第12章 用户偏好分析
12.1 用户偏好分析和 TGI
用户偏好分析与 TGI 的关系
我们常说的用户偏好分析是一种分析方向,它基于用户属性和行为等数据,可以分析用户对于某些产品、服务或特征的喜好程度。通过用户偏好分析,品牌可以更好地了解目标客户群体的需求和行为特点,从而制定契合度更高的产品策略、宣传策略等。
TGI 是一种衡量和对比不同用户群体偏好程度的方法,具有逻辑清晰、计算便捷的特点,被广泛应用于各类用户偏好分析之中,而且效果都还不错。
那么,到底什么是 TGI 呢?
TGI 的定义
对于 TGI,百度百科上是这样解释的:TGI(Target Group Index,目标群体指数)用于反映目标群体在特定研究范围内强势或者弱势的程度。
这个解释有些晦涩难懂,简单翻译一下是:TGI 是一种反映偏好的指标。这样还是不够具体,我们可以结合 TGI 公式来理解。
TGI=目标群体中具有某一特征的群体所占比例
接下来,我们结合上面的公式详细解读 TGI 的计算逻辑。
通过拆解指标来理解 TGI
TGI 公式中有 3 个核心要素需要进一步拆解:某一特征、总体和目标群体。
举个例子,假设我们要研究 A 公司的脱发 TGI,则对应的 3 个核心要素如下。
口某一特征:我们想要分析的某种行为或者状态,这里是脱发或者受脱发困扰的状态。
口总体:我们研究的所有对象,即 A 公司所有人。
口目标群体:总体中我们感兴趣的一个分组。假设我们关注的分组是数据部,那么目标群体就是数据部。
于是,TGI 公式中的分子“目标群体中具有某一特征的群体所占比例"可以理解为"数据部脱发人数占数据部的比例”。假设数据部有 15 人,其中有 9 人受脱发困扰,那么数据部脱发人数占比就是 9/15,即
而分母"总体中具有相同特征的群体所占比例”,等同于“全公司受脱发困扰人数占公司总人数的比例”。假设公司共 500 人,有 120 人受脱发困扰,那么这个比例就是
于是,数据部脱发 TGI 为
TGI 具体数值是围绕 100 这个值来解读的:
TGI= 100,表示目标群体和总体在某特征或行为上的表现相同。
TGI > 100,表示目标群体在某特征或行为上的表现高于总体,具有较高的偏好程度,数值越大偏好越强。
TGI< 100,表示目标群体在某特征或行为上的表现低于总体,具有较低的偏好程度,数值越小偏好越弱。
刚才的例子中,数据部脱发 TGI 是 250,远远高于 100,看来在该公司做数据工作的人脱发风险较高。
下面,我们通过一个 TGI 的 Pandas 实例来巩固对概念的理解。
12.2 用 Pandas 实现 TGI 分析
项目背景
许久未见的老板又抛来一份订单明细,说道:“我们最近要推出一款价格比较高的产品,打算在一些城市先试销,你分析一下这份数据,看看哪些城市的用户有高客单价偏好,帮我筛选 5 个吧。”
你赶紧打开表格,看看数据的基本情况:
df = pd. read_excel ('用户偏好分析案例数据. xlsx')
print (df.head ()) print (df.info ())
数据预览如下:
品牌名称用户 ID 付款日期订单状态实付金额郭费省份城市购买数量 0 阿粥(小 z)uid 00524123 2023- 04- 18 交易成功 22.32 0 北京北京市 11 阿粥(小 z)uid 00524124 2023- 02- 17 交易成功 87.00 0 上海上海市 12 阿粥(小 z)uid 00524125 2023- 04- 18 交易成功 97.66 0 福建省福州市 23 阿粥(小 z)uid 00524126 2023- 01- 11 交易成功 37.23 0 河南省安阳市 34 阿粥(小 z)uid 00524126 2023- 02- 18 交易成功 29.50 0 河南省安阳市 2<class 'pandas.core.frame.DataFrame'>RangeIndex: 28832 entries, 0 to 28831 Data columns (total * columns): # Column Non- Null Count Dtype - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 0 品牌名称 28832 non- null object 1 用户 ID 28832 non- null object 2 付款日期 28832 non- null datetime 64[ns]3 订单状态 28832 non- null object 4 实付金额 28832 non- null float 645 邮费 28832 non- null int 646 省份 28832 non- null object 7 城市 28832 non- null object 8 购买数量 28832 non- null int 64 dtypes: datetime 64 ns, float 64 (1), int 64 (2), object (5) memory usage: 2.0+ MB
这份被告知不用再清洗的订单数据包括品牌名称、用户 ID、付款日期、订单状态和地域等字段,一共 28832 条数据,没有空值。
粗略看了几眼源数据,你想趁热打铁明确数据需求:“老板,高客单价的标准是什么?”
“就我们产品线和历史数据来看,单次购买超过 50 元的就算高客单价的用户了。”
确认了高客单价的标准之后,我们的目标非常明确:按照高客单价偏好对城市排序。这里的偏好可以用 TGI 来衡量,对应 TGI 计算的 3 个核心要素分别如下。
口特征:高客单价,即用户单次购买超过 50 元。口目标群体:各个城市,这里我们可以分别计算出所有城市用户的高客单价偏好。口总体:计算涉及的所有用户。解题的关键在于,计算出不同城市高客单价人数及其所占的比例。
用户打标
第一步,判断每个用户是否属于高客单价的人群。先按用户 ID 进行分组,看每个用户的平均每次支付金额。这里用平均,是因为有的用户会多次购买,而每次下单的金额可能不一样。
gp_user
得到每个用户的平均每次支付金额如下:
用户 ID 平均每次支付金额 0 uid 00324123 22.3201 uid 00324124 87.0002 uid 00324125 97.6603 uid 00324126 33.3654 uid 00324127 42.500
第二步,定义一个判断函数,如果单个用户平均每次支付金额大于 50 元,就打上“高客单价"的类别,否则为低客单价,再用 apply()方法调用:
def if_high (x): if
到这里,基于高低客单价的用户初步打标已经完成,结果如下:
| 用户 ID | 平均每次支付金额 | 客单价类别 | |
| 0 | uid 00324123 | 22.320 | 低客单价 |
| 1 | uid 00324124 | 87.000 | 高客单价 |
| 2 | uid 00324125 | 97.660 | 高客单价 |
| 3 | uid 00324126 | 33.365 | 低客单价 |
| 4 | uid 00324127 | 42.500 | 低客单价 |
匹配城市
我们已经得到单个用户的平均每次支付金额和客单价标签,下一步就是补充每个用户的地域字段。用 pd. merge()方法只需一行代码就能轻松完成。由于源数据是未去重的,我们必须先按用户 ID 去重,否则匹配的结果会有许多重复的数据。
#先去重df_dup =df. loc[df. duplicated('用户 ID')
匹配之后的结果如下:
| 用户 ID | 平均每次支付金额 | 客单价类别 | 省份 | 城市 | |
| 0 | uid 00324123 | 22.320 | 低客单价 | 北京 | 北京市 |
| 1 | uid 00324124 | 87.000 | 高客单价 | 上海 | 上海市 |
| 2 | uid 00324125 | 97.660 | 高客单价 | 福建省 | 福州市 |
| 3 | uid 00324126 | 33.365 | 低客单价 | 河南省 | 安阳市 |
| 4 | uid 00324127 | 42.500 | 低客单价 | 浙江省 | 衢州市 |
高客单价 TGI 计算
要计算每个城市的高客单价 TGI,需要得到每个城市高客单价、低客单价的人数分别是多少。用 Excel 的数据透视表处理起来很简单,直接把省份和城市拖曳到行的位置,把客单价类别拖曳到列的位置,值随便选一个字段,只要是统计就行。
这一套操作用 Python 实现起来也非常容易,用 pivot_table()透视表方法只需一行代码就能实现:
#先筛选出需要的列df_merge
再用透视表
result
运行代码,得到如图 12- 1 所示的聚合结果。
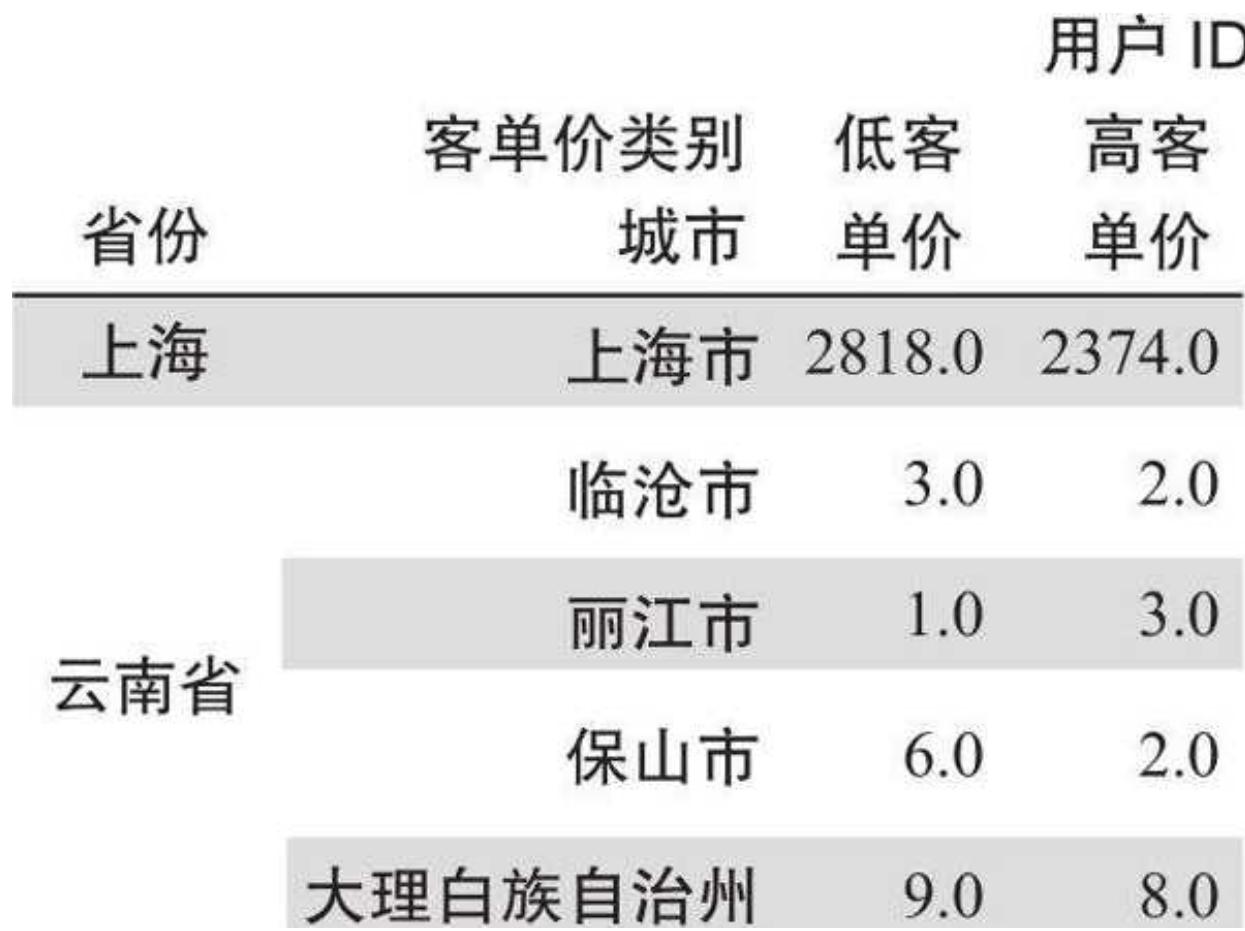
图 12-1 省市聚合的结果
这样得到的结果包含层次化索引,我们只要知道,要索引得到“高客单价”列,需要先索引“用户 ID”,再索引“高客单价”:
result['用户 ID']['高客单价']. reset_index (). head ()
运行结果如下:
省份城市高客单价 0 上海上海市 2374.01 云南省临沧市 2.02 云南省丽江市 3.03 云南省保山市 2.04 云南省大理白族自治州 8.0
这样就获取了每个省市的高客单价人数。然后再获取低客单价的人数,进行横向合并:
tgi = pd.merge (result['用户 ID']['高客单价']). reset_index (), result['用户 ID']['低客单价']. reset_index (), left_on = ['省份','城市'], right_on = ['省份','城市'], how = 'inner') tgi.head ()
得到我们熟悉的数据结构:
| 省份 | 城市 | 高客单价 | 低客单价 | |
| 0 | 上海 | 上海市 | 2374.0 | 2818.0 |
| 1 | 云南省 | 临沧市 | 2.0 | 3.0 |
| 2 | 云南省 | 丽江市 | 3.0 | 1.0 |
| 3 | 云南省 | 保山市 | 2.0 | 6.0 |
| 4 | 云南省 | 大理白族自治州 | 8.0 | 9.0 |
我们再看看每个城市总人数以及高客单价人数占比,来完成 TGI 公式中“目标群体中具有某一特征的群体所占比例”这个分子的计算:
tgi['总人数'] = tgi['高客单价'] + tgi['低客单价']tgi['高客单价占比'] = tgi['高客单价'] / tgi['总人数']
tgi.head ()
运行结果如下:
| 省份 | 城市 | 高客单价 | 低客单价 | 总人数 | 高客单价占比 | |
| 0 | 上海 | 上海市 | 2374.0 | 2818.0 | 5192.0 | 0.457242 |
| 1 | 云南省 | 临沧市 | 2.0 | 3.0 | 5.0 | 0.400000 |
| 2 | 云南省 | 丽江市 | 3.0 | 1.0 | 4.0 | 0.750000 |
| 3 | 云南省 | 保山市 | 2.0 | 6.0 | 8.0 | 0.250000 |
| 4 | 云南省 | 大理白族自治州 | 8.0 | 9.0 | 17.0 | 0.470588 |
有些非常小众的城市,其高客单价或者低客单价人数为 1 甚至为 0,而这些值尤其是空值会影响计算结果,因此我们要提前检核数据:
tgi.info ()
<class 'pandas.core.frame.DataFrame'> Int 64 Index: 346 entries, 0 to 345 Data columns (total 6 columns):
省份 346 non- null object 城市 346 non- null object 高客单价 332 non- null float 64 低客单价 329 non- null float 64 总人数 315 non- null float 64 高客单价占比 315 non- null float 64 dtypes: float 64 (4), object (2) memory usage: 18.9+ KB
果然,高客单价和低客单价都有空值(可以理解为 0),导致总人数也存在空值,而 TGI 对于空值来说意义不大,所以我们剔除掉存在空值的行:
tgi = tgi.dropna ()
接着统计总人数中高客单价人群的比例,来对标 TGI 公式中的分母“总体中具有相同特征的群体所占比例”:
total_percentage = tgi['高客单价']. sum () / tgi['总人数']. sum () print (total_percentage)
结果是 0.4153。
最后一步就是计算 TGI,顺便排个序:
tgi['高客单价 TGI'] = tgi['高客单价占比'] / total_percentage * 100 tgi = tgi. sort_values ('高客单价 TGI', ascending = False)
运行结果如图 12- 2 所示
| 省份 | 城市 | 高客单价 | 低客单价 | 总人数 | 高客单价占比 | 高客单价 TGI |
| 新疆维吾尔自治区 | 哈密市 | 4.0 | 1.0 | 3.0 | 0.800000 | 192.639702 |
| 新疆维吾尔自治区 | 巴音郭楞蒙古自治州 | 10.0 | 3.0 | 13.0 | 0.769231 | 185.230483 |
| 云南省 | 丽江市 | 3.0 | 1.0 | 4.0 | 0.750000 | 180.599721 |
| 甘肃省 | 白银市 | 3.0 | 1.0 | 4.0 | 0.750000 | 180.599721 |
| 吉林省 | 辽源市 | 2.0 | 1.0 | 3.0 | 0.666667 | 160.533085 |
| 四川省 | 广安市 | 6.0 | 3.0 | 9.0 | 0.666667 | 160.533085 |
| 广西壮族自治区 | 河池市 | 4.0 | 2.0 | 6.0 | 0.666667 | 160.533085 |
| 内蒙古自治区 | 锡林郭勒盟 | 2.0 | 1.0 | 3.0 | 0.666667 | 160.533085 |
| 黑龙江省 | 鹤岗市 | 2.0 | 1.0 | 3.0 | 0.666667 | 160.533085 |
| 山西省 | 临汾市 | 9.0 | 5.0 | 14.0 | 0.642857 | 154.799761 |
TGI 计算中隐藏的问题
得到了最终结果,你正打算第一时间报告老板。说时迟,那时快,在按下回车键(发送)之前你又扫了一眼数据,发现了一个严重的问题:高客单价 TGI 排名靠前的城市,总用户数几乎不超过 10 人,这样的高客单价占比完全没有说服力。
TGI 能够显示偏好的强弱,但很容易让人忽略具体的样本量大小,而小样本量往往意味着波动极大,TGI 很容易飙升到前面,这是需要格外注意的。
怎么办?为了加强数据整体的信度,可以先对总人数进行筛选,用总人数的平均值作为阀值,只保留总人数大于平均值的城市:
tgi. loc[tgi['总人数'] > tgi['总人数']. mean (),:]. head (10)
处理之后,这份数据结果看起来合理不少:
| 省份 | 城市 | 高客单价 | 低客单价 | 总人数 | 高客单价占比 | 高客单价 TGI | |
| 287 | 福建省 | 福州市 | 145.0 | 135.0 | 280.0 | 0.517857 | 124.699807 |
| 124 | 广东省 | 珠海市 | 49.0 | 52.0 | 101.0 | 0.485149 | 116.823582 |
| 27 | 北京 | 北京市 | 1203.0 | 1298.0 | 2501.0 | 0.481008 | 115.826450 |
| 283 | 福建省 | 厦门市 | 105.0 | 118.0 | 223.0 | 0.470852 | 113.380991 |
| 111 | 广东省 | 佛山市 | 118.0 | 135.0 | 253.0 | 0.466403 | 112.309708 |
| 173 | 江西省 | 南昌市 | 63.0 | 73.0 | 136.0 | 0.463235 | 111.546887 |
| 46 | 四川省 | 成都市 | 287.0 | 334.0 | 621.0 | 0.462158 | 111.287429 |
| 0 | 上海 | 上海市 | 2374.0 | 2818.0 | 5192.0 | 0.457242 | 110.103682 |
| 164 | 江苏省 | 无锡市 | 135.0 | 162.0 | 297.0 | 0.454545 | 109.454376 |
| 120 | 广东省 | 深圳市 | 438.0 | 528.0 | 966.0 | 0.453416 | 109.182440 |
“基于各城市高客单价 TGI,福州、珠海、北京、厦门和佛山是高客单价偏好排名前五的城市。咱们要试销的高客单价新产品,仅从客单价偏好角度,可以优先考虑这些城市。”你自信地发出了这段文字。
12.3 本章小结
TGI 是衡量和对比不同用户群体偏好程度的工具,我们理解了某一特征、目标群体和总体这 3 个概念,就掌握了它的本质逻辑。使用 Pandas 计算 TGI 的过程,就是探究“目标群体中具备某一特征的人”和“总体中具备某一特征的人”二者关系的过程。只有当 TGI>100 时,才能说明目标群体对该特征的偏好高于总体,且 TGI 越高,偏好越强。同时,在计算和应用 TGI 时,我们必须考虑样本量的影响,以避免在极小值样本量的情况下出现异常(极高或极低)的 TGI。