第10章 用户分层实战
10.1 用户分层的基本概念
无处不在的用户分层
用户分层,顾名思义,是把用户按照一定的规则划分成不同的层级,如图 10- 1 所示。
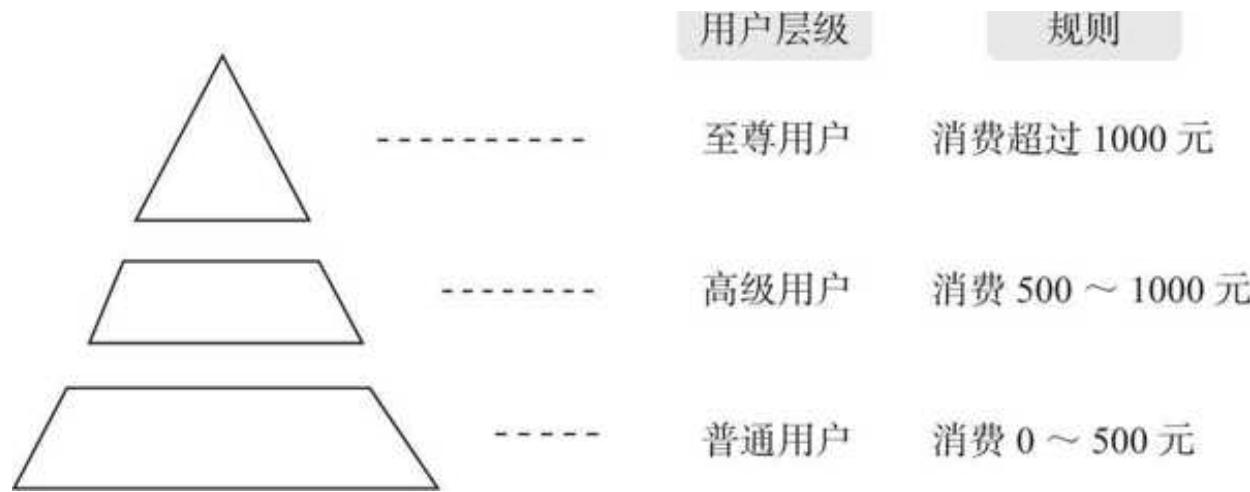
图 10-1 用户分层示例
想玩游戏了,打开《王者荣耀》,看到新出的英雄皮肤效果炫酷,忍不住充值购买,系统提示我的 VIP 等级提升了,从 V 6 升级到尊贵的 V 7。不过,之后因为我一段时间没有消费,等级又退回到了 V 6。
想买双鞋了,找到某品牌天猫旗舰店,轻车熟路地点开店铺会员中心,因为我已经是铂金等级的会员,每月能领取一张满 500- 50 的优惠券。再消费 3000 元,就能升级到最高级别的至尊会员,还可以享受每季度的线下 VIP 活动。
想喝咖啡了,在星巴克小程序上下单,发现了醒目的会员等级提示和不同等级权益的详细说明。星巴克目前的会员分成 3 个等级,从低到高分别是银享级、玉享级和金享级。要想提升会员等级,就需要攒到一定数量的星星。例如从银享级升级到玉享级,需要 4 颗星,而每消费 50 元可以获得一颗星,这意味着需要消费满 200 元。
生活中,用户分层可谓无处不在。
用户分层的类型
用户分层可以分为两种类型——外向型和内向型,如图 10- 2 所示。

图 10-2 两种用户分层类型
外向型分层指品牌基于数据分析确定用户分层之后,将其作为标准向外宣传展示。常见的做法是直接按照用户分层的标准构建会员体系,并在醒目的资源位展示宣传,作为品牌整体用户战略的重要部分,一旦确定,绝不轻易变更。
内向型分层则是品牌用户运营相关的部门为了更好地达成 KPI,通过对用户分层进行精细化运营。这种分层一般更加细致和灵活,可以随运营目标而调整。不过,内向型分层并不会对外展示,只是用户运营的辅助工具。
本章将主要围绕对品牌影响更深远的外向型分层展开。
用户分层的特征
本章开头的 3 个例子中,平台和品牌根据消费金额把用户分成了不同的级别,这些级别之间有着显著的等级关系、明确的晋升路径、差异化的奖励机制,这也是用户分层的 3 个典型特征。
口显著的等级关系:在用户分层体系中,各层之间的等级秩序非常明显。虽然不同分层可能使用不同的命名方式,但消费者几乎可以立即识别出等级的高低,例如,VIP 8 高于 VIP 2,黄金会员高于白银会员。
口明确的晋升路径:当用户满足一定条件时,便可以从低等级晋升至高等级。这些条件通常与交易相关,可以通过具体的数值进行量化。
口差异化的奖励机制:根据用户等级的不同,平台和品牌为用户提供了不同力度的权益。用户的等级越高,为其提供的实惠和特权就越多。这种差异化的奖励机制能激励用户提高消费水平,从而增强其对平台和品牌的黏性。奖励可能包括折扣、优惠券、专属客服、活动预览等。
为什么要做用户分层
很多人把做用户分层的原因归结为精细化运营的需要,有一定道理,但这只是冰山一角,要搞清楚为什么品牌都喜欢做用户分层,我们还需要看得更深一些。
1. 供需关系的转变
在一个供不应求的市场里,品牌最关注的两件事是定价和产能。在条件允许的情况下能把价格提升多少?如何开足马力、加大产能以生产更多的产品?至于怎样维护好和用户的关系,怎样用科学的方法对用户进行分层,对品牌来说,既无必要也没兴趣。
反之,在供过于求的市场里,市场上有各种品牌的产品相互竞争,产品同质化严重,选择权牢牢掌握在用户的手中。这个时候,品牌则需要通过维护好和用户的关系,用各种奖励忠诚的方式来增强自己的竞争力。现如今大多数行业都处于这种供求状态,因此大家会发现几乎所有的品牌都在做用户分层,并基于分层搭建自己的会员体系。
2. 资源的有限性
品牌的资源都是有限的,如果将资源和福利无差别地投到每个用户身上,会带来两个问题:其一,会引来巨量的羊毛党,无底线地薅羊毛任何品牌都无法承受;其二,忠诚的用户并未受到特殊的关注,他们很可能转而投向对忠诚用户特殊关照的品牌。因此,在资源有限的情况下,品牌必须筛选出不同等级的用户,差异化投入和运营,以期达到每层用户的最佳 ROI。
3. 提升用户忠诚度
用户分层,除了把用户分为不同的等级,为每个等级设置针对性的激励策略也同样重要。通过给予高等级用户丰富的特权和激励,可以有效维护高等级用户的忠诚度;同时,对低等级用户来说,高等级的丰厚激励会吸引和促使他们不断完成品牌期待的关键动作(如持续消费),以实现等级的提升。
分层的两个问题
要进行用户分层,首先要解决的两个问题便是“根据什么指标来分”和“分多少层”。
1. 根据什么指标来分
本章开头的 3 个例子,无论对于《王者荣耀》、某品牌天猫店还是星巴克,营收都是最核心的指标,因此,它们都按照用户的累计消费金额来区分等级。我们期望用户完成什么关键行为,就可以用这种行为的数据来划分用户等级。对于平台和品牌来说,用户的活跃指标虽然重要,但远远比不上真金白银的消费。所以,用累计消费金额来划分用户等级,是目前最常用的一种方式。
2. 分多少层
由于平台和品牌有较大的差异性,这里我们主要从品牌的视角来思考“用户应该分多少层”这个问题。
口分层太少(如分 2 层),难以体现不同等级的差异化激励。如果门槛标准设置太低,用户很容易达到最高等级,有一种“轻轻一跃便上山巅"的感觉,大概率是不会珍惜眼前的美景——高等级激励的;如果门槛标准设置太高,低等级用户会有“难于上青天"之感。
口分层过多(超过 5 层),容易让用户信息过载,导致大部分用户无法记住甚至没有兴趣看不同等级所对应的福利,更谈不上这些福利最终对用户的关键行为有多少实际的激励作用。
所以,大部分品牌用户分层的数量在 3~5 层之间。最低等级几乎没有限制门槛,目的是吸引用户绑定,品牌可以获取用户关键信息并引导用户初次体验产品;中间等级则可以筛掉一些羊毛的用户,通过一些日常的奖励,促使用户持续留存和购买;高等级用户是品牌最核心的人群,需要给予最大的资源投入与最好的福利,维持核心用户的忠诚,并吸引其他等级的用户向上升级。
下面,我将给大家提供实际的案例数据,在介绍几种用户分层方法的同时带大家用 Pandas 实操。
10.2 二八法则
二八法则在用户分层上的应用
二八法则过于经典,相信不少读者耳朵都听出茧子了。二八法则应用到电商场景下,可以概括为“20%的用户贡献了 80%的销售额”,这 20%用户是品牌最核心的用户,如图 10- 3 所示。当然,法则中的 20%和 80%两个数字,在实际中会有所波动,但总体都符合少量核心用户做出大量贡献的规律。
怎么将二八法则与用户分层相结合呢?很简单,根据二八法则直接切分就好。这里我们以把用户分 3 层为例。先按照用户的累计支付金额降序排列,找到前 20%的用户。如此一来,整体用户被分成了前 20%和后 80%两个人群。
然后,在前 20%的用户中,继续按照二八法则切分,最高等级的人群占比为 4%(20%×20%)。最终,整体用户被分成了低、中、高三个等级,对应的人数占比分别是 80%、16%、4%。
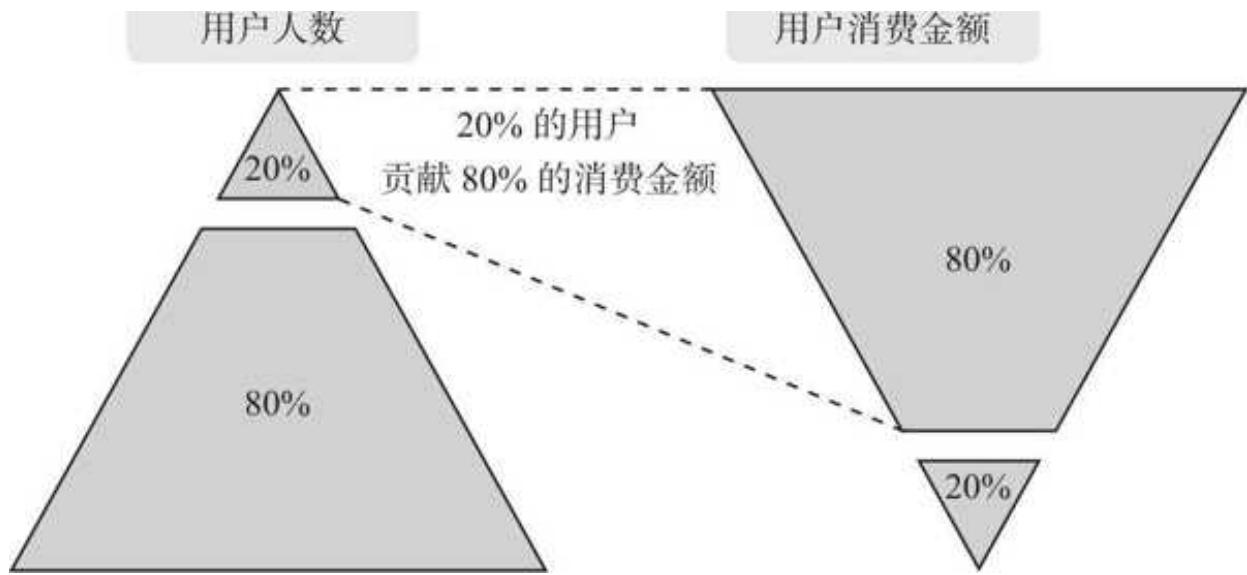
图 10-3 二八法则
百说不如一练,我们用 Pandas 来实践一下。
数据预览
1. 数据扫描
首先,导入我们的案例数据,数据是阿粥(小 z)品牌下的店铺 2023 年 1~12 月的订单数据:
df = pd. read_excel ('主订单数据集. xlsx') df.head ()
前几行结果如下:
| 品牌名 | 店铺名称 | 主订单编号 | 用户 ID | 付款时间 | 订单状态 | 实付金额 | 购买数量 |
| 0 | 阿粥(小 z)数据不吹牛 | 73465136654 | uid 135460366 | 2023-01-01 | 09:32:12 | 交易成功 | 166 |
| 1 | 阿粥(小 z)数据不吹牛 | 73465136655 | uid 135460367 | 2023-01-01 | 09:11:50 | 交易成功 | 117 |
| 2 | 阿粥(小 z)数据不吹牛 | 73465136656 | uid 135460368 | 2023-01-01 | 11:49:02 | 交易成功 | 166 |
| 3 | 阿粥(小 z)数据不吹牛 | 73465136657 | uid 135460369 | 2023-01-01 | 12:20:24 | 交易成功 | 77 |
| 4 | 阿粥(小 z)数据不吹牛 | 73465136658 | uid 135460370 | 2023-01-01 | 01:23:15 | 交易成功 | 158 |
获取数据的关键信息,对数据进行快速扫描:
print (df.info ()) print (df.describe ())
运行结果如下:
df.info () <class 'pandas.core.frame.DataFrame'> RangeIndex: 356233 entries, 0 to 356232 Data columns (total 8 columns): # Column Non- Null Count dtype 0 品牌名 356233 non- null object 1 店铺名称 356233 non- null object
2 主订单编号 356233 non- null int 64 3 用户 ID 356231 non- null object 4 付款时间 356233 non- null object 5 订单状态 356233 non- null object 6 实付金额 356233 non- null int 64 7 购买数量 356233 non- null int 64 dtypes: int 64 (3), object (5) memory usage: 21.7+ MB
df.describe () 主订单编号实付金额购买数量 count 3.562330 e+05 356233.000000 356233.000000 mean 7.346531 e+10 166.493065 1.116438 std 1.028358 e+05 153.645028 0.817845 min 7.346514 e+10 40.000000 1.000000 25% 7.346523 e+10 77.000000 1.000000 50% 7.346531 e+10 146.000000 1.000000 75% 7.346540 e+10 203.000000 1.000000 max 7.346549 e+10 29309.000000 150.000000
通过 Pandas 快速扫描,数据的关键信息已经明确,具体如下。
口数据集一共 35.6 万行,包含品牌名、店铺名称、主订单编号、用户 ID、付款时间、订单状态、实付金额和购买数量的字段。需要注意的是,实付金额是这条交易记录的总金额,不用再乘以购买数量。
口 df. info()的结果显示,只有用户 ID 有两个缺失值,整体数据还算完整。
口 df. describe()把主订单编号当作数值来统计,直接忽略即可。但我们可以明显发现这份数据中的实付金额和购买数量存在异常值,单条记录的最高金额接近 3 万元,购买数量也达到了令人难以置信的 150。
2. 主订单和子订单的区别
一般订单数据会分为主订单和子订单两种类型,以上是一份很典型的主订单数据集。主订单和子订单的差异如图 10- 4 所示。
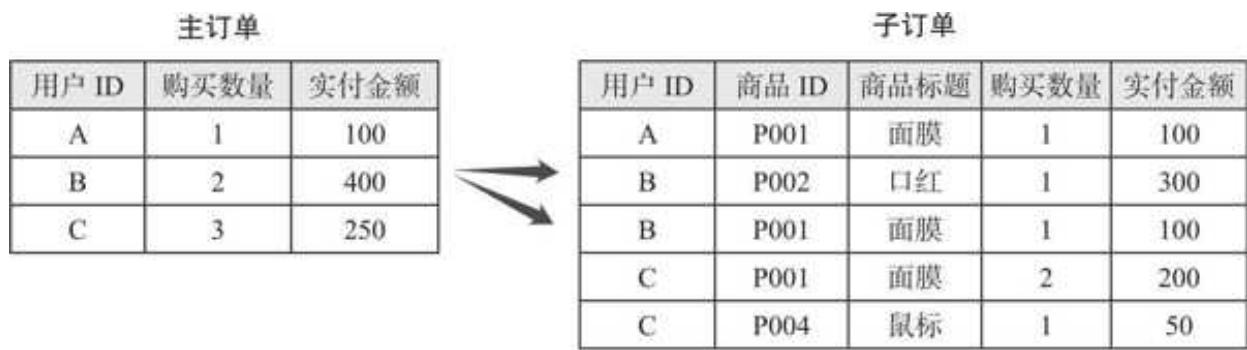
图 10-4 主订单和子订单的差异
主订单会把用户同一时间下单的商品聚合,汇总成一条数据;而子订单则对应到一个个具体的商品。例如某用户的购物车中有 2 件不同的商品,同一时间付了款,主订单只有 1 行记录,而子订单会有 2 行。
数据清洗
1. 用户 ID 缺失值处理
用户 ID 只有极少量的缺失值,直接将相关行删掉即可:
df = df. loc[df['用户 ID']. isnull () == False, :] print (df.info ())
运行结果如下:
<class 'pandas.core.frame.DataFrame'>Int64Index: 356231 entries, 0 to 356232Data columns (total 8 columns): # Column Non- Null Count dtype - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 0 品牌名 356231 non- null object 1 店铺名称 356231 non- null object 2 主订单编号 356231 non- null int64 3 用户 ID 356231 non- null object 4 付款时间 356231 non- null object 5 订单状态 356231 non- null object 6 实付金额 356231 non- null int64 7 购买数量 356231 non- null int64 dtypes: int64(3), object(5) memory usage: 24.5+ MB
2. 异常值处理
四分位法是处理异常值时常用的方法,其原理如图 10- 5 所示。
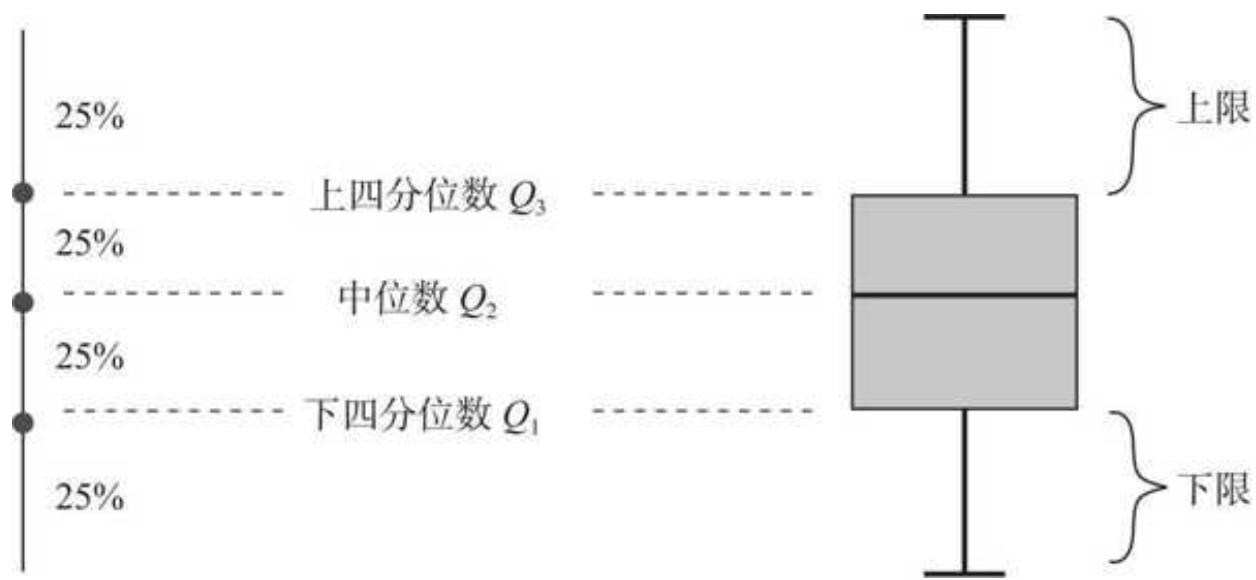
图 10-5 四分位法原理
从统计的角度看,数据从小到大排序后,下四分位数
上限和下限主要用
上限
其中
因为订单数据涉及大促活动,难免有用户极端的囤货行为,这里我们用
先计算上限和下限的值:
up
分位数直接取材于 df. describe()的统计结果,计算得到了上下限:
实付金额的上限值:581.0 实付金额的下限值:- 301.0
订单金额下限不可能为负,因此只需对上限值进行异常值剔除处理:
df = df. loc[df['实付金额'] <= up,:] df.describe ()
所有超过 581 元的订单均被剔除,结果如下:
| 主订单编号 | 实付金额 | 购买数量 |
| count 3.533680 e+05 | 353368.000000 | 353368.000000 |
| mean 7.346531 e+10 | 160.609150 | 1.103861 |
| std 1.027865 e+05 | 99.092419 | 0.645977 |
| min 7.346514 e+10 | 40.000000 | 1.000000 |
| 25% 7.346523 e+10 | 77.000000 | 1.000000 |
| 50% 7.346531 e+10 | 146.000000 | 1.000000 |
| 75% 7.346540 e+10 | 199.000000 | 1.000000 |
| max 7.346549 e+10 | 581.000000 | 145.000000 |
一波刚平,一波又起。金额正常了,但购买数量最大值还是 145,有的读者可能会疑惑:“刚才剔除金额的时候为什么不一起把购买数量剔掉?”
那是因为绝大部分用户的购买数量是 1,最开始 describe()中的上下四分位数也都是 1,相减之后是 0,没有任何意义。我们使用购买数量对应的订单数分布来筛选:
统计不同购买数量对应的订单数分布 ct_count = df['购买数量']. value_counts (). reset_index () ct_count. columns = ['购买数量', '订单数'] #统计订单数占比ct_count ['订单数占比'] = ct_count['订单数'] / ct_count['订单数']. sum () #订单数占比累加结果ct_count ['累计订单数占比'] = ct_count['订单数占比']. cumsum () ct_count.head (10) 运行结果如下:
运行结果如下:
| 购买数量 | 订单数 | 订单数占比 | 累计订单数占比 |
| 0 1 | 329739 | 0.933132 | 0.933132 |
| 1 2 | 14216 | 0.040230 | 0.973362 |
| 2 3 | 7998 | 0.022634 | 0.995996 |
| 3 4 | 687 | 0.001944 | 0.997940 |
| 4 5 | 449 | 0.001271 | 0.999210 |
| 5 6 | 152 | 0.000430 | 0.999641 |
| 6 7 | 35 | 0.000099 | 0.999740 |
| 7 10 | 26 | 0.000074 | 0.999813 |
| 8 8 | 12 | 0.000034 | 0.999847 |
| 9 9 | 11 | 0.000031 | 0.999878 |
绝大部分订单的购买数量是 1,购买数量小于或等于 5 的订单占总订单的比重高达
df = df. loc[df['购买数量'] <= 5,:]
3. 订单状态筛选
订单相关的数据如果有订单状态的字段,一定要留意。我们来观察一下目前的订单状态分布:
df['订单状态']. value_counts ()
运行结果如下:
交易成功 289386 付款以前,卖家或买家主动关闭交易 37242 付款以后用户退款成功,交易自动关闭 26447 等待买家确认收货,即卖家已发货 14 Name: 订单状态, dtype: int 64
订单状态差异是造成口径差异的一个重要因素,这里我们只保留成功的订单:
df = df. loc[df['订单状态'] == '交易成功',:] print ('清洗之后的订单量: ', len (df))
清洗之后的订单量为 289386。终于把手洗干净,可以开动吃正餐了。
二八法则下的用户分层
如果要根据二八法则把用户分为三层,需要切两刀:第一刀划出前
第一步,先根据实付金额将用户降序排列:
每个用户金额汇总 group_28=df. groupby(用户 ID)[实付金额). sum(). sort_values(ascending
按用户 ID 分组,统计每个用户的实付金额并按降序排列,结果如下:
用户 ID 实付金额用户序号 0 uid 135476531 39758 11 uid 135460679 35543 22 uid 135467627 30916 33 uid 135473980 23619 44 uid 135465649 21015 5
第二步,确定前
top_4 = round (len (group_28) * 0.04) top_20 = round (len (group_28) * 0.20) print ('前 4%对应的最后一个序号:', top_4) print ('前 20%对应的最后一个序号:', top_20)
这里直接用总用户数乘以对应的分位数,再用 round()方法截取整数位,得到对应的用户序号:
前 4%对应的最后一个序号:5420 前 20%对应的最后一个序号:27101
第三步,根据序号筛选出对应的分层金额门槛:
print('前 4%对应的金额门槛:',group_28. loc{group_28['用户序号'] == top_4,实付金额). values) print('前 20%对应的金额门槛:',group_28. loc{group_28['用户序号'] == top_20,实付金额j.values)
在按金额排序的用户分组中,运行上述代码找到对应的金额门槛:
前 4%对应的金额门槛:[1037]前 20%对应的金额门槛:[460]
根据金额门槛我们对用户进行分层打标,其中消费金额小于 460 元的为低级用户,大于或等于 460 元且小于 1037 元的为中级用户,大于或等于 1037 元的是高级用户。通过自定义函数和 apply()方法来实现:
根据金额打标
def judge (x): if
group_28['用户等级']
运行结果如下:
| 用户 ID | 实付金额 | 用户序号 | 用户等级 | |
| 0 | uid 135476531 | 39758 | 1 | 高级用户 |
| 1 | uid 135460679 | 35543 | 2 | 高级用户 |
| 2 | uid 135467627 | 30916 | 3 | 高级用户 |
| 3 | uid 135473980 | 23619 | 4 | 高级用户 |
| 4 | uid 135465649 | 21015 | 5 | 高级用户 |
二八法则的用户分层到此已经完成,最后我们统计不同等级的会员金额占比:
直接根据等级标签做金额汇总 group_28_rank = group_28. groupby ('用户等级')['实付金额']. sum (). reset_index () 计算不同等级会员的金额占比 group_28_rank['金额占比'] = group_28_rank['实付金额'] / group_28_rank['实付金额']. sum () group_28_rank. sort_values (['实付金额']) 运行代码得到了高级、中级、低级用户金额及占比:
运行代码得到了高级、中级、低级用户金额及占比:
用户等级实付金额金额占比 2 高级用户 9087072 0.1997170 中级用户 14104956 0.3100001 低级用户 22307802 0.490283
前
10.3 拐点法
不同于二八法则分层的简单粗暴,拐点法依托于数据分布中的关键转折点,为用户分层提供了更加科学且合理的依据。
什么是拐点法
拐点,在一些地方也叫作魔法数字,它广泛应用于数据分析之中,用于指导运营和决策。例如:口某社交软件发现,如果新注册的用户在 7 天内关注了 20 个以上的用户,那么他的留存概率会大幅提升;口某电商品牌发现,如果用户累计消费超过 300 元,那么其用户生命周期会显著延长。这里的关注 20 个用户、累计消费 300 元即魔法数字,从数据趋势上看就是拐点,如图 10- 6 所示。
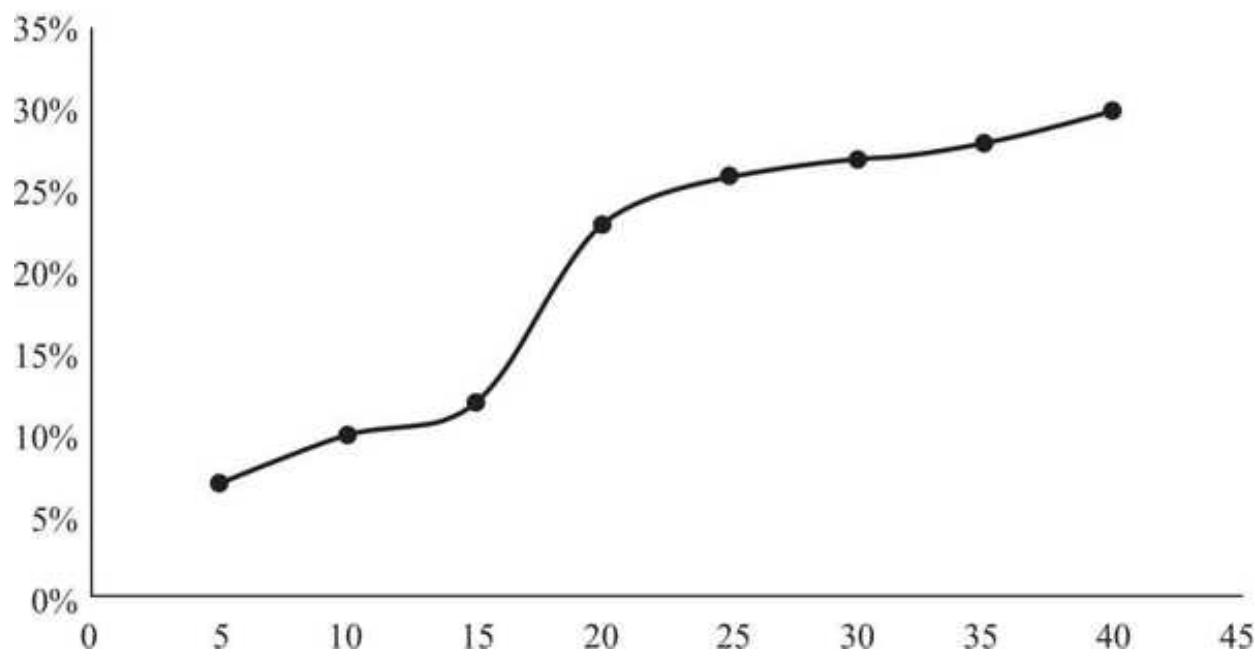
新用户关注人数与次月留存率的关系图 10-6 趋势图拐点
当用户的某个动作达到了拐点的标准时,其关键行为(如留存)较之前会有显著提升,而拐点法就是通过观察数据趋势,找到这些关键的拐点。
拐点法在用户分层上的应用
拐点法的核心在于两个指标的选择。
第一个指标:衡量用户的某个行为,例如 7 天内关注了 20 个以上的用户;用户累计消费超过 300 元。这个指标必须是品牌有能力去影响的指标,否则就算找到拐点,品牌无能为力,也于事无补。
第二个指标:指的是品牌希望提升什么指标,如次月留存率、用户生命周期价值。这个指标通常是品牌希望实现的关键目标,带有一定的预期性。
对应到用户分层上,为了让大家更好地理解,我们先来思考第二个指标:为什么要做用户分层?我们想通过用户分层提升什么?
“通过分层来提升用户长期忠诚度”是分层的核心目的之一。那么忠诚度又应该通过什么指标来量化呢?复购率是一个不错的答案,因为只有对品牌忠诚的用户才会重复购买。
我们希望提升用户的复购率,同时会用消费金额来对用户进行分层。两者结合,我们可以把用户的消费金额作为第一个指标,观察不同消费区间的用户对应留存率的变化趋势,从而找到消费金额与留存率之间的关系,并尝试找到关键的拐点,作为用户分层的参考值。
两个指标已经确定了,但是复购率怎么计算才合理呢?
基于 Pandas 的拐点法分层
1. 数据回顾
经过之前的数据清洗和分析,我们可以直接拿到 2023 年每个用户的消费金额汇总表 group_28:
| 用户 ID | 实付金额 | 用户序号 | 用户等级 | |
| 0 | uid 135476531 | 39758 | 1 | 高级用户 |
| 1 | uid 135460679 | 35543 | 2 | 高级用户 |
| 2 | uid 135467627 | 30916 | 3 | 高级用户 |
| 3 | uid 135473980 | 23619 | 4 | 高级用户 |
| 4 | uid 135465649 | 21015 | 5 | 高级用户 |
我们将其重新命名,并把之前二八法则确定的用户等级删掉,只保留了用户 ID 和实付金额:
group_kneed
运行结果如下:
| 用户 ID | 实付金额 | |
| 0 | uid 135476531 | 39758 |
| 1 | uid 135460679 | 35543 |
| 2 | uid 135467627 | 30916 |
| 3 | uid 135473980 | 23619 |
| 4 | uid 135465649 | 21015 |
2. 关键指标口径确认
我们已经得到了拐点法的第一个指标——用户实付金额,第二个指标复购率该如何计算呢?
由于这里的复购率是衡量用户忠诚度的,带有预期的性质,所以我们采用隔断复购率的计算逻辑,如图 10- 7 所示。
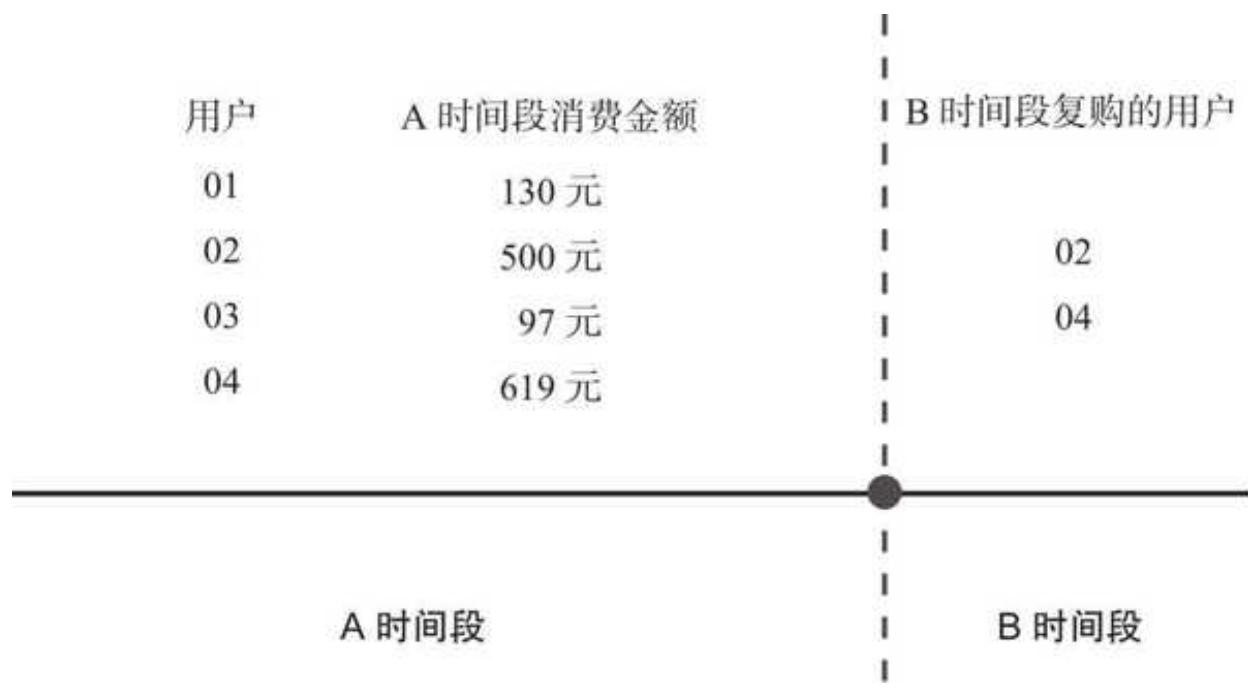
图 10-7 隔断复购率的计算逻辑
品牌整体的订单被隔断,分为 A 和 B 两个时间段。
A 时间段范围较大,以保证用户数据足够稳定,我们计算该时间段每个用户的消费金额。
B 时间段又叫复购观察期,时间跨度根据品牌用户和产品的特性来确定,一般是 3 个月以上,即用户 3 个月以上不购买,那么他流失或不忠诚的概率就非常大。
通过分析 A 时间段不同消费区间的用户在 B 时间段是否购买(见图 10- 8),得到 A 时间段不同消费区间的隔断复购率趋势,帮助寻找消费区间和复购率的拐点。

图 10-8 复购判断细化
在本章的案例中,假设当前时间是 2024 年 4 月 1 日,为了分析方便,可以把 A 时间段设定为 2023 年 1~12 月(实际分析中建议将这个时间拉得更长,以保证数据足够稳定),也就是之前处理的那部
分数据,把 B 时间段定为 2024 年
3. 不同消费区间的打标
最终分析的是不同消费区间和复购率变化趋势。首先需要按消费区间对不同用户进行打标,这里我们以 100 元为一个区间划分。先准备区间数据:
将分组金额按 100 元一个区间切分,直到 1500 元,再往上用一个极大值封顶 bins = list (range (0, 1600, 100)) + [1000000]
构造分组标签 ranges = []
最终把分组标签构造成 0- 100,100- 200,200- 300, for start, end in zip (range (0,1500,100), range (100,1600,100)): interval
以上代码分别构造了分组区间和分组区间对应的标签,具体如下。(这为接下来的切分做好了准备。)
分组区间:[0,100,200,300,400,500,600,700,800,900,1000,1100,1200,1300,1400,1500,1000000]分组区间对应的标签:[0- 100,'100- 200','200- 300','300- 400','400- 500','500- 600','600- 700','700- 800','800- 900','900- 1000','1000- 1100','1100- 1200','1200- 1300','1300- 1400','1400- 1500','1500+']
有了对应的区间之后,打标直接用 pd. cut()方法:
group_kneed['消费区间'] = pd.cut (group_kneed['实时金额'], bins = bins, labels = ranges) group_kneed
把每个用户的实付金额按对应区间打标,得到如下结果:
| 用户 ID | 实付金额 | 消费区间 | |
| 0 | uid 135476531 | 39758 | 1500+ |
| 1 | uid 135460679 | 35543 | 1500+ |
| 2 | uid 135467627 | 30916 | 1500+ |
| 3 | uid 135473980 | 23619 | 1500+ |
| 4 | uid 135465649 | 21015 | 1500+ |
| ... | ... | ... | ... |
| 135499 | uid 135551937 | 40 | 0~100 |
| 135500 | uid 135583969 | 40 | 0~100 |
| 135501 | uid 135493631 | 40 | 0~100 |
| 135502 | uid 135486524 | 40 | 0~100 |
| 135503 | uid 135610430 | 40 | 0~100 |
| 135504 | rows × 3 columns |
消费区间划分完成,该进行不同区间复购率的计算了。
4. 不同区间复购率的计算
筛选出 2024 年
在这一步,我已经为大家准备好了在 2024 年
repur = pd. read_excel ('2024 年 1~3 月复购用户. xlsx') repur.head ()
repur 记录了复购用户的 ID:
用户 ID 0 uid 135477653 1 uid 135521126 2 uid 135542845 3 uid 135531153 4 uid 135518141
拿到这份 ID,可以判断用户是否复购:
group_kneed['是否复购'] = group_kneed['用户 ID']. isin (repur['用户 ID']) group_kneed.head ()
以上代码判断每个用户是否在 2024 年
用户 ID 实付金额消费区间是否复购 0 uid 135476531 39758 1500+ True 1 uid 135460679 35543 1500+ True 2 uid 135467627 30916 1500+ False 3 uid 135473980 23619 1500+ alse 4 uid 135465649 21015 1500+ False
下一步,计算每个区间的用户数,作为复购率计算的分母:
group_kneed_inter = group_kneed.groupby ('消费区间')['用户 ID']. count () .reset_index () group_kneed_inter. columns = ['消费区间','用户数'] group_kneed_inter.head ()
运行结果如下:
| 消费区间 | 用户数 | |
| 0 | 0~100 | 21033 |
| 1 | 100~200 | 40013 |
| 2 | 200~300 | 23074 |
| 3 | 300~400 | 17995 |
| 4 | 400~500 | 10036 |
接着,计算每个区间的复购人数:
group_if_repur = group_kneed.groupby ('消费区间')['是否复购']. sum (). reset_index () group_if_repur. columns = ['消费区间','复购人数'] group_if_repur.head ()
依然按照消费区间分组,对“是否复购”列进行汇总,得到复购人数的统计结果:
| 消费区间 | 复购人数 |
| 0 | 0~100 |
| 1 | 100~200 |
| 2 | 200~300 |
| 3 | 300~400 |
| 4 | 400~500 |
之前的“是否复购”列由 True 和 False 布尔值构成,为什么用 sum()方法进行汇总之后,却得到了复购人数呢?这是因为在参与计算时,True、False 分别对应数值 1 和 0。也就是说,我们对复购人数做了汇总。
有了消费区间、用户数、复购人数三列,复购率的计算呼之欲出:
group_kneed_result = pd.merge (group_kneed_inter, group_if_repur, left_on = '消费区间', right_on = '消费区间', how = 'inner') group_kneed_result['复购率'] = group_kneed_result['复购人数'] / group_kneed_result['用户数'] group_kneed_result.head ()
根据消费区间把用户数和复购人数合并,同时用复购人数除以用户数,得到复购率:
| 消费区间 | 用户数 | 复购人数 | 复购率 |
| 0 0~100 | 21033 | 1535 | 0.072981 |
| 1 100~200 | 40013 | 5162 | 0.129008 |
| 2 200~300 | 23074 | 3900 | 0.169021 |
| 3 300~400 | 17995 | 3545 | 0.196999 |
| 4 400~500 | 10036 | 2017 | 0.200976 |
5. 结果可视化与分析
关键指标均已计算完成,最后绘制消费区间和复购率趋势图:
导入必要的富图库并做设置,此处省略#...
fig = plt.figure (figsize = (8,4))
绘制折线图
plt.plot (group_kneed_result['消费区间'], group_kneed_result['复购率']) * 100, marker='o', color = 'r', alpha = 0.7)
设置图表标题和坐标轴标签
plt.title ('用户消费区间与复购率趋势图') plt.xlabel ('消费区间/元') plt.ylabel ('复购率/元') #旋转标题避免文字重叠
plt.xtickss (rotation=45)
绘制网格线
plt.grid (True, linestyle=- - - ', alpha=0.7)
运行结果如图 10- 9 所示。
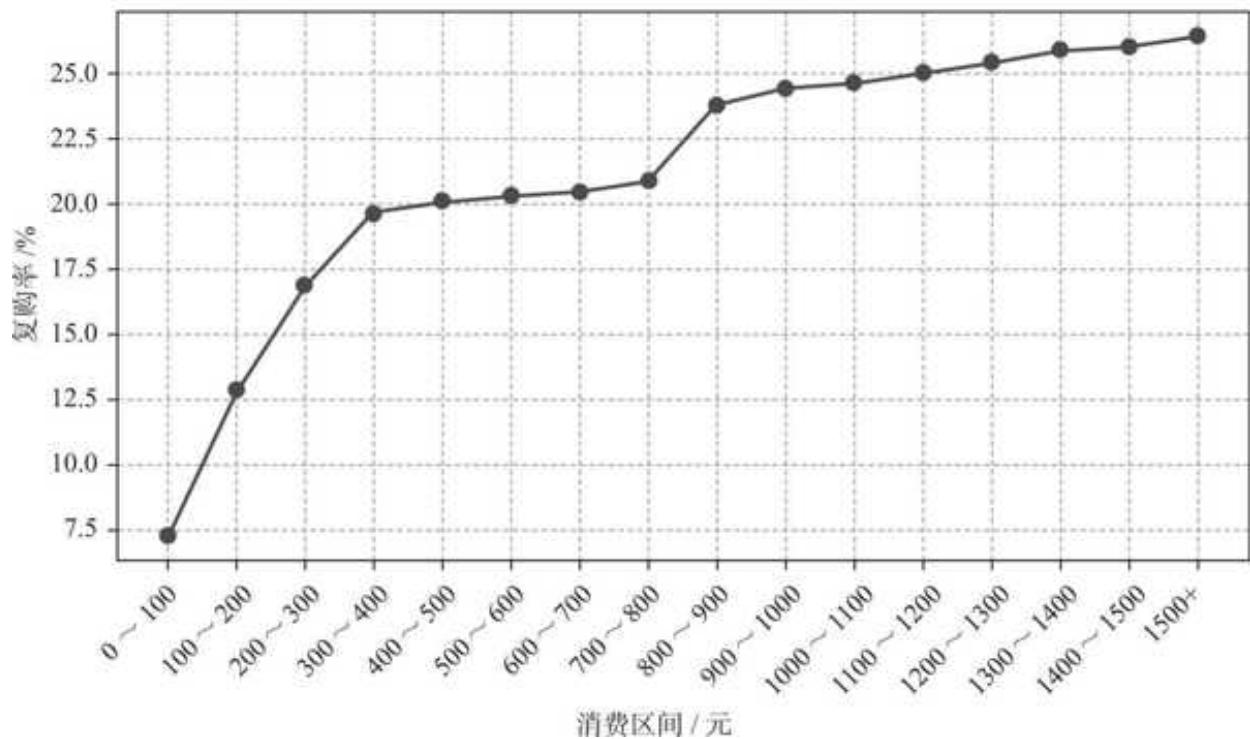
图 10-9 用户消费区间与复购率趋势
从用户消费区间与留存率趋势图可以清楚地看到以下消息。
口 400 元以内,用户每多消费 100 元,其留存率都会有显著的提升;当消费
口消费区间
结合数据观察,我们从趋势图中发现了两个具有拐点性质的消费区间。消费区间的数据可以拆得更细,进行更精准的金额定位,总体逻辑是完全一样的。
基于运营策略“稳定起见”的原则:消费 400 元的人数比消费 300 元的要少,分层激励投入的资源相对较少,而且消费 400 元的用户大概率要比消费 300 元的留存率更高,这符合资源投入少、用户质量高的特点。因此结合业务视角,以两个拐点消费区间的上界作为用户分层的标准:
口消费低于 400 元的用户为低等级用户,品牌应该通过优惠等激励,促进早期用户更多消费以提升其复购率。
口消费大于或等于 400 元且小于 900 元的用户为中级用户。这部分用户的忠诚度已经有所提升,但应该进一步促进其消费,让他们与品牌建立更深层的关系。
口消费大于或等于 900 元的用户则为高级用户,是品牌最核心和忠诚的用户,无论是新品尝试还是营销活动传播,他们都是最有动力的一群人,品牌必须足够重视他们并给予关怀奖励。
利用拐点法进行用户分层至此已经全部完成。
10.4 本章小结
在本章中,我们先学习了用户分层的基本概念,包括用户分层有哪些类型,为什么要做用户分层以及怎么样做。在此基础上,我们结合实际的案例数据,用 Pandas 先清洗、后分析。
-
数据清洗:扫描和预览数据后,处理了缺失值、异常值,并筛选了订单状态。在清洗的过程中,我们学到了如何用四分位法剔除异常值的新知识点。
-
数据分析:活学活用,在学习二八法则和拐点法理论的同时,分别用 Pandas 实现了两种方法指导下的用户分层。其中,二八法则的分层相对固定,按照一定的比例来切分用户;拐点法更加灵活,通过两个指标的分布关系,找到关键拐点,进而予以策略支持。