
| 专家 4 | 相貌 | 身材 | 涵养 | 家庭背景 | |
| 相貌 | |||||
| 身材 | |||||
| 涵养 | |||||
| 家庭背景 |
| 专家 1 | 相貌 | 身材 | 涵养 | 家庭背景 |
| 相貌 | →1 | 0 | 0 | |
| 身材 | 0 | 0 | 0 | |
| 涵养 | 1 | 1 | 1 | |
| 家庭背景 | 1 | 1 | 0 |
图 9-3 单张打分表释义
这些属性不会和自身相比,所以对角线一栏是空值。我们重点对右上角区域进行打分,因为左下角的打分是右上角的逻辑对称(但也会参与计算)。
比如认为相貌比身材重要,打 1 分,与之对应,在身材和相貌对比的单元格打 0 分。
根据专家 1 的打分表,他认为:
口相貌比身材重要,但没有涵养和家庭背景重要;
口身材自然也没有涵养和家庭背景重要;
口涵养比家庭背景重要。
综合来看,专家 1 认为,涵养
其他专家打分的逻辑也一样。打完分后我们行向求和,得到每位的分值汇总,如图 9- 4 所示。
最后,结合 4 位专家的打分,求平均分。例如,相貌平均分如图 9- 5 所示。
求其他平均分的逻辑完全一样。最终,求得身材、涵养、家庭背景的平均分分别是 2、2.25 和 0.75。
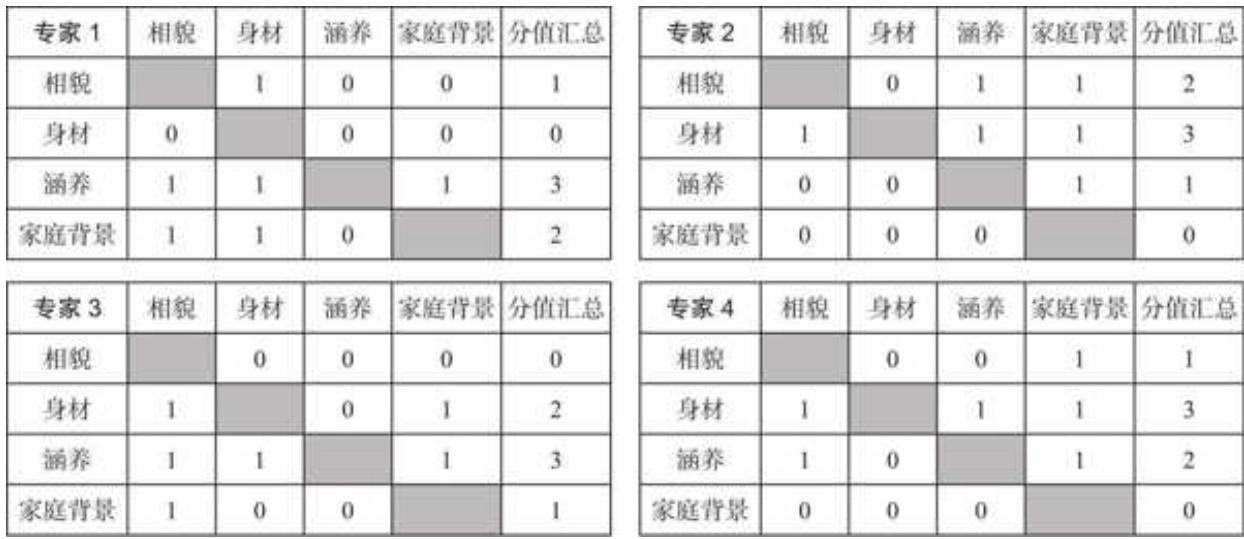
图 9-4 专家打分结果

图 9-5 相貌平均分
由于权重之和一般是 1,计算各属性对应的权重时,用其平均分除以平均分之和即可,如图 9- 6 所示。
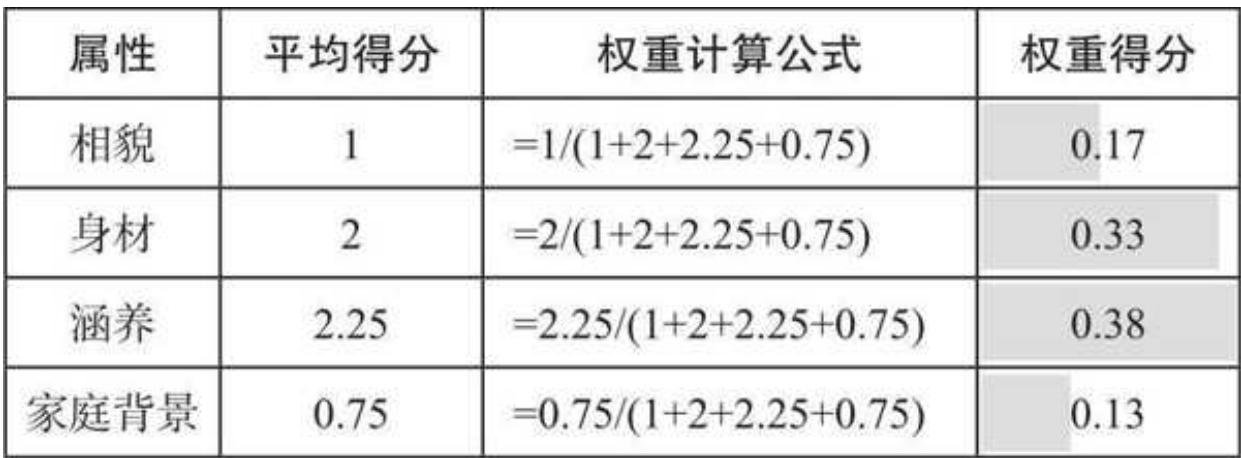
图 9-6 各维度打分逻辑及结果
可见,对于这 4 位专家而言,4 个维度的重要度排序是涵养
变异系数法
变异系数法是一种常见的客观赋权法,其核心逻辑是用数据波动来确定权重。变异系数的计算很简单,就是用标准差除以平均值。变异系数越大,则数据的偏离程度越大。
变异系数法的思想中,某个指标偏离程度越大,说明该指标越难以实现,因此它是反映所评对象差距的关键指标,应被赋予更高的权重。
我们拿到了一份成绩单,如图 9- 7 所示,如何通过变异系数法来确定各科的权重呢?
图 9-7 成绩单样例
| 学生编号 | 语文 | 数学 | 英语 | 体育 |
| 001 | 58 | 84 | 55 | 76 |
| 002 | 79 | 58 | 91 | 64 |
| 003 | 53 | 73 | 73 | 75 |
| 004 | 69 | 65 | 61 | 71 |
| 005 | 68 | 77 | 50 | 91 |
| 006 | 70 | 93 | 58 | 50 |
| 007 | 85 | 83 | 95 | 68 |
| 008 | 100 | 78 | 64 | 92 |
| 009 | 55 | 56 | 90 | 52 |
| 010 | 89 | 85 | 65 | 58 |
| ... | ||||
先计算各科的平均数、标准差,然后用标准差除以平均数来计算出变异系数,即变异系数
| 科目 | 平均数 | 标准差 | 变异系数 |
| 语文 | 75.78 | 13.63 | 0.18 |
| 数学 | 76.22 | 12.60 | 0.17 |
| 英语 | 72.44 | 15.46 | 0.21 |
| 体育 | 74.11 | 13.93 | 0.19 |
图 9-8 变异系数的计算
然后求各科变异系数值的占比,即权重,如图 9- 9 所示。例如,语文权重
| 科目 | 平均数 | 标准差 | 变异系数 | 权重 |
| 语文 | 75.78 | 13.63 | 0.18 | 24% |
| 数学 | 76.22 | 12.60 | 0.17 | 22% |
| 英语 | 72.44 | 15.46 | 0.21 | 29% |
| 体育 | 74.11 | 13.93 | 0.19 | 25% |
图 9-9 变异系数法的权重值计算
这样,我们通过变异系数法求得了各科的权重,也知道了英语成绩是这次拉开差异的主要科目。
除了上面介绍的几种权重确定方法,还有 AHP 层次分析法、熵权法、复相关系数法等诸多权重确定方法。受限于篇幅,这里不一一介绍,感兴趣的读者可以根据关键词查阅资料来进一步了解。
9.4 Pandas 权重计算和分析
回到本章最开始的那个需求:“有哪些细分类目发展比较好,将来可能有更多的机会呢?”
我们用 Pandas 来实现权重的计算和结果输出,最终用一个综合发展指数来量化细分类目的发展机会。
数据整合
整合数据之前,先确定要把哪些指标纳入赋权计算的范围。基于现有数据,到底哪些指标与行业发展机会更相关呢?
口销售额。销售额代表了行业的市场容量和规模,规模越大,说明市场蛋糕越大,这里我们取 2022 年和 2023 两年的销售额。
口销售增速。销售增速的大小直接对应着发展速度快慢,可以取 2023 年较 2022 年销售额的增速。
口客单价。客单价的高低和行业的利润空间、品牌溢价能力等密切相关。客单价是辅助量化指标,因此可以只取 2023 年的客单价数据。
至于访客数、转化率这两个和运营强相关的指标,可以暂时先放一放。
在 9.2 节中,合并聚合的结果 result 变量只有"销售额"字段。要计算我们所需的多个相关指标,需要先把所有的行业类目数据重新合并。这次我们采取直接遍历数据合并而不聚合的方式,代码如下:
result 2 $=$ pd. DataFrame()
# 循环遍历表格名称
for name in os. listdir():
df $=$ pd. read_excel(name)
# 摄取年度标签
df['年份'] $=$ df['日期']. str[: 4]df['销售额'] $=$ df['访客数']\*df['转化率']\*df['客单价']result 2 $=$ pd.concat ([result 2, df])
# result 2
运行结果如下:
| 日期 | 品牌 | 访客数 | 转化率 | 客单价 | 三级类目 | 详细类目 | 年份 | 销售额 | |
| 0 | 2023-12 | 品牌-14 | 9348 | 0.06 | 134 | 冰瓜 | 专用户外运动装备& amp; 冰瓜 | 2023 | 76284.02 |
| 1 | 2023-12 | 品牌-20 | 1187 | 0.05 | 1244 | 冰瓜 | 专用户外运动装备& amp; 冰瓜 | 2023 | 70864.93 |
| 2 | 2023-12 | 品牌-4 | 10432 | 0.05 | 97 | 冰瓜 | 专用户外运动装备& amp; 冰瓜 | 2023 | 49795.12 |
| 3 | 2023-12 | 品牌-13 | 4648 | 0.02 | 428 | 冰瓜 | 专用户外运动装备& amp; 冰瓜 | 2023 | 48722.98 |
| 4 | 2023-12 | 品牌-18 | 3977 | 0.06 | 71 | 冰瓜 | 专用户外运动装备& amp; 冰瓜 | 2023 | 16167.85 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 475 | 2022-01 | 品牌-15 | 17998 | 0.03 | 220 | 防潮垫 | 防潮垫-地墻-枕头& amp; 防潮垫 | 2022 | 124890.09 |
| 476 | 2022-01 | 品牌-1 | 22670 | 0.01 | 615 | 防潮垫 | 防潮垫-地墻-枕头& amp; 防潮垫 | 2022 | 108152.84 |
| 477 | 2022-01 | 品牌-11 | 41793 | 0.07 | 35 | 防潮垫 | 防潮垫-地墻-枕头& amp; 防潮垫 | 2022 | 105467.83 |
| 478 | 2022-01 | 品牌-7 | 29124 | 0.04 | 96 | 防潮垫 | 防潮垫-地墻-枕头& amp; 防潮垫 | 2022 | 102735.96 |
| 479 | 2022-01 | 品牌-8 | 13169 | 0.04 | 140 | 防潮垫 | 防潮垫-地墻-枕头& amp; 防潮垫 | 2022 | 68046.68 |
| 61440 rows × 9 columns | |||||||||
以上得到了所有细分类目数据的整合结果,一共 61440 行数据。
关键指标计算
1. 销售额和销售增速
在 9.2 节中,我们已经计算出了每个细分类目 2022 年和 2023 年的销售额及增速,查看一下:
final.head ()
运行结果如下:
| 项目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 大类目 | 细分类目 | |
| 0 | 专项户外运动装备& amp; 冰爪 | 7884578.41 | 30163749.95 | 2.83 | 专项户外运动装备 | 冰爪 |
| 1 | 专项户外运动装备& amp; 呼吸管-呼吸器 | 7173132.43 | 17198793.49 | 1.40 | 专项户外运动装备 | 呼吸管-呼吸器 |
| 2 | 专项户外运动装备& amp; 安全带 | 19393866.43 | 66140160.84 | 2.41 | 专项户外运动装备 | 安全带 |
| 3 | 专项户外运动装备& amp; 救生衣 | 23820417.15 | 98807893.65 | 3.15 | 专项户外运动装备 | 救生衣 |
| 4 | 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | 3.51 | 专项户外运动装备 | 气瓶 |
2. 计算客单价
在整合的 result 2 里,有每一个细分类目是每月的客单价数据,但要计算整年的客单价,还要从客单价公式入手。
口客单价
口购买人数
所以,年度客单价
计算每个月的购买人数 result 2['购买人数'] = result 2['访客数'] * result 2['转化率']# 每个类目,按年份汇总,计算对应的年度销售额、年度购买人数 item_gp = result 2.groupby (['详细类目', '年份']) '销售额', '购买人数'. sum (). reset_index ()# 计算年度客单价 item_gp['客单价'] = item_gp['销售额'] / item_gp['购买人数']# 最终客单价,根据需求,只取 2023 年的 item_gp = item_gp. loc[item_gp['年份'] == '2023', :]item_gp.head ()
运行结果如下:
| 详细类目 | 年份 | 销售额 | 购买人数 | 客单价 | |
| 1 | 专项户外运动装备& amp; 冰爪 | 2023 | 30163749.95 | 310832.84 | 97.04 |
| 3 | 专项户外运动装备& amp; 呼吸管-呼吸器 | 2023 | 17198793.49 | 136986.67 | 125.55 |
| 5 | 专项户外运动装备& amp; 安全带 | 2023 | 66140160.84 | 303756.40 | 217.74 |
| 7 | 专项户外运动装备& amp; 救生衣 | 2023 | 98807893.65 | 445640.13 | 221.72 |
| 9 | 专项户外运动装备& amp; 气瓶 | 2023 | 36317479.97 | 33514.51 | 1083.63 |
我们拿到了每个细分类目的 2023 年客单价数据,下一步是将销售额、增速和客单价数据进行整合。用 merge()方法将两者合并,进一步提取我们所需的字段。
final 表的类目和 item_gp 表的详细类目是一样的
final_new = pd.merge (final, item_gp, left_on = '类目', right_on = '详细类目', how = 'inner') #提取合并后的关键指标final_new = final_new['类目', '2022 年销售额', '2023 年销售额', '销售增速', '客单价']final_new.head ()
运行结果如下:
| 类目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 客单价 | |
| 0 | 专项户外运动装备& amp; 冰爪 | 7884578.41 | 30163749.95 | 2.83 | 97.04 |
| 1 | 专项户外运动装备& amp; 呼吸器-呼吸器 | 7173132.43 | 17198793.49 | 1.40 | 125.55 |
| 2 | 专项户外运动装备& amp; 安全带 | 19393866.43 | 66140160.84 | 2.41 | 217.74 |
| 3 | 专项户外运动装备& amp; 救生衣 | 23820417.15 | 98807893.65 | 3.15 | 221.72 |
| 4 | 专项户外运动装备& amp; 气瓶 | 8052409.00 | 36317479.97 | 3.51 | 1083.63 |
权重的计算
1. 变异系数法
根据变异系数法,我们需要计算每个指标的平均值和标准差。利用 describe()方法可以直接计算出相关指标:
final_new.describe ()
运行结果如下:
| 2022 年销售额 | 2023 年销售额 | 销售增速 | 客单价 | |
| count | 128.00 | 128.00 | 128.00 | 128.00 |
| mean | 105009765.18 | 389253544.32 | 2.79 | 245.77 |
| std | 231216148.93 | 863806475.71 | 0.61 | 251.62 |
| min | 589492.92 | 2094447.84 | 1.40 | 18.37 |
| 25% | 8931205.15 | 32890176.12 | 2.40 | 77.96 |
| 50% | 27727218.81 | 113122708.51 | 2.80 | 153.08 |
| 75% | 90346726.97 | 371512115.05 | 3.20 | 321.37 |
| max | 1535788007.33 | 6578928834.59 | 4.35 | 1615.38 |
基本统计指标都已经计算好了,这里只需要提取平均值和标准差,所以把数据转置,然后提取 mean 和 std 列:
cov = final_new.describe (). T [['mean', 'std']]. print (cov)
运行结果如下:
| mean | std | |
| 2022 年销售额 | 105009765.18 | 231216148.93 |
| 2023 年销售额 | 389253544.32 | 863806475.71 |
| 销售增速 | 2.79 | 0.61 |
| 客单价 | 245.77 | 251.62 |
再补充变异系数列,并根据变异系数的大小求出权重:
计算每个指标的变异系数 ```
cov['cov'] = cov['std'] / cov['mean']# 根据变异系数占比得到实际权重 cov['cov_pct'] = cov['cov'] / cov['cov']. sum () cov
运行结果如下:
| mean | std | cov | cov_pct | |
| 2022 | 105009765.18 | 231216148.93 | 2.20 | 0.39 |
| 2023 | 389253544.32 | 863806475.71 | 2.22 | 0.39 |
| 销售增速 | 2.79 | 0.61 | 0.22 | 0.04 |
| 客单价 | 245.77 | 251.62 | 1.02 | 0.18 |
基于变异系数法,求得 2022 年和 2023 年销售额权重都是 0.39,销售增速权重是 0.04,2023 年客单价权重则是 0.18。
大家想一想,如果这样的权重值最终被采用,站在业务人员的角度看,会不会有问题?
尽管你告诉业务人员这是通过相对科学的客观赋权法得到的值,但大概率他还是会有以下质疑。
口 2023 年和 2022 年销售额的权重为什么一样?越近的年份销售额对我们来说参考价值越大才对。
口销售增速权重太低,要知道增速是一个直接反映趋势的指标。
口客单价作为一个辅助性的判断指标,权重竟然远高于销售增速,不符合业务逻辑。
所以,接下来我们尝试用权值因子判表法做一个对比。
2. 权值因子判表法
制定好了打分表,并找需求相关部门的 5 个重要角色打分,最终拿到了 5 位专家的打分表。我们用 Pandas 读取,代码如下:
data = pd. read_excel ('专家打分表. xlsx') data.head (8)
结果如图 9- 10 所示。
| 专家编号 | 关键指标 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 客单价 |
| 0 | 1 | 2022 年销售额 | NaN | 0.00 | 0.00 |
| 1 | 1 | 2023 年销售额 | 1.00 | NaN | NaN |
| 2 | 1 | 销售增速 | 1.00 | 1.00 | NaN |
| 3 | 1 | 客单价 | 0.00 | 0.00 | NaN |
| 4 | 2 | 2022 年销售额 | NaN | 0.00 | 0.00 |
| 5 | 2 | 2023 年销售额 | 1.00 | NaN | 0.00 |
| 6 | 2 | 销售增速 | 1.00 | 1.00 | NaN |
| 7 | 2 | 客单价 | 1.00 | 0.00 | NaN |
要计算 5 位专家给每个维度的打分,先横向汇总每一行的得分情况,再分别按照 4 个指标分组求平均即可。
把空缺值用 0 填充,否则汇总值也会是
NaNdata.fillna (0, inplace = True)# 计算每一行的汇总值 data['分值汇总'] = data['2022 年销售额'] + data['2023 年销售额'] + data['销售增速'] + data['客单价']# 按照 2022 年销售额、2023 年销售额、增速、客单价四个指标分组,并统计汇总分值的平均分 data_gp = data.groupby ('关键指标')['分值汇总']. mean (). reset_index () print (data_gp)
运行结果如下:
关键指标分值汇总 0 2022 年销售额 0.801 2023 年销售额 2.202 客单价 0.203 销售增速 2.80
再根据分值汇总结果计算各自的占比,得到最终权重。
这里的权重即分值汇总数值的占比 data_gp['权重'] = data_gp['分值汇总'] / data_gp['分值汇总']. sum () print (data_gp) 运行结果如下:
运行结果如下:
关键指标分值汇总权重 0 2022 年销售额 0.80 0.131 2023 年销售额 2.20 0.372 客单价 0.20 0.033 销售增速 2.80 0.47
综合 5 位专家的意见,对于行业发展趋势来说,4 个指标的重要度排序是销售增速
这个结果值更符合业务逻辑,我们用权值因子判表法的权重结果进行后续计算。
数据标准化
各指标的权重已定,一般来说,只需要用各自的数值乘以权重,最终加总即可。但是,我们拿到的行业数据存在很严重的数据量级差异,销售额是千万元级别,而销售增速最多也只是个位数,客单价则是几百到几千元。量级差异过大,会导致权重没有任何意义。因此,我们需要先将数据标准化和去量纲。
这里我们介绍一种常用的最大最小值归一化法,它的计算公式为(对应列某个值- 列最小值)/(列最大值- 列最小值)。该公式把对应列所有的值都压缩在
用 Pandas 来实现,代码如下:
每一个指标都套用了上面的法量纲公式
final_new['2022_mms'] $=$ (final_new['2022 年销售额']- final_new['2022 年销售额']min()/(final_new['2022 年销售额']- max()- final_new['2022 年销售额']- min())final_new['2023_mms'] $=$ (final_new['2023 年销售额']- final_new['2023 年销售额']- min())min()/(final_new['2023 年销售额']- max()- final_new['2023 年销售额']- min())final_new['销售增速_mms'] $=$ (final_new['销售增速']- final_new['销售增速']- min())(final_new['销售增速']- max()- final_new['销售增速']- min())final_new['客单价_mms'] $=$ (final_new['客单价']- final_new['客单价']- min())/(final_new['客单价']- max()- final_new['客单价']- min())接 2023 年销售额排序,查看值与条结果 final_new. sort_values('2023 年销售额', ascending $=$ False). head()
运行结果如图 9- 11 所示
可以看到,目前所有关键指标的量纲都得到了统一。
| 类目 | 2022 年销售额 | 2023 年销售额 | 销售增速 | 客单价 | 2022_mms | 2023_mms | 销售增速 _mms | 客单价 _mms | |
| 67 | 户外服装& amp; 户外服装 | 1535788007.33 | 6578928834.59 | 3.28 | 405.94 | 1.00 | 1.00 | 0.64 | 0.24 |
| 17 | 垂钓装备& amp; 垂钓装备 | 1263322207.67 | 4530217246.31 | 2.59 | 107.43 | 0.82 | 0.69 | 0.40 | 0.06 |
| 95 | 户外鞋靴& amp; 户外鞋靴 | 1174675113.88 | 3554767358.42 | 2.03 | 423.33 | 0.76 | 0.54 | 0.21 | 0.25 |
| 31 | 垂钓装备& amp; 钓竿 | 666732975.43 | 3053970690.23 | 3.58 | 293.47 | 0.43 | 0.46 | 0.74 | 0.17 |
| 58 | 户外服装& amp; 冲锋衣 | 913619579.64 | 2826169162.98 | 2.09 | 557.40 | 0.59 | 0.43 | 0.24 | 0.34 |
综合发展指数
要计算综合发展指数,只需要把对应的数值乘以权重并加总即可。
每个归一化后的值乘以之前计算的对应权重
final_new['综合发展指数'] = final_new['2022_mms'] * 0.13 + final_new['2023_mms'] * 0.37 + final_new['销售增速_mms'] * 0.47 + final_new['签单价_mms'] * 0.03 按综合指数排序查看前 10 的细分类目,为了简化展示,只提取了几个关键字段,没有取归一化的结果 final_new. sort_values ('综合发展指数', ascending = False) ['类目', '2022 年销售额', '2023 年销售额', '销售增速', '签单价', '综合发展指数'] hadd (10)
代码执行结果如图 9- 12 所示
| 类目 2022 年销售额 | 2023 年销售额 | 销售增速 | 客单价 | 综合发展指数 | ||
| 67 | 户外服装 & amp; 户外服装 | 1535788007.33 | 6578928834.59 | 3.28 | 405.94 | 0.81 |
| 31 | 垂钓装备 & amp; 钓竿 | 666732975.43 | 3053970690.23 | 3.58 | 293.47 | 0.58 |
| 17 | 垂钓装备 & amp; 垂钓装备 | 1263322207.67 | 4530217246.31 | 2.59 | 107.43 | 0.55 |
| 45 | 垂钓装备 & amp; 鱼钩 | 55895341.31 | 299165733.63 | 4.35 | 42.54 | 0.49 |
| 122 | 防护-救生装备 & amp; 防护-救生装备 | 103906995.09 | 516112688.85 | 3.97 | 88.71 | 0.45 |
| 42 | 垂钓装备 & amp; 鱼线 | 103102216.89 | 512039937.97 | 3.97 | 50.67 | 0.45 |
| 111 | 望远镜-夜视仪-户外眼镜 & amp; 望远镜-夜视仪-户外眼镜 | 220271388.35 | 1025433112.52 | 3.66 | 357.62 | 0.44 |
| 43 | 垂钓装备 & amp; 鱼线轮 | 205590742.05 | 955452386.15 | 3.65 | 434.42 | 0.44 |
| 26 | 垂钓装备 & amp; 浮漂 | 104103534.51 | 502844205.49 | 3.83 | 69.13 | 0.42 |
| 74 | 户外服装 & amp; 羽绒衣 | 512927562.77 | 1994130010.74 | 2.89 | 1615.38 | 0.42 |
图 9-12 权重结果
由上面的结果不难发现,户外运动行业具有以下发展特点。
无服装,不户外。一旦大家想户外,首先要解决的是服装问题。户外服装凭借高销售规模、高增长成为最具潜力的细分类目。
钓鱼是户外运动的王者。发展趋势前 10 的细分类目,有 6 个是与垂钓装备相关的,这个行业需要重点关注。
9.5 本章小结
权重的确定方法有很多,如级别法、权值因子判表法、变异系数法等,既有主观赋权法,也有客观赋权法。
在确定各指标的权重之后,综合指标的计算一定要考虑量纲的差异,如果量级差异过大,需要先去量纲再汇总计算。
最后,我想强调和补充的是,在实际工作中,权重与综合指数的应用效果,除了计算方法的科学性,还有两个非常重要的特性一定要注意。
口业务可理解性。如果是复杂的权重计算模型,一定要用简要的话来提炼,最好做到一句话让业务人员明白。因为他们的理解程度会影响最终策略和建议能否落地。
口是否符合业务逻辑。正如上面的案例所示,用客观赋权的变异系数法最终得到的权重可能符合数据规律,但和实际业务或者商业逻辑相悖,很容易受到抵触。权重的计算只有和业务逻辑相契合,才能顺利推动。毕竟,能推动业务的分析,才是好的分析。