第11章 用户分群实战与加强版RFM模型
11.1 走近用户分群
用户分群的定义及作用
用户分群,是指根据用户的属性、行为等数据将用户分成不同的群组或类别。通过用户分群,把不同特征的用户区分开来,并根据他们的兴趣、行为等偏好有针对性地制定运营策略,有的放矢,实现真正的精细化运营,如图 11- 1 所示。
用户分群和用户分层的区别
你可能会问:上一章介绍的用户分层和这里的用户分群仅一字之差,它们到底有何区别?主要有以下两点区别。
口等级逻辑不同。用户分层中不同等级的用户具有明显的金字塔式等级阶梯关系,而用户分群中的不同群组更像是平等的关系,例如男性用户和女性用户、偏好户外运动的用户与偏好室内运动的用户。
口分类依据不同。用户分层一般是按照单一指标对用户进行等级划分,而用户分群则是综合了更多维度的指标,把用户分成不同的群组。多指标分群的结果更加精细化,也更加符合业务精细化运营的逻辑。
图 11-1 用户分群示例
我用一个比喻帮助大家更好地理解它们的差异:用户分层像是一根绳子,绳上打了几个绳结,用户拽着绳子从下往上爬,每通过一个绳结,就会得到不同的奖励;用户分群则是由特殊绳子编制而成的蹦床,蹦床划分了多个主题,用户可以在其中任意选择自己喜欢的主题区域乱蹦。
那么,用户分群到底应该怎样做呢?我们一起来看看用户分群领域如雷贯耳的 RFM 模型。
11.2 RFM 用户分群实战
经典的 RFM 模型
RFM 模型是一种非常经典的用户分群、价值分析模型。RFM 模型有着极强的适用性,被广泛应用于以电商为代表的各个行业。同时,这个模型以直白著称,R、F、M 这 3 个字母就代表了它的 3 个核心指标。
口 R(Recency,最近一次购买间隔):每个用户有多少天没有回购了,可以理解为用户最近一次购买到现在隔了多少天。
口 F(Frequency,消费频次):每个用户购买了多少次。
口 M(Monetary,消费金额):每个用户累计购买的金额,也可以是每个用户平均每次购买的金额。
这 3 个维度是 RFM 模型的精髓所在,它们将混杂在一起的用户数据分成标准的 8 类(见图 11- 2),让我们能够根据每一类用户人数占比、金额贡献等不同的特征,进行人、货、场三重匹配的精细化运营。
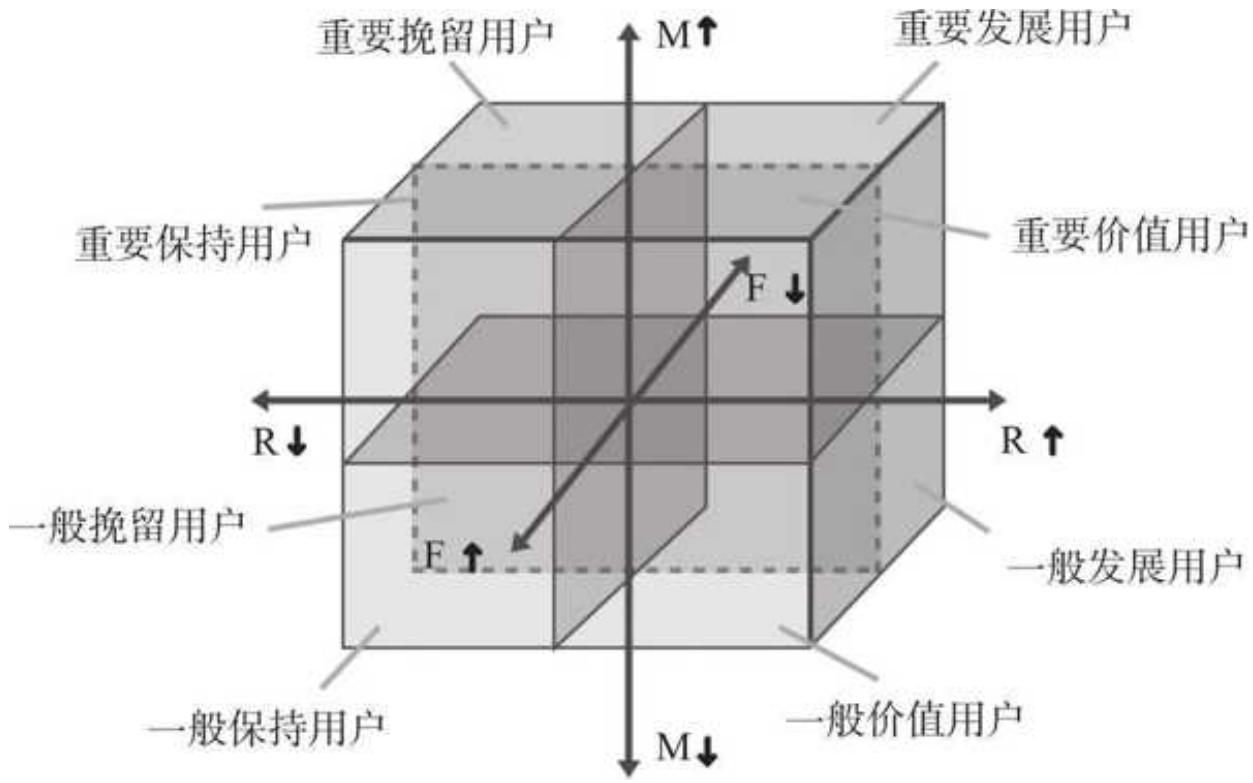
图 11-2 标准的 RFM 模型
用 Pandas 在源数据的基础上建立 RFM 模型,整体分为 5 步:数据概览、数据处理、维度打分、分值计算和用户分层。
第一步:数据概览
为了减少不必要的数据处理环节,这里我们使用的数据依然是上一章中用到的主订单表,它记录着用户交易相关的字段:
df = pd. read_excel ('主订单数据集. xlsx') df.head ()
数据预览效果如下:
| 品牌名 | 店铺名称 | 主订单编号 | 用户 ID | 付款时间 | 订单状态 | 实付金额 | 购买数量 | ||
| 0 | 阿粥(小 z) | 数据不吹牛 | 73465136654 | uid 135460366 | 2023-01-01 | 09:33:12 | 交易成功 | 166 | 1 |
| 1 | 阿粥(小 z) | 数据不吹牛 | 73465136655 | uid 135460367 | 2023-01-01 | 09:11:50 | 交易成功 | 117 | 1 |
| 2 | 阿粥(小 z) | 数据不吹牛 | 73465136656 | uid 135460368 | 2023-01-01 | 11:49:02 | 交易成功 | 166 | 1 |
| 3 | 阿粥(小 z) | 数据不吹牛 | 73465136657 | uid 135460369 | 2023-01-01 | 12:20:24 | 交易成功 | 77 | 1 |
| 4 | 阿粥(小 z) | 数据不吹牛 | 73465136658 | uid 135460370 | 2023-01-01 | 01:23:15 | 交易成功 | 158 | 1 |
有个细节需要提醒大家注意,在实际的业务场景中,可以考虑将一个用户在一天内的多次消费行为从整体上看作一次。
例如,我今天 10 点在必胜客天猫店买了个比萨兑换券,11 点又下单了饮料兑换券,18 点看到优惠又买了两个冰淇淋兑换券。这一天内虽然我下单了 3 次,但最终这些兑换券我会一次消费掉,应该只算作一次完整的消费行为,这个逻辑会指导后面 F 值的计算。
在上一章中,我们使用 info()和 describe()快速扫描了数据,已经熟悉了订单结构:订单一共 35.6 万行,包含品牌名、店铺名称、主订单编号、用户 ID、付款时间、订单状态、实付金额、购买数量等交易相关的字段。数据整体很规整,但存在缺失值、异常值等瑕疵。
第二步:数据处理
1. 订单数据清洗
经过上一章的缺失值处理、异常值处理和订单状态筛选,处理后的 28.9 万条数据已经非常“干净”,沿用之前代码即可,这里不再赘述,而把重点放在 RFM 模型相关的操作上。
2. 关键字段提取
清洗完订单数据之后,对于 RFM 模型来说,订单的字段还是太多了。这也体现了 RFM 的广泛适用性,它所要求的字段非常简单,只需要用户 ID、付款时间和实付金额这 3 个关键字段。我们把这些字段提取出来:
rfm_df
提取后的结果如下:
| 用户 ID | 付款时间 | 实付金额 | |
| 0 | uid 135460366 | 2023-01-01 | 09:32:12 |
| 1 | uid 135460367 | 2023-01-01 | 09:11:50 |
| 2 | uid 135460368 | 2023-01-01 | 11:49:02 |
| 3 | uid 135460369 | 2023-01-01 | 12:20:24 |
| 4 | uid 135460370 | 2023-01-01 | 01:23:15 |
3. 关键字段构造
这一步的关键在于构建模型所需的 3 个字段。
口 R:最近一次购买距今多少天。
口 F:购买了多少次。
口 M:平均或者累计购买金额。
首先计算 R 值,即每个用户最近一次购买距离“今天"多少天。
这个今天是可以灵活定义的,假如我们在 2024 年 1 月 1 日对历史数据做分析,可以把这一天当作“今天”。
口对于只购买过一次的用户,用 2024 年 1 月 1 日减去用户的付款时间即可。
口对于多次购买用户,先筛选出这个用户最后一次付款的时间,再用 2024 年 1 月 1 日减去它。
需要提醒的是,在时间格式中,越往后的时间越“大”。举个例子,2023 年 9 月 19 日是要大于 2023 年 9 月 1 日的,即以下语句的返回结果为 True。
pd. to_datetime ('2023- 9- 19') > pd. to_datetime ('2023- 9- 1')
因此,要拿到所有用户最近一次付款时间,只需要按用户 ID 分组,再选取付款时间的最大值即可:
r = rfm_df.groupby ('用户 ID')['付款时间']. max (). reset_index () r.head ()
运行结果如下:
用户 ID 付款时间 0 uid 135460366 2023- 01- 01 09:32:12 1 uid 135460367 2023- 01- 01 09:11:50 2 uid 135460368 2023- 04- 07 18:19:37 3 uid 135460369 2023- 01- 13 13:48:02 4 uid 135460370 2023- 06- 16 08:05:47
为了得到最终的 R 值,用分析日期减去每位用户的最近一次付款时间。这份订单涵盖了 2023 年整年,所以这里我们把“2024- 1- 1”当作“今天”:
r['R'] = (pd. to_datetime ('2024- 1- 1') - r['付款时间']). dt. days r = r '用户ID', 'R' r.head ()
运行结果如下:
用户 ID R 0 uid 135460366 364 1 uid 135460367 364 2 uid 135460368 268 3 uid 135460369 352 4 uid 135460370 198
接着计算 F 值,即每个用户累计购买频次。
在数据概览阶段,我们明确了“把单个用户一天内的多次下单行为看作整体”的思路,所以,这里引入一个精确到天的日期标签,依照“用户 ID”和“日期标签”进行分组,把每个用户一天内的
多次下单行为合并,再统计购买次数:
引入日期标签辅助到 rfm_df['日期标签'] = rfm_df['付款时间']. astype (str). str[+10]把单个用户一天内的订单合并 dup_f = rfm_df.groupby (['用户 ID', '日期标签'])['付款时间']. count (). reset_index () 对合并后的用户统计频次 f = dup_f.groupby ('用户 ID')['付款时间']. count (). reset_index ()f.columns = ['用户 ID', 'F']f.head ()
得到 F 的结果如下:
用户 ID F 0 uid 135460366 1 1 uid 135460367 1 2 uid 135460368 2 3 uid 135460369 2 4 uid 135460370 7
上一步计算出了每个用户的购买频次,这里我们只需要得到每个用户的总支付金额,再用总支付金额除以购买频次,就能得到用户平均支付金额 M:
sum_m = rfm_df.groupby ('用户 ID')['实付金额']. sum (). reset_index () sum_m.columns = ['用户 ID', '总支付金额']com_m = pd.merge (sum_m, f, left_on = '用户 ID', right_on = '用户 ID', how = 'inner') 计算用户平均支付金额 com_m['M'] = com_m['总支付金额'] / com_m['F']
最后,将 3 个指标合并:
rfm = pd.merge (r, com_m, left_on = '用户 ID', right_on = '用户 ID', how = 'inner') rfm = rfm[['用户 ID', 'R', 'F', 'M']rfm_copy = rfm.copy () # 这里用不上,只是做个数据备份,为后面的模型加强做准备 rfm.head ()
运行结果如下:
| 用户 ID | R | F | M | |
| 0 | uid 135460366 | 364 | 1 | 166.000000 |
| 1 | uid 135460367 | 364 | 1 | 117.000000 |
| 2 | uid 135460368 | 268 | 2 | 120.500000 |
| 3 | uid 135460369 | 352 | 2 | 208.500000 |
| 4 | uid 135460370 | 198 | 7 | 263.714286 |
至此,我们完成了模型核心指标的计算。
第三步:维度打分
维度确认的核心是分值确定。按照设定的标准,我们给每个消费者的 R、F、M 值打分,分值的大小取决于我们的偏好,即对于我们越喜欢的行为,对应的数值越大,则打的分数就越高,反之亦然。
R 值代表了用户最后一次下单的离今天的天数,这个值越大,用户流失的可能性就越大。我们当然不希望用户流失,所以 R 值越大,赋予的得分越低。
F 值代表了用户购买频次,M 值则是用户平均支付金额,这两个指标越大越好,即数值越大,得分越高。
RFM 模型中打分一般采取 5 分制,有两种比较常见的打分方式,一种是按照数据的分位数来打分,另一种是依据数据和业务的理解进行分值的划分。
为了帮助读者加深对数据的理解,进行自己的分值设置,这里使用第二种,即提前确定不同数值对应的分值。
对于 R 值的打分,根据行业经验,将 5 分和 4 分设置为 30 天一个跨度,将 3 分与 2 分设置为 60 天一个跨度,且均为左闭右开区间,如表 11- 1 所示。
表 11-1 R 值打分及其含义
| R 值打分 | R 值 | 含义 |
| 1 | [180,∞) | 最近一次购买距今 180 天及以上 |
| 2 | [120,180) | 最近一次购买距今 120~179 天 |
| 3 | [60,120) | 最近一次购买距今 60~119 天 |
| 4 | [30,60) | 最近一次购买距今 30~59 天 |
| 5 | [0,30) | 最近一次购买距今 0~29 天 |
F 值等于购买频次,每多一次购买,分值就加一分,如表 11- 2 所示。
表 11-2 F 值打分及其含义
| F 值打分 | F 值 | 含义 |
| 1 | 1 | 购买 1 次 |
| 2 | 2 | 购买 2 次 |
| 3 | 3 | 购买 3 次 |
| 4 | 4 | 购买 4 次 |
| 5 | [5,∞) | 购买 5 次及以上 |
我们可以先对 M 值做个简单的区间统计,然后分组。这里以 50 元为区间跨度来进行划分,如表 11- 3 所示。
表 11-3 M 值打分及其含义
| M 值打分 | M 值 | 含义 |
| 1 | [0,50) | 平均每次支付金额大于或等于 0 元且小于 50 元 |
| 2 | [50,100) | 平均每次支付金额大于或等于 50 元且小于 100 元 |
| 3 | [100,150) | 平均每次支付金额大于或等于 100 元且小于 150 元 |
| 4 | [150,200) | 平均每次支付金额大于或等于 150 元且小于 200 元 |
| 5 | [200,∞) | 平均每次支付金额大于或等于 200 元 |
这一步我们确定了一个打分框架,每一位用户的每个指标都有了与之对应的分值。
第四步:分值计算
分值的划分逻辑已经确定,但看着有点复杂。下面有请 Pandas 登场,且看它如何三拳两脚搞定这麻烦的分组逻辑。先拿 R 值打个样:
rfm['R- SCORE'] = pd.cut (rfm['R'], bins = [0, 30, 60, 120, 180, 1000000], labels = [5, 4, 3, 2, 1], right = False). astype (float) rfm.head ()
运行结果如下:
| 用户 ID | R | F | M | R-SCORE | |
| 0 | uid 135460366 | 364 | 1 | 166.000000 | 1.0 |
| 1 | uid 135460367 | 364 | 1 | 117.000000 | 1.0 |
| 2 | uid 135460368 | 268 | 2 | 120.500000 | 1.0 |
| 3 | uid 135460369 | 352 | 2 | 208.500000 | 1.0 |
| 4 | uid 135460370 | 198 | 7 | 263.714286 | 1.0 |
短短一行代码就完成了 5 个层级的打分!这里我们再复习一下 Pandas 的 cut()方法。
口向第一个参数传入要切分的数据列。
口 bins 参数代表我们按照什么区间进行分组。上面我们已经确定了 R 值的分组区间,输入[0,30,60,120,180,1000000]即可。最后一个数值设置得非常大,是为了给分组一个容错空间,允许出现极端大的值。
口 labels 和 bins 切分的数组前后呼应,比如这里,bins 设置了 6 个数值,共切分了 5 个分组,labels 则分别给每个分组打标签,
口 right 表示右侧区间是开还是闭,即包不包括右边的数值:如果设置成 False,就代表仅包含左侧的分组数据而不包含右侧的分组数据,如[0,30);如果设置为 True,则首尾都包含,如[0,30]。
接着,F 值和 M 值就十分容易了,按照我们设置的值切分即可。
rfm['F- SCORE'] = pd.cut (rfm['F'], bins = [1, 2, 3, 4, 5, 1000000], labels = [1, 2, 3, 4, 5], right = False), astype (float) rfm['M- SCORE'] = pd.cut (rfm['M'], bins = [0, 50, 100, 150, 200, 1000000], labels = [1, 2, 3, 4, 5], right = False). astype (float) rfm.head ()
第一轮打分已经完成,结果如下:
| 用户 ID | R | F | M | R-SCORE | F-SCORE | M-SCORE | |
| 0 | uid 135460366 | 364 | 1 | 166.000000 | 1.0 | 1.0 | 4.0 |
| 1 | uid 135460367 | 364 | 1 | 117.000000 | 1.0 | 1.0 | 3.0 |
| 2 | uid 135460368 | 268 | 2 | 120.500000 | 1.0 | 2.0 | 3.0 |
| 3 | uid 135460369 | 352 | 2 | 208.500000 | 1.0 | 2.0 | 5.0 |
| 4 | uid 135460370 | 198 | 7 | 263.714286 | 1.0 | 5.0 | 5.0 |
下面进入第二轮打分环节。现在 R- SCORE、F- SCORE、M- SCORE 的取值范围是 1,2,3,4,5 这 5 个数,如果把这 3 个值进行组合,得到像 111,112,113 这样的值,可以组合出 125(53)种结果,分类结果太多,而过多的分类就失去了分类的意义。所以,我们通过判断每个用户的 R、F、M 值是否大于均值来简化分类结果。
每个用户的 R、F、M 值和均值对比后,只有 0 和 1(0 表示小于均值,1 表示大于均值)两种结果,可以组合出 8 个分组,是比较合理的情况。我们来判断用户的每个分值是否大于均值:
得到加上判断标签之后的结果,如图 11- 3 所示。
| 用户 ID | R | F | M | R-SCORE | F-SCORE | M-SCORE | R 是否大于均值 | F 是否大于均值 | M 是否大于均值 |
| 0 uid 135460366 | 364 | 1 | 166.000000 | 1.0 | 1.0 | 4.0 | 0 | 0 | 1 |
| 1 uid 135460367 | 364 | 1 | 117.000000 | 1.0 | 1.0 | 3.0 | 0 | 0 | 0 |
| 2 uid 135460368 | 268 | 2 | 120.500000 | 1.0 | 2.0 | 3.0 | 0 | 1 | 0 |
| 3 uid 135460369 | 352 | 2 | 208.500000 | 1.0 | 2.0 | 5.0 | 0 | 1 | 1 |
| 4 uid 135460370 | 198 | 7 | 263.714286 | 1.0 | 5.0 | 5.0 | 0 | 1 | 1 |
图 11- 3 R、F、M 值是否大于均值的判断结果
Python 中判断后返回的结果是 True 和 False,分别对应着数值 1 和 0,只要把这个布尔结果乘以 1,True 就变成了 1,False 就变成了 0。处理之后更加易读。
第五步:用户分层
回顾一下前几步操作,清洗完之后我们先确定了打分逻辑,接着分别计算出每个用户的 R、F、M 分值,随后用分值和对应的平均值进行对比,得到了是否大于均值的 3 列结果。至此,建模所需的所有数据已经准备就绪,剩下的就是用户分层了。
RFM 模型的经典分层会按照 R、F、M 每一项指标是否高于均值,把用户划分为 8 类,具体如表 11- 4 所示。
表 11-4 RFM 模型对应的分类
| R 是否大于均值 | F 是否大于均值 | M 是否大于均值 | 传统分类 | 改进后的分类 | 简单诠释 |
| 1 | 1 | 1 | 重要价值用户 | 重要价值用户 | 最近购买,高频,高消费 |
| 1 | 1 | 0 | 重要潜力用户 | 消费潜力用户 | 最近购买,高频,低消费 |
| 1 | 0 | 1 | 重要深耕用户 | 频次深耕用户 | 最近购买,低频,高消费 |
| 1 | 0 | 0 | 新用户 | 新用户 | 最近购买,低频,低消费 |
| 0 | 1 | 1 | 重要唤回用户 | 重要价值流失预警用户 | 最近未购,高频,高消费 |
| 0 | 1 | 0 | 一般用户 | 一般用户 | 最近未购,高频,低消费 |
(续)
| R 是否大于均值 | F 是否大于均值 | M 是否大于均值 | 传统分类 | 改进后的分类 | 简单诠释 |
| 0 | 0 | 1 | 重要挽回用户 | 高消费唤回用户 | 最近未购,低频,高消费 |
| 0 | 0 | 0 | 流失用户 | 流失用户 | 最近未购,低频,低消费 |
传统分类中的部分名称有些晦涩,比如,大多数分类前的“重要”“潜力”和“深耕”到底有什么区别?“唤回”和“挽回”有什么不一样?本着清晰至上的原则,我们对原来的名称做了适当的改进,强调潜力是针对消费(平均支付金额),深耕是为了提升消费频次,以及重要唤回用户其实和重要价值用户非常相似,只是最近没有回购而已,应该进行流失预警,等等。这里只是抛砖引玉,提供一个思路。总之,一切都是为了更易于理解。
我们对于每一类用户的特征也进行了简单诠释。比如,重要价值用户就是最近消费过,且在整个消费生命周期中购买频次较高、平均每次支付金额也高的用户。其他分类的逻辑也是一样的,可以结合诠释来增强理解。下面我们就用 Pandas 来实现这一分类。
先引入一个人群数值的辅助列,把之前判断的 R、F、M 值是否大于均值的 3 个值串联起来:
运行结果如图 11- 4 所示
| 用户 ID | R | F | M | R-SCORE | F-SCORE | M-SCORE | R 是否大于均值 | F 是否大于均值 | M 是否大于均值 | 人群数值 |
| 0 uid 135460366 | 364 | 1 | 166.000000 | 1.0 | 1.0 | 4.0 | 0 | 0 | 1 | 1 |
| 1 uid 135460367 | 364 | 1 | 117.000000 | 1.0 | 1.0 | 3.0 | 0 | 0 | 0 | 0 |
| 2 uid 135460368 | 268 | 2 | 120.500000 | 1.0 | 2.0 | 3.0 | 0 | 1 | 0 | 10 |
| 3 uid 135460369 | 352 | 2 | 208.500000 | 1.0 | 2.0 | 5.0 | 0 | 1 | 1 | 11 |
| 4 uid 135460370 | 198 | 7 | 263.714286 | 1.0 | 5.0 | 5.0 | 0 | 1 | 1 | 11 |
人群数值是数值类型的,在 Pandas 中位于前面的 0 会被自动略过。例如:1 代表“001”,即高消费唤回用户;10 代表“010”,即一般用户。
为了得到最终的人群标签,再定义一个判断函数,通过判断人群数值的值来返回对应的分类标签:
判断 R、F、M 值是否大于均值
def transform_label (x):
if x == 111: label
最后把标签分类函数应用到“人群数值”列:
rfm['人群类型'] = rfm['人群数值']. apply (transform_label) rfm.head ()
用户分类工作的完成宣告着 RFM 模型建模流程的结束。每一位用户都有了属于自己的 RFM 标签,如图 11- 5 所示。
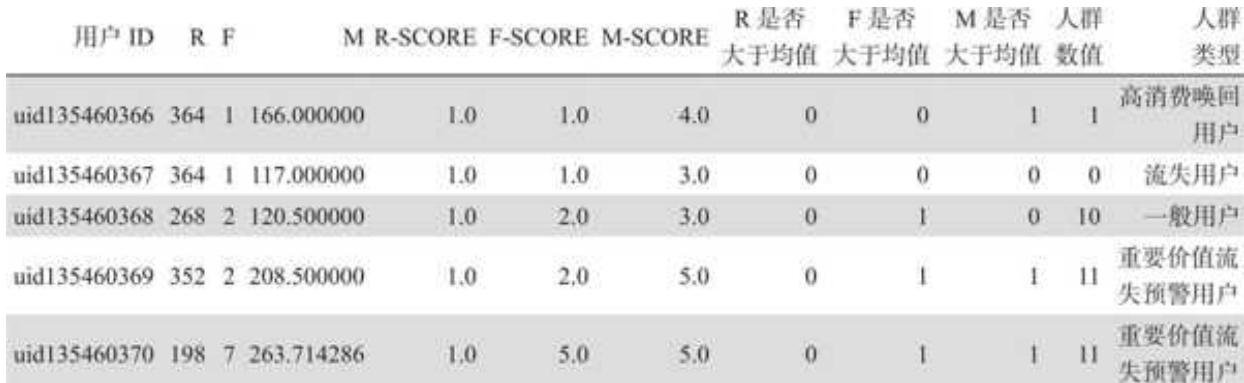
图 11-5 人群类型打标
RFM 模型结果分析
上一步其实已经走完了整个建模流程,但是一切模型的结果最终都要服务于业务,所以最后我们基于现有模型结果做一些拓展、探索性分析。
查看各类用户的占比情况:
得到不同类型用户的人数占比:
| 人群类型 | 人数 | 人数占比 | |
| 0 | 频次深耕用户 | 41696 | 0.307710 |
| 1 | 流失用户 | 20171 | 0.148859 |
| 2 | 高消费唤回用户 | 19783 | 0.145996 |
| 3 | 新用户 | 17232 | 0.127170 |
| 4 | 重要价值用户 | 16894 | 0.124675 |
| 5 | 重要价值流失预警用户 | 7795 | 0.057526 |
| 6 | 一般用户 | 6091 | 0.044951 |
| 7 | 消费潜力用户 | 5842 | 0.043113 |
探究不同类型用户的消费金额贡献占比:
rfm['购买总金额']
运行效果如下:
| 人群类型 | 消费金额 | 金额占比 | |
| 0 | 一般用户 | 1662222.0 | 0.036532 |
| 1 | 新用户 | 1756476.0 | 0.038604 |
| 2 | 流失用户 | 1822451.0 | 0.040054 |
| 3 | 消费潜力用户 | 2075644.0 | 0.045619 |
| 4 | 重要价值流失预警用户 | 5497744.0 | 0.120830 |
| 5 | 重要价值用户 | 14617966.0 | 0.321275 |
| 6 | 频次深耕用户 | 12407479.0 | 0.272693 |
| 7 | 高消费唤回用户 | 5659848.0 | 0.124393 |
对结果进行可视化,结果如图 11- 6 所示。
由上面的结果,我们可以快速得到一些推断。
口提升用户购买频次迫在眉睫,频次深耕用户是人群量级最大的用户群,人数占比高达
口用户流失问题需要关注,近期未购人群(流失用户+高消费唤回用户+重要价值流失预警用户+一般用户)占比达
再结合金额进行以下分析。
口重要价值用户人数占比只有
口流失用户人数占比
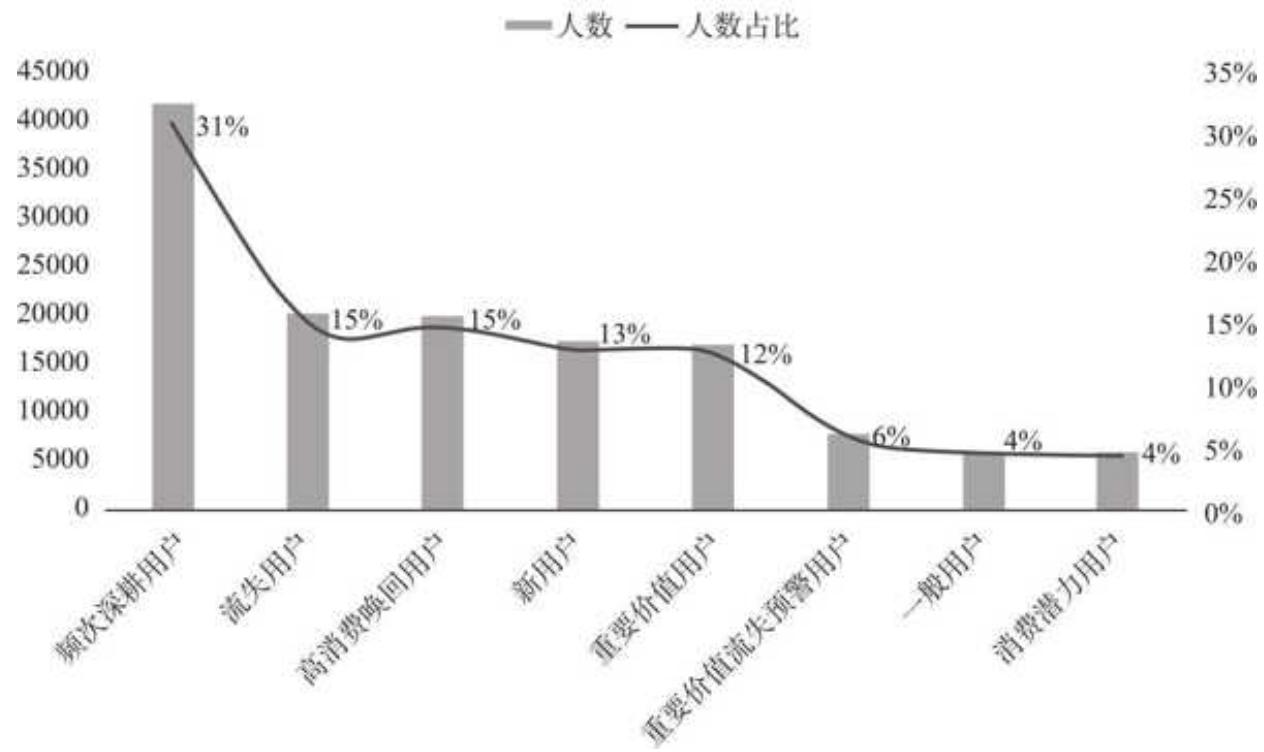
各类型用户人数分布及占比图 11-6 各类型用户的人数分布及占比
至此,我们基于订单源数据,按照五步法用 Python 完成了 RFM 模型的建立,并对结果进行了简单分析。最后,只要把上述代码封装成函数,对于新的数据源,只需按一下回车键就能生成模型结果,这实在是太酷啦!
11.3 关于 RFM 模型的重要思考
我们已经学习了使用 Pandas 建立 RFM 模型的全过程,完成了主线任务。接下来是个彩蛋,我带大家一起爬上 RFM 模型的肩膀,从更深的层次思考它,让普通的 RFM 变成加强版模型。
RFM 模型隐藏的问题
RFM 模型实在是太经典了,在人群分类模型中类似于神一般的存在。RFM 的传播和应用之所以能如此之广,离不开它的可解释性和易上手性。
其可解释性之强,足以让任何不懂数据的业务人员在 3 分钟内理解并初步认可模型的基本逻辑,开始念叨“不错,高价值活跃用户应该重点维护,流失用户要立即挽回”。
其易上手性在于只需 3 个字段(用户 ID、下单时间和下单金额),用任何工具(Excel、SQL、Python 等)都能实现。当然,用 Python 实现和复用更加高效。对于新手来说,从零实现,更是一次模型启蒙之旅,看看用户数据从表格变成模型结果,尤有一种“模型在手,天下我有”的飘然感。
业务人员好理解,模型易实现,梦幻般地一拍即合,天造地设。
在我面试过的求职者中,不少人会在简历的项目经历部分提到 RFM 模型的应用实践。对于他们,我会在面试中特别问到相关的问题,但回答令我满意的寥寥无几。
口为什么模型中的 R 值要用 30 天或者 60 天的间隔来区分?对应的业务合理性在哪里?
口用平均金额还是累计金额作为 M 更好?
口分类之后 RFM 具体是如何应用的?和不分类效果对比如何?又应当怎样去优化呢?
目前 RFM 模型应用技巧类的资料不少,但鲜见对于模型的深层思考。以上只是我提过的众多问题中的 3 个。在这里提出来,是希望抛砖引玉,引发大家对于模型的更多思考。我在工作中接触到不少分析人员过于沉浸于模型构建本身,而忽略了模型背后所隐藏的重要业务信息。从长期来看,后者无疑是更重要的。
下面,我以对“用平均金额还是累计金额作为 M 更好”这个问题的思考为例,带大家站在模型的肩膀上强化对于 RFM 模型的理解和认知。
为什么用平均金额作为 M
大家还记得本章开头对于 RFM 指标中 M 的定义吗?
我写的是“M 既可以是累计金额,也可以是平均金额”。事实上,目前绝大多数关于 RFM 的资料中 M 用的是累计金额,而上面的 Pandas 案例中用的是平均金额。
累计金额衡量的是每个用户会花多少钱,而平均金额衡量的则是用户平均每次购买会花多少钱。除了在指标计算上不同,两者还有什么差异呢?
1. 分类合理性
从分类合理性来看,累计消费满 2000 元的用户,很可能比累计消费 500 元的用户购买频次高,而几乎肯定比累计消费 50 元的用户购买频次高。更确切地说,如果用累计金额,那么 RFM 模型中的 F 和 M 将具有较高的相关性。而 RFM 模型的本质目的是将不同类型的用户分成不同的群组,两个相关性较强的指标最终的分类效果可能是会打折扣的。而平均金额则在一定程度上避免了这种问题。
2. 业务价值
从对业务的价值来看,重要价值用户,即 R、F、M 最终归为“高、高、高”的用户,是需要重点维护的。但在累计金额的口径下,很有可能存在不少高频次、低客单价的用户。例如 A 用户最近 10 天购买过,且历史购买过 100 次,平均每次购买 40 元,总金额达到 4000 元的水平。对于这类用户,应该通过关联推荐、定向优惠等方式促进他们提升客单价,而不是将他们放在重要价值用户的分类中,不进行有针对性的维护。
如果用平均金额统计,这类高频次、低客单的用户是会被分在另一个档位的。他们最近活跃,购买频次高,但平均消费金额低,属于“高、高、低"档的用户,需要重点提升客单价。这样分类对于业务人员来说更有的放矢。
当然,不只是重要价值用户,其他用户也会受到口径差异的影响。所以,在很多实际应用场景中,平均金额比累计金额更加合适。
11.4 RFM 模型的加强和拓展
模型加强和拓展的方向
上面介绍了如何在思维上让 RFM 变成加强版模型,这一节则从实践上来加强。RFM 模型从最后一次购买距今的时间、购买频次和消费金额三个维度对用户进行了分群,非常合理。不过,大部分行业的用户是存在生命周期的。
假如有 A 和 B 两个用户,他们的 R、F、M 值分别是 5、5、200,即最后一次购买距今 5 天,累计购买过 5 次。平均每次消费 200 元,在传统 RFM 的评估体系下,他俩是一样的。但是,如果 A 用户第一次购买是在 1 年前,B 用户第一次购买是在 1 个月前呢?
他们之间可能存在这样的差异。
口 A 用户:定期囤货型,每两三个月定期购买,但是消费金额越来越低,可能对品牌失去了新鲜感。
口 B 用户:狂热的新用户,在 1 个月内疯狂购买了 5 次,消费金额一次比一次高,或许是受到新的品牌代言人的影响。
A 和 B 拥有相同的 RFM 值,只因首次购买时间的不同而走向了不同的可能性。除了首次购买时间,还可以加上优惠偏好来区分用户对活动的敏感度,亦可以加上对应的用户属性(如性别)来加以区隔。
更丰富的数据维度让 RFM 的威力得到了加强。接下来我们实践一个具体的案例。
RFM 加强版实战案例
1. 引入用户最早支付时间
还记得前面我们对 rfm 做的备份吗?存在 rfm_copy 变量中:
| rfm_copy.head () | |||
| 用户 ID | R | F | |
| 0 | uid 135460366 | 364 | 1 |
| 1 | uid 135460367 | 364 | 1 |
| 2 | uid 135460368 | 268 | 2 |
| 3 | uid 135460369 | 352 | 2 |
| 4 | uid 135460370 | 198 | 7 |
这里我们加入每个用户最早支付时间的维度,计算每个用户首次购买时间距离“今天”有多少天,用 L 表示。
得到每个用户首次购买时间
r_first = rfm_df.groupby ('用户 ID')['付款时间']. min (). reset_index ()
计算首次购买时间距离“今天”多少天,和 R 的逻辑类似
r_first['L'] = (pd. to_datetime ('2024- 1- 1') - r_first['付款时间']). dt. days
把首次购买时间 L 列合并到原来的 rfm_copy 中
rfm_v 2 = pd.merge (rfm_copy, r_first '用户ID', 'L', left_on = '用户 ID', right_on = '用户 ID', how = 'inner')
rfm_v 2. head ()
得到了 R、F、M、L 四个指标的整合。
| 用户 ID | R | F | M | L | |
| 0 | uid 135460366 | 364 | 1 | 166.000000 | 364 |
| 1 | uid 135460367 | 364 | 1 | 117.000000 | 364 |
| 2 | uid 135460368 | 268 | 2 | 120.500000 | 364 |
| 3 | uid 135460369 | 352 | 2 | 208.500000 | 364 |
| 4 | uid 135460370 | 198 | 7 | 263.714286 | 364 |
前两个用户只购买过 1 次,他们的 R 和 L 值一样,后面用户的 R 和 L 值就出现了差异。
2. 数据标准化
在之前的 RFM 模型中,我们得到 R、F、M 值之后,采用的是维度打分、均值大小判断再分类的方法。加强版 RFM 增加了 L 指标,在实际的各种运用中可能还会加入更多的指标,再用传统的方法就不太合适了。
怎么办呢?机器学习中的聚类方法是一个解题思路。但是在聚类之前,需要把数据标准化,转化成同样的量纲,否则 R 值动不动就上百,而 F 值绝大部分在 5 以内。
这里我们可以用 z- score 方法进行标准化,公式如下。
用每一个值减去对应列的均值,然后除以标准差,便得到了新的值。z- score 把源数据转换成均值为 0、标准差为 1 的标准正态分布数据,消除了不同指标之间量纲的影响。用 Pandas 来操作很简单:
rfm v 2['R- zSCORE'] = (rfm_v 2['R'] - rfm_v 2['R']. mean ()) / rfm_v 2['R']. std () rfm_v 2['F- zSCORE'] = (rfm_v 2['F'] - rfm_v 2['F']. mean ()) / rfm_v 2['F']. std () rfm_v 2['M- zSCORE'] = (rfm_v 2['M'] - rfm_v 2['M']. mean ()) / rfm_v 2['M']. std () rfm_v 2['L- zSCORE'] = (rfm_v 2['L'] - rfm_v 2['L']. mean ()) / rfm_v 2['L']. std () rfm_v 2. head ()
运行之后,得到了标准化后的数据:
| 用户 ID | R | F | M | L | R-ZSCORE | F-ZSCORE | M-ZSCORE | L-ZSCORE |
| 0 | uid 135460366 | 364 | 1 | 166.000000 | 364 | 2.806266 | -0.405993 | -0.358883 |
| 1 | uid 135460367 | 364 | 1 | 117.000000 | 364 | 2.806266 | -0.405993 | -0.704324 |
| 2 | uid 135460368 | 268 | 2 | 120.500000 | 364 | 1.685194 | 0.327005 | -0.679650 |
| 3 | uid 135460369 | 352 | 2 | 208.500000 | 364 | 2.666132 | 0.327005 | -0.059265 |
| 4 | uid 135460370 | 198 | 7 | 263.714286 | 364 | 0.867746 | 3.991998 | 0.329985 |
3. 聚类分析
聚类算法有很多种,这里我们使用较为常用的 k- means 算法。
假定我们想把用户分成 k 个不同的类别,k- means 算法会随机选择 k 个聚类中心,并计算每个数据距离哪个聚类中心最近,然后持续优化聚类中心和每个数据的类别,最终得到稳定的分类结果。
算法细节参数等不详细展开,毕竟这一章的主线任务是 RFM 模型,这里只对 k- means 进行简要介绍,大家知道流程即可。
k- means 的使用很方便,可以直接调用 sklearn 里对应的库,输入我们要将用户分成的类数。假定我们想把用户分成 6 类,代码如下:
导入 k- means 所需要的库 from sklearn. cluster import KMeans 调用算法,n_clusters 是聚类的个数 ```
kmeans $=$ KMeans (n_clusters $= 6$ ,random_state $= 0$ ) #把标准化的R 、F、M、L 值传入模型,得到每个用户对应的分类(1\~6 类) y_pred $=$ kmeans. fit_predict (rfm_v 2[('R- zSCORE','F- zSCORE','M- zSCORE', 'L- zSCORE']) print (y_pred)
只需几行代码,就实现了最终的分类:
[2,2,2,0,0,3]
上面的数字代表着每个用户的分类(1~6 类)。还可以进一步看看具体聚类中心的值,将结果转化成我们熟悉的 DataFrame 格式:
kmeans_res
得到了 6 类用户对应的聚类中心值,这些中心值代表每种类别的特点:
| R-SCORE | F-SCORE | M-SCORE | L-SCORE | |
| 用户类别 1 | -0.814210 | -0.252356 | -0.053518 | -0.926829 |
| 用户类别 2 | -0.353118 | 1.536040 | -0.078633 | 1.095073 |
| 用户类别 3 | 1.792846 | -0.215479 | -0.095781 | 1.458931 |
| 用户类别 4 | -0.246259 | -0.287320 | 1.890083 | -0.402992 |
| 用户类别 5 | 0.281505 | -0.281165 | -0.621034 | 0.043490 |
| 用户类别 6 | -0.659406 | 5.663035 | 0.032109 | 1.572197 |
由于没有像标准 RFM 模型那样对每个类别的值打标,这里:
口 R- SCORE 越大,说明用户最近一次消费距离“今天”越远,也就是越久没来购买。口 F- SCORE 和 M- SCORE 分别对应购买频次和平均消费金额,越大则代表频次和金额越高。口 L- SCORE 越大,则表示用户首次消费距离“今天”越远,越可能是老用户。
例如:用户类别 3 的 R- SCORE 很大,表示这群用户最近没有消费;M- SCORE 偏小,说明他们的平均消费金额不高;L- SCORE 偏大,表明他们是很早进行首次消费的用户。这类用户可以概括为早期低客单价消费且流失的用户。其他分类也可以按照这个逻辑来解读。
到这一步,我们熟悉了 RFM 加入更多指标后应该如何分类,可以在实践中定制属于自己的加强版 RFM 模型。关于聚类算法更详细的原理、不同的聚类距离计算方式以及到底分成几类更合适等问题,感兴趣的读者可以自行了解 k- means 的更多细节。
11.5 本章小结
本章中,我们首先学习了用户分群的概念,并详细了解了分群和分层的差异。
接着,我向大家介绍了可以说是用户分群中最经典的 RFM 模型,并基于实际的数据,用 Pandas 手把手教大家通过五步法——数据概览、数据清洗、维度打分、分值计算和用户分层——建立 RFM 模型。
最后,从工作实践出发,我基于自己对于 RFM 的理解,抛砖引玉,带大家更深刻地认识这个模型,重新思考每个指标和操作背后的意义。同时,我也提出了 RFM 模型强化和拓展的方向,最后用一个实际的案例回答了“如何根据实际业务引入更多的指标建立加强版 RFM 模型”这个问题。