第13章 万能的同期群分析
13.1 数据分析师必知必会的同期群分析
同期群分析的基本概念
同期群分析是数据分析中的经典思维,其核心逻辑是将用户按初始行为的发生时间划分为不同的群组,进而分析相似群组的行为如何随时间变化。
我们用一个例子来感受同期群分析的具体内核。阿粥经常用下班时间在公司附近兼职烤淀粉肠,作为一个优秀的数据分析师,在兼职过程中他也没有忘记老本行,记录了每个月新购买的用户数,并统计每个月的新增用户在之后月份的复购情况。数据截止到 2023 年 7 月,如图 13- 1 所示。
数据的第一行,2023 年 1 月有 97 个新用户光顾。继续横向看,之后的
需要注意的是,第一行的
其他行也是一样的道理,每一行为同一个群组,反映同一期新增用户在之后一段时间复购行为的变化趋势。
| 阿粥 (小 z) 烤肠 | |||||||
| 月份 | 当月新增用户 | +1 月 | +2 月 | +3 月 | +4 月 | +5 月 | +6 月 |
| 2023 年 1 月 | 97 | 46% | 39% | 32% | 29% | 5% | 3% |
| 2023 年 2 月 | 112 | 56% | 46% | 42% | 4% | 1% | |
| 2023 年 3 月 | 332 | 50% | 44% | 2% | 1% | ||
| 2023 年 4 月 | 397 | 50% | 3% | 1% | |||
| 2023 年 5 月 | 388 | 3% | 1% | ||||
| 2023 年 6 月 | 782 | 20% | |||||
注:百分比为留存率,留存率
同期群分析的价值
现在我们知道什么是同期群分析了,但这有什么意义呢?
回到图 13- 1 中的那张烤肠用户留存表。如果没有同期群分析,我们得到的仅仅是每个月新购买人数的笼统数字,对于用户留存情况、用户生命周期这些是一头雾水,更不用说提什么建议了。
而基于同期群分析:
口横向,我们可以知道每个月新增用户的留存情况,发现 2023 年
口纵向,对比不同月份新增和留存情况,很容易发现 2023 年
原来,从 2023 年 6 月开始,阿粥不满足现在的人流量,换了一个人流量更大的摊位,且通过微信朋友圈和小红书引流,带来了一波线上流量。由于之前
同期群分析的万能之处
1. 期限自由
在上面的案例中,同期群分析是以月维度进行的。这个期限可以根据实际情况自由调整。例如,用日维度表示每一天的新增用户在后续各天的留存情况,如图 13- 2 所示。
也可以用周维度,如果数据期限足够长,甚至可以用年维度,期限的长短取决于分析目的。
2. 行为灵活
还记得最开始我们说过的“同期群分析是对相似群组的行为变化洞察”这个观点吗?上述案例中,我们把留存率或者说回购率中的回购,当作观察和分析的“行为”,而如果把“回购客单价”当作追踪分析的行为,就能观察到用户的另一个侧影,如图 13- 3 所示。
图 13-2 以日为期限的同期群表
| 日期 | 当日新增用户数 | +1 天 | +2 天 | +3 天 | +4 天 | +5 天 | +6 天 |
| 2023/1/1 | 97 | 46% | 39% | 32% | 29% | 5% | 3% |
| 2023/1/2 | 112 | 56% | 46% | 42% | 4% | 1% | |
| 2023/1/3 | 332 | 50% | 44% | 2% | 1% | ||
| 2023/1/4 | 397 | 50% | 3% | 1% | |||
| 2023/1/5 | 388 | 3% | 1% | ||||
| 2023/1/6 | 782 | 20% |
| 阿粥 (小 z) 烤肠 | |||||||
| 月份 | 当月新增用户数 | +1 月 | +2 月 | +3 月 | +4 月 | +5 月 | +6 月 |
| 2023 年 1 月 | 97 | 5.30 | 5.20 | 4.90 | 4.80 | 10.00 | 12.00 |
| 2023 年 2 月 | 112 | 5.20 | 5.30 | 5.20 | 11.00 | 10.00 | |
| 2023 年 3 月 | 332 | 5.50 | 5.45 | 12.00 | 10.00 | ||
| 2023 年 4 月 | 397 | 5.40 | 11.50 | 10.50 | |||
| 2023 年 5 月 | 388 | 11.00 | 12.00 | ||||
| 2023 年 6 月 | 782 | 3.80 | |||||
注:
图 13-3 基于回购客单价的同期群表
2023 年 1 月新增用户 97 人,他们在之后 4 个月内的回购客单价稳定在 5 元左右,但是在
当同期群分析表的“行为”从留存率变成了客单价,我们的分析视角和结论也随之转变。
3. 分组自主
前面的同期群分析都是以时间的维度来划分群组的,例如 2023 年 1 月新增的用户、2023 年 2 月新增的用户是不同的群组,分别观察他们在后续月份的行为趋势。我们也可以改变分组的逻辑,用渠道+月份来划分群组,如图 13- 4 所示。
如此一来,把不同渠道 1 月带来的新增用户放在了一起,对比新增用户规模和后续月份的留存率,用于评估不同渠道的拉新效果。
这里的分组还可以是商品、资源位、运营动作等任何需要评估的维度。
期限、行为和分组的高度自由,让同期群分析有了“万能”的称号。接下来,我们一起探索如何用 Pandas 实现同期群分析。
| 渠道 | 1 月新增用户 | +1 月 | +2 月 | +3 月 | +4 月 | +5 月 | +6 月 | |
| A 渠道 | 5436 | 46% | 39% | 32% | 29% | 25% | 23% | |
| B 渠道 | 2131 | 55% | 40% | 35% | 23% | 21% | 15% | |
| C 渠道 | 2311 | 49% | 42% | 40% | 35% | 32% | 28% | |
| D 渠道 | 15687 | 31% | 25% | 22% | 19% | 15% | 13% | |
| E 渠道 | 1389 | 51% | 46% | 41% | 38% | 32% | 25% | |
| F 渠道 | 789 | 65% | 61% | 54% | 51% | 49% | 47% |
图 13-4 以渠道分组的同期群表
13.2 Pandas 同期群分析实战
数据概览
在同期群分析的实战中,为了聚焦于同期群实现和分析本身,我们直接使用在第 10 章中清洗好的主订单表。这里将其整理成了单独的文件,导入即可。
df = pd. read_excel ('同期群分析实战案例数据. xlsx') print ('订单行数:', len (df))
df.head ()
数据预览如下:
订单行数:289386
| 品牌名 | 店铺名称 | 主订单编号 | 用户 ID | 付款时间 | 实付金额 | ||
| 0 | 阿粥(小 z) | 数据不吹牛 | 73465136654 | uid 135460366 | 2023-01-01 | 09:32:12 | 166 |
| 1 | 阿粥(小 z) | 数据不吹牛 | 73465136655 | uid 135460367 | 2023-01-01 | 09:11:50 | 117 |
| 2 | 阿粥(小 z) | 数据不吹牛 | 73465136656 | uid 135460368 | 2023-01-01 | 11:49:02 | 166 |
| 3 | 阿粥(小 z) | 数据不吹牛 | 73465136657 | uid 135460369 | 2023-01-01 | 12:20:24 | 77 |
| 4 | 阿粥(小 z) | 数据不吹牛 | 73465136658 | uid 135460370 | 2023-01-01 | 01:23:15 | 158 |
这份订单数据一共有 289386 行,包含同期群分析会用到的关键字段——用户 ID、付款时间和实付金额。
实现思路剖析
如何用 Pandas 实现同期群分析呢?
“磨刀不误砍柴工”,我们再回顾一下要实现的留存表(见图 13- 2)。
直接思考怎样一次性生成这张表,着实很费脑细胞,更合理的方式是用搭积木的思维来拆解这张表。
口表的每一行代表一个同期群,而它们的计算逻辑本质上是一样的:首先,计算出当月新增的用户数,并记录用户 ID;然后,拿这部分用户分别去和后面每个月购买的用户 ID 进行匹配,并统计有多少用户出现复购,即留存。
口只要计算出每个月的新增用户和对应的留存情况,再把这些数据合并在一起,就能得到我们梦寐以求的同期群留存表。
单月实现
循着上一步的思路,问题变得简单起来,我们先实现一个月的计算逻辑,其他月份沿用即可。
订单数据的时间维度和上面的留存表不太一样,因为不涉及时间序列,用字符串形式的“年- 月"标签会更加方便:
df['时间标签'] = df['付款时间']. astype (str). str[: 7] df['时间标签']. value_counts (). sort_index ()
运行之后得到了按月统计的订单数:
2023- 01 12039 2023- 02 4114 2023- 03 18172 2023- 04 12320 2023- 05 15738 2023- 06 44265 2023- 07 16102 2023- 08 28817 2023- 09 60376 2023- 10 21639 2023- 11 40204 2023- 12 15600 Name: 时间标签, dtype: int 64
订单源数据是从 2023 年 1 月开始,到 2023 年 12 月结束的。我们以 2023 年 2 月的数据为样板,实现单行的同期群分析。
month = '2023- 02' sample = df. loc[df['时间标签'] == month, :] print ('2 月订单数量:', len (sample)) sample_c = sample.groupby ('用户 ID')['实付金额']. sum (). reset_index () print ('2 月用户数量:', len (sample_c)) sample_c.head ()
运行结果如下:
2 月订单数量:4114 2 月用户数量:3313
用户 ID 实付金额 0 uid 135460385 390 1 uid 135460420 196 2 uid 135460422 188 3 uid 135460448 551 4 uid 135460471 237
显而易见,2023 年 2 月一共有 3313 位用户,完成了 4114 笔订单。
接下来,我们要计算的是每个月的新增用户数,而这个数据是需要通过与之前的月份遍历匹配来验证的。在案例数据中,2023 年 2 月之前的就是 2023 年 1 月用户的购买数据:
history = df. loc[df['时间标签'] == '2023- 01', :] history.head ()
历史数据预览如下:
品牌名店铺名称主订单编号用户 ID 付款时间买付金额时间标签 0 阿粥(小 z)数据不攻牛 73465136654 uid 1354603662023- 01- 0109:32:12166 2023- 011 阿粥(小 z)数据不攻牛 73465136655 uid 1354603672023- 01- 0109:11:50117 2023- 012 阿粥(小 z)数据不攻牛 73465136656 uid 1354603682023- 01- 0111:49:02166 2023- 013 阿粥(小 z)数据不攻牛 73465136657 uid 1354603692023- 01- 0112:20:2477 2023- 014 阿粥(小 z)数据不攻牛 73465136658 uid 1354603702023- 01- 0101:23:15158 2023- 01
与历史数据进行匹配,验证并筛选出 2023 年 2 月新增的用户数:
sample_c = sample_c.loc[sample_c['用户 ID']. isin (history['用户 ID']) == False,] print ('2023 年 2 月新增用户:',len (sample_c))
sample_c.head ()
新增用户数据预览如下:
2023 年 2 月新增用户:2740
用户 ID 实付金额 6 uid 135460486 237 106 uid 135461885 390 110 uid 135461902 196 113 uid 135461924 235 114 uid 135461927 235
然后,将这批新增用户和 2 月之后每个月的用户 ID 进行匹配,计算出每个月的留存情况:
re = []
for i in ['2023- 03', '2023- 04', '2023- 05', '2023- 06', '2023- 07', '2023- 08', '2023- 09', '2023- 10', '2023- 11', '2023- 12']: next_month = df. loc[df['时间标签'] == 1,!] target_users = sample_c.loc[sample_c['用户 ID']. isin (next_month['用户 ID']) == True,] re.append ([i, '留存情况: ', len (target_users)]) print (re)
得到了留存用户数据结果:
['2023- 03 留存情况:',558],['2023- 04 留存情况:',340],['2023- 05 留存情况:',379],['2023- 06 留存情况:',587],['2023- 07 留存情况:',293],['2023- 08 留存情况:',317],['2023- 09 留存情况:',267],['2023- 10 留存情况:',205],['2023- 11 留存情况:',304],['2023- 12 留存情况:',112]]
把最开始的当月新增用户加入列表:
re. insert(0,['2023 年 2 月新增用户:', len(sample_c)])re
运行便获得了 2023 年 2 月同期群的完整数据:
[「2023 年 2 月新增用户:,2740],[2023- 03 留存情况:,558],[2023- 04 留存情况:,340],[2023- 05 留存情况:,379],[2023- 06 留存情况:,587],[2023- 07 留存情况:,293],[2023- 08 留存情况:,317],[2023- 09 留存情况:,267],[2023- 10 留存情况:,205],[2023- 11 留存情况:,304],[2023- 12 留存情况:,112]]
2023 年 2 月新增用户 2740 位,次月留存 558 人,随后留存人数在起伏中有所下降。其他月份的新增和留存计算分析逻辑也是如此。
遍历合并和分析
上一步我们以 2023 年 2 月为样板,先根据历史订单匹配到当月纯新增用户,再以月的维度对后续每个月的用户进行遍历,验证用户留存数量。
为了便于循环,我们引入了月份列表:
monthlst
完整代码和关键注释如下:
引入时间标签 month_1 st = df['时间标签']. unique () final = pd.DataFrame () for i in range (len (month_1 st) - 1): # 构造和月份一样长的列表,方便后续格式统一 count = [0] * len (month_1 st) # 推选出当月订单,并按用户 ID 分组 target_month = df. loc[df['时间标签'] == month_1 st[i],'] target_users = target_month.groupby ('用户 ID')['实付金额']. sum (). reset_index () # 如果是第一个月,则跳过(因为不需要和历史数据验证是否为新增用户) if i == 0: new_target_users = target_month.groupby ('用户 ID')['实付金额']. sum (). reset_index () else: # 如果不是,找到历史订单 history = df. loc[df['时间标签']. isin (month_1 st[: i]),:] # 筛选出未在历史订单中出现过的新增用户 new_target_users = target_users. loc[target_users['用户 ID']. isin (history['用户 ID']) == False,:] # 将当月新增用户数放在第一个值中 count[0] = len (new_target_users) # 以月为单位,循环遍历,计算留存情况 for j, ct in zip (range (i + 1,len (month_1 st)), range (l,len (month_1 st}}}: # 下一个月的订单 next_month = df. loc[df['时间标签'] == month_1 st[i],:] next_users = next_month.groupby ('用户 ID')['实付金额']. sum (). reset_index () # 计算在该月仍然留存的用户数量 isin = new_target_users['用户 ID']. isin (next_users['用户 ID']). sum () count[ct] = isin # 格式转置 result = pd.DataFrame ({month_1 st[i]: count}). T # 合并 final = pd.concat ([final, result]) final. columns = ['当月新增', '+1 月', '+2 月', '+3 月', '+4 月', '+5 月', '+6 月', '+7 月', '+8 月', '+9 月', '+10 月', '+11 月'] print (final) 福利得到我们预期的数据,如图 13- 5 所示。
顺利得到我们预期的数据,如图 13- 5 所示。
| 当月新增 | +1 月 | +2 月 | +3 月 | +4 月 | +5 月 | +6 月 | +7 月 | +8 月 | +9 月 | +10 月 | +11 月 | |
| 2023-01 | 8193 | 573 | 1601 | 1050 | 1079 | 1906 | 815 | 1102 | 863 | 628 | 1049 | 372 |
| 2023-02 | 2740 | 558 | 340 | 379 | 587 | 293 | 317 | 267 | 205 | 304 | 112 | 0 |
| 2023-03 | 8753 | 1176 | 1232 | 2112 | 799 | 1032 | 777 | 616 | 1064 | 360 | 0 | 0 |
| 2023-04 | 5859 | 828 | 1208 | 502 | 618 | 482 | 329 | 526 | 171 | 0 | 0 | 0 |
| 2023-05 | 6912 | 1575 | 626 | 747 | 464 | 392 | 569 | 198 | 0 | 0 | 0 | 0 |
| 2023-06 | 16458 | 1575 | 1775 | 1153 | 923 | 1482 | 496 | 0 | 0 | 0 | 0 | 0 |
| 2023-07 | 6514 | 801 | 404 | 257 | 390 | 144 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-08 | 11781 | 1030 | 606 | 813 | 331 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-09 | 30214 | 2206 | 2482 | 971 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-10 | 11253 | 1147 | 452 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2023-11 | 18540 | 870 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
图 13-5 同期群留存数据
不过,真实数据是以留存率的形式体现的,我们再稍作加工:
result = final.divide (final ('当月新增'), axis = 0). iloc[:, 1:] result['当月新增'] = final['当月新增']
divide()方法用每列的复购人数除以对应的基期人数,得到期望的留存率表,放在 Excel 表中用条件格式美化一番,如图 13- 6 所示。
| 月份 | 当月新增用户 | +1 月 | +2 月 | +3 月 | +4 月 | +5 月 | +6 月 | +7 月 | +8 月 | +9 月 | +10 月 | +11 月 |
| 2023 年 1 月 | 8193 | 7.0% | 19.5% | 12.8% | 13.2% | 23.3% | 9.9% | 13.5% | 10.5% | 7.7% | 12.8% | 4.5% |
| 2023 年 2 月 | 2740 | 20.4% | 12.4% | 13.8% | 21.4% | 10.7% | 11.6% | 9.7% | 7.5% | 11.1% | 4.1% | |
| 2023 年 3 月 | 8753 | 13.4% | 14.1% | 24.1% | 9.1% | 11.8% | 8.9% | 7.0% | 12.2% | 4.1% | ||
| 2023 年 4 月 | 5859 | 14.1% | 20.6% | 8.6% | 10.5% | 8.2% | 5.6% | 9.0% | 2.9% | |||
| 2023 年 5 月 | 6912 | 22.8% | 9.1% | 10.8% | 6.7% | 5.7% | 8.2% | 2.9% | ||||
| 2023 年 6 月 | 16458 | 9.6% | 10.8% | 7.0% | 5.6% | 9.0% | 3.0% | |||||
| 2023 年 7 月 | 6514 | 12.3% | 6.2% | 3.9% | 6.0% | 2.2% | ||||||
| 2023 年 8 月 | 11781 | 8.7% | 8.0% | 6.9% | 2.8% | |||||||
| 2023 年 9 月 | 30214 | 7.3% | 8.2% | 3.2% | ||||||||
| 2023 年 10 月 | 11253 | 10.2% | 4.0% | |||||||||
| 2023 年 11 月 | 18540 | 4.7% |
图 13-6 用条件格式美化过的留存数据
终于,实现了我们所期望的同期群分析表。根据同期群结果数据,我们可以做一些用户维度的分析。
品牌销售具有很强的电商特征,大促效果显著。新增用户数排名前三的月份分别是 9 月、11 月和 6 月,对应 99、双 11、618 大促,品牌借平台活动之势,投入了大量的资源来获取新用户。99 为什么拉新人数高于双 11 和 618 呢?领导一看活动日历恍然大悟:“噢,原来当月产品上了×××的直播间啊!”
同时,我们发现留存率趋势走势“诡异”,根本不像教科书和我们预想中的逐月降低,而是呈现出起伏中下降的趋势,如图 13- 7 所示。
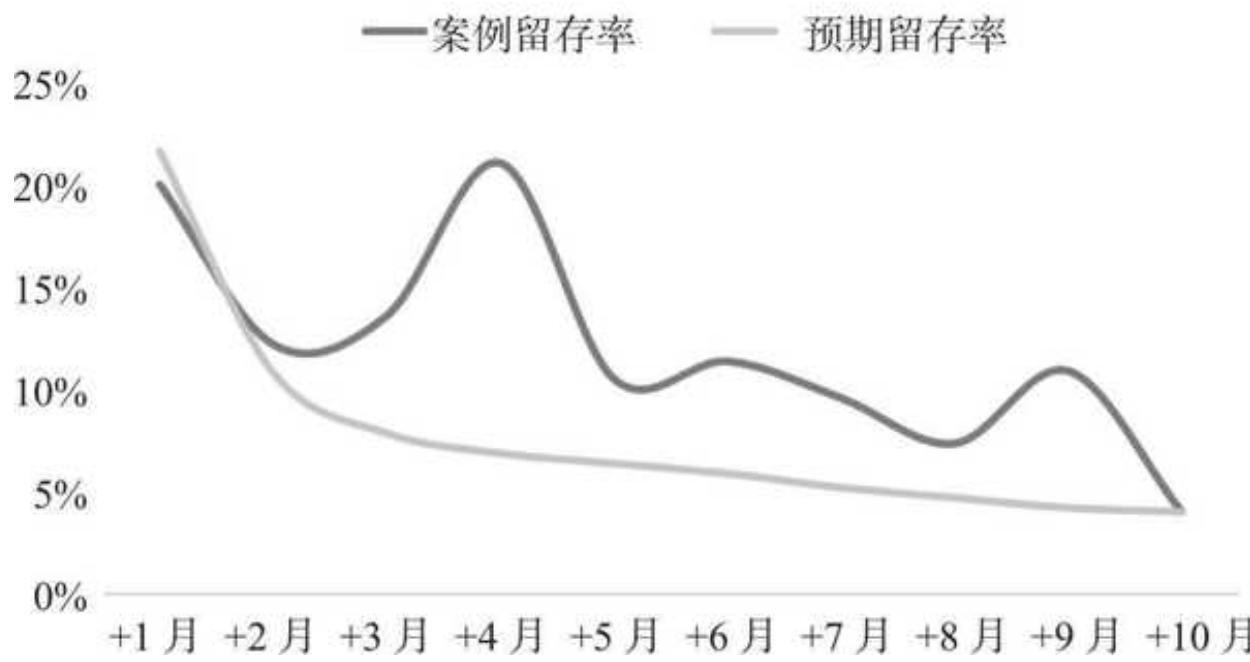
案例留存率和预期留存率趋势图 13-7 案例留存率和预期留存率趋势
例如 2023 年 2 月次月留存率
回购客单价的同期群实现
上面我们通过单月循环和遍历合并的方式实现了留存率的同期群分析,这一节我们来计算回购客单价的同期群表。
回购客单价等于回购用户的消费金额除以回购人数。以 2023 年 2 月为例,当月新增用户 2740 人,这群用户中有 558 人在 2023 年 3 月进行了回购,总共回购了 55800 元,则他们
刚才我们已经计算出每月新客在后续月份的回购人数,只需要再计算出这群人的回购金额,最终用回购金额除以回购人数,即可得到回购客单价。
因此,上面的代码几乎完全可以复用,把每个月新客在后续月份留存人数的统计改成金额即可:
#引入时间标签month_1st = df['时间标签']. unique ()# final 后面加了个 m,代表与金额相关 final_m = pd.DataFrame () #中间代码与上面计算留存率的代码相同 ... #计算在该月仍然留存的用户的回购金额isin_m = next_users. loc[next_users['用户 ID']. isin (new_target_users['用户 ID']) == True, '实付金额']. sum () count[ct] = isin_m #格式转置result = pd.DataFrame ({month_1 st[i]: count}). T #合并final_m = pd.concat ([final_m, result]) final_m.columns = ['当月新增', '+1 月', '+2 月', '+3 月', '+4 月', '+5 月', '+6 月', '+7 月', '+8 月', '+9 月', '+10 月', '+11 月']final_m
调整几行代码,便得到了每个月新增用户在后续的回购金额数据,如图 13- 8 所示。
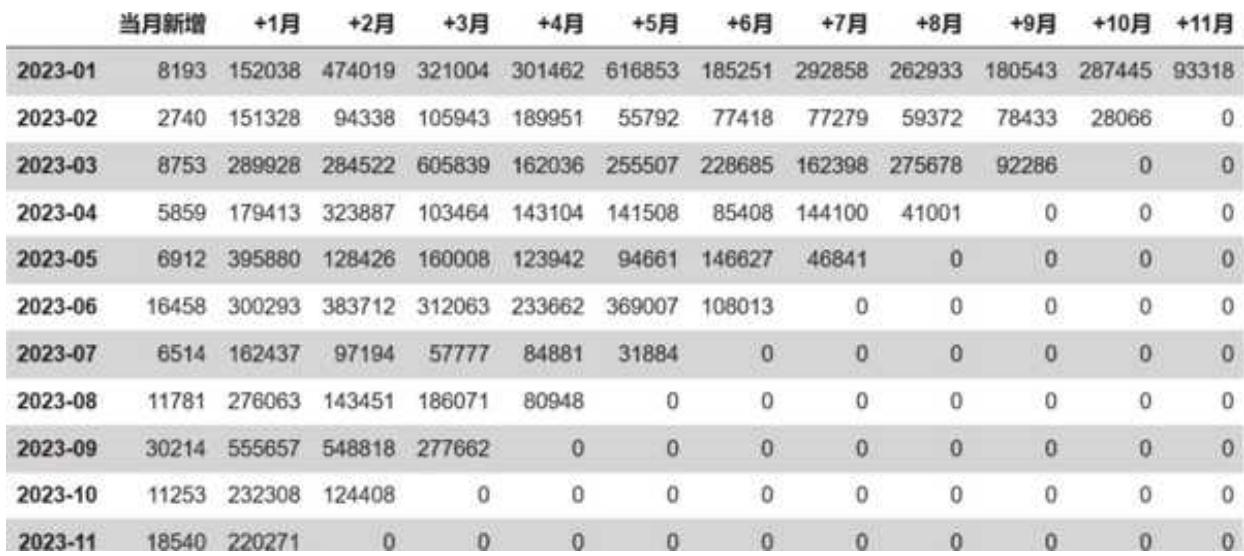
图 13-8 金额同期群数据
再用回购金额除以刚才已经计算好的回购人数,得到回购客单价:

将结果放在 Excel 表中用条件格式美化一下,如图 13- 9 所示。
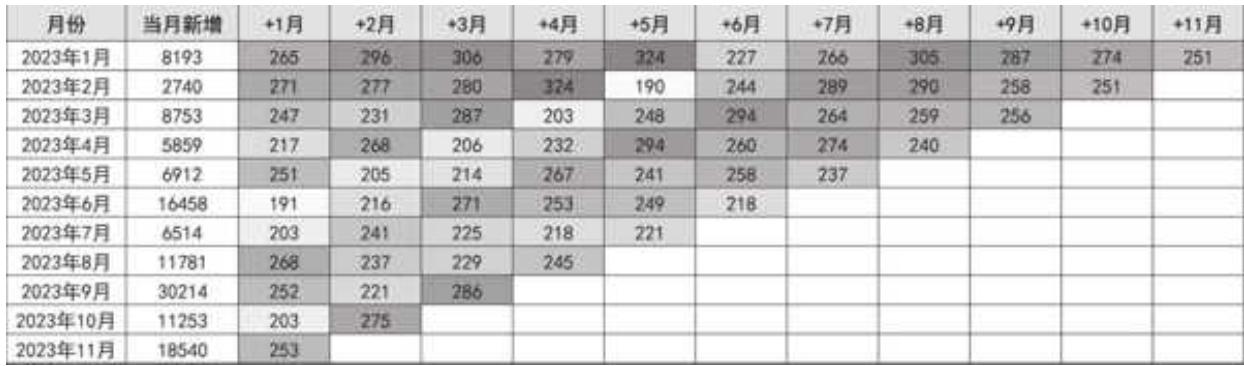
图 13-9 客单同期群数据
回购客单价也表现出用户在大促期间囤货的特点:2023 年 1 月的新用户在
至此,我们用 Pandas 实现了留存率和回购客单价的同期群分析。
本章小结
在本章中,我们首先学习了同期群的概念,并结合案例对于它的核心逻辑有了进一步的认知,即“将用户按初始行为的发生时间划分为不同的群组,进而分析相似群组的行为如何随时间变化”。
通过同期群的横向与纵向对比分析,我们能够基于同一群组捕捉到趋势规律和异常问题。同时,期限自由、行为灵活、分组自主是同期群的三大特点,助它成为一个适用范围极广的分析模型,被广泛应用于用户、商品、渠道等质量与效果的评估。
之后,我们用 Pandas 实现了同期群分析,和之前章节中的批量处理操作类似,主线思路遵循“单月实现、遍历合并”,这也是用 Pandas 解决复杂问题的万能钥匙,把一个大问题拆解成若干个相似的小问题,集中力量解决好其中一个小问题,其他的小问题用类似的方法都能攻克。