第15章 一份全面的品牌分析报告
15.1 探索性数据分析简介
常规的探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)是一种通过描述性统计、可视化等技巧对数据集进行分析的方法。“探索性”这三个字很好地总结了这种分析方法的特点,即通过对数据各指标、多维度的分析和观察,发现数据本身的结构与规律。
探索性数据分析的价值
探索性数据分析有两方面的价值:一方面,可以让我们快速了解数据集的质量并进行相关的处理,如调整字段格式、填补缺失值等;另一方面,让我们通过对指标进行分布与交叉分析,熟悉各指标的分布特征。例如,是否存在异常值,指标之间关联性如何。
不一样的探索性数据分析
除了具有上面两方面对于数据处理和统计建模分析的价值,探索性数据分析也是我们加深对数据认识的过程,更是我们熟悉数据背后的业务逻辑和商业逻辑的过程。
在探索中不断思考数据的业务逻辑,才能发挥它的最大价值。因此,本章介绍的探索性数据分析不只是指标分布、统计和关联上的探索,更侧重于业务层面的探索分析。
接下来,我们结合一个完整的电商实战项目,在巩固 Pandas 常用操作的同时,领略探索性数据分析的魅力。
15.2 数据预处理
通过前面的学习,我们对数据清洗和预处理操作已经有了初步认知。本章的项目分析将会带大家走一遍更完整的数据预处理流程,以期“温故而知新”。
数据导入
本章的电商实战项目案例数据是某品牌
数据导入非常简单,大家把 Python 切换到对应的路径并导入即可。
import pandas as pdimport os
避免以科学记数法显示 pd. set_option ('display. float_format', lambda x: '%. 2 f'%x) os.chdir (r'C:\本书配套资料\第 15 章品牌订单数据. xlsx') df = pd. read_excel ('第 15 章品牌订单数据. xlsx')
数据预览
使用 head()、info()和 describe()数据预览三件套,可以快速得到数据集的基础信息。
先是 head(),它默认获取前 5 行数据,结果如图 15- 1 所示。
| 品牌名称 | 店铺名称 | 主订单编号 | 子订单编号 | 用户 ID | 付款时间 | 子订单状态 | 商品 ID | 类目 | 购买数量 | 实付金额 | |
| 0 | 阿朋(/hz) | 数据不收件 | 34881213407 | 135460223541 | u 123382341 | 2021-01-02 00:10:16 | 交易成功 | P 1105 | NaN | 4 | 126 |
| 1 | 阿朋(/hz) | 数据不收件 | 34881213497 | 135460223542 | u 123382341 | 2021-01-02 00:10:16 | 交易成功 | P 1106 | NaN | 4 | 126 |
| 2 | 阿朋(/hz) | 数据不收件 | 34881213408 | 135460223543 | u 123382342 | 2021-01-02 12:53:15 | 交易成功 | P 1105 | NaN | 4 | 126 |
| 3 | 阿朋(/hz) | 数据不收件 | 34881213499 | 135460223544 | u 123382343 | 2021-01-02 13:00:47 | 交易成功 | P 1105 | NaN | 1 | 32 |
| 4 | 阿朋(/hz) | 数据不收件 | 34881213499 | 135460223545 | u 123382343 | 2021-01-02 13:06:47 | 交易成功 | P 1106 | NaN | 1 | 32 |
图 15-1 前 5 行数据样例
这份子订单数据乍看下来结构还挺完整,包含主订单编号、子订单编号、用户 ID、付款时间、子订单状态、商品 ID、类目、购买数量和实付金额等与交易相关的字段,但具体有多完整,还得进一步扫描。
print (df.info ()) print (df.describe ())
运行结果如下:
| df.info () | |||
| < class & #x27 ; pandas. core. frame. DataFrame& #x27 ;> | |||
| RangeIndex: 77598 entries, 0 to 77597 | |||
| Data columns (total 11 columns): | |||
| # | Column | Non-Null Count | Dtype |
| 0 | 品牌名称 | 77598 non-null | object |
| 1 | 店铺名称 | 77598 non-null | object |
| 2 | 主订单编号 | 77598 non-null | int 64 |
| 3 | 子订单编号 | 77598 non-null | int 64 |
| 4 | 用户 ID | 77593 non-null | object |
| 5 | 付款时间 | 77598 non-null | object |
| 6 | 子订单状态 | 77598 non-null | object |
| 7 | 商品 ID | 77591 non-null | object |
| 8 | 类目 | 68725 non-null | object |
| 9 | 购买数量 | 77598 non-null | int 64 |
| 10 | 实付金额 | 77598 non-null | int 64 |
dtypes: int 64(4),object(7) memory usage:
| df.describe () | ||||
| 主订单编号 | 子订单编号 | 购买数量 | 实付金额 | |
| count | 77598.00 | 77598.00 | 77598.00 | 77598.00 |
| mean | 34894520827.21 | 135461257002.43 | 1.73 | 445.86 |
| std | 4778485.95 | 370077.67 | 4.26 | 679.05 |
| min | 34881213497.00 | 135460223541.00 | 1.00 | 0.00 |
| 25% | 34896219414.00 | 135461365411.25 | 1.00 | 150.00 |
| 50% | 34896233058.50 | 135461385206.50 | 1.00 | 299.00 |
| 75% | 34896248387.75 | 135461405017.75 | 1.00 | 467.00 |
| max | 34896262115.00 | 135461424826.00 | 500.00 | 72054.00 |
由上面的结果可以发现以下问题。
口订单数据一共有 77598 行,用户 ID、商品 ID 有极少量的缺失值,而“类目”字段的缺失值较多。
口格式方面,由于订单编号都是数字,Pandas 读取时默认设置为 int 格式,这导致 describe()也把订单编号都当作数值进行了分析,而这部分可以忽略。
口数据存在异常值,单笔最大购买数量高达 500,最高实付金额竟然有 72054 元,绝对不是正常用户的购买行为。
整体看下来,订单数据还是比较规整的,只需解决上面几个问题即可。
重复项检验
在处理问题之前,要养成先校验重复项的好习惯。这里,我们通过以下代码来检查重复项。
检查重复项
duplicate_rows = df. loc[df.duplicated () == True] print ('重复项: \n', duplicate_rows)
对于存在重复项的数据集,直接将其删除
df. drop_duplicates (inplace=True)
上面的几行代码能够快速找到订单数据中完全重复的行,将其打印出来。这里订单数据不存在重复行,因此打印不出任何结果。
缺失值处理
1. 少量缺失值的处理
整体数据共计 77598 行,用户 ID 有 77593 行非空,商品 ID 有 77591 行非空,也就是说,实际用户、商品 ID 分别有 5 个和 7 个缺失值,占总体数据比重极低,直接把有缺失值的行删掉就行。
df = df. loc[(df['用户 ID']. isnull () == False) & (df['商品 ID']. isnull () == False), :] #统计数据集中每列缺失值的数量 print (df.isnull (). sum ())
我们用“&”来连接判断条件,要求用户 ID 和商品 ID 都不为空,再统计每个字段的缺失值数量,结果如下:
品牌名称 0 店铺名称 0 主订单编号 0 子订单编号 0 用户 ID 0 付款时间 0 子订单状态 0 商品 ID 0 类目 8866 购买数量 0 实付金额 0 dtype: int 64
2. 大量缺失值的处理情况
目前还有类目字段存在数量庞大的缺失值,贸然删掉可能会影响数据的结构,我们应该先诊断一下缺失值出现的原因。
一般情况下,出现如此多的缺失值,很有可能是由于系统性的因素,要验证问题是否出现在某一个明确的时间节点。我们从时间维度上看类目缺失是否存在规律:
构造一个年份的字段 df['年份'] = df['付款时间']. str[: 4]定义一个函数,判断传入的列有多少个缺失值 def ifnull (x): return x.isnull (). sum () #统计不同的年份有多少类目字段为空df . groupby (['年份'])['类目']. apply (ifnull)
得到各年份类目字段为空的统计结果如下:
年份 2021 88662022 02023 0 Name: 类目,dtype: int 64
无一例外,类目字段的 8866 个缺失值都出现在 2021 年,之后的都是正常的。对于这种情况,直接与相关的业务人员沟通,往往能够最快地找到原因。
果然,业务人员的说法是,因为 2021 年完全是以“散养”的状态运营的,没有人维护对应的类目表,从 2022 年开始到现在,都是正常维护的。
由于我们的分析主要聚焦在 2022 年和 2023 年,因此对于只出现在 2021 年的类目空缺值可以先不管。
异常值清洗
刚才我们发现购买数量和实付金额这两个字段存在异常值,从分析的角度来看,这两个指标存在较高的关联性,购买数量越多,实付金额往往就越大。要清洗异常值,这次我们先从购买数量入手,看看整体的分布情况。
把购买数量切分成不同的分组 num_group
计算不同购买数量占总体的比重 num_group[数量占比
num_group
运行结果如下:
| 购买数量 | 订单数量 | 订单数占比 | |
| 0 | [1, 2) | 60586 | 0.78 |
| 1 | [2, 3) | 7900 | 0.10 |
| 2 | [3, 4) | 2232 | 0.03 |
| 3 | [4, 5) | 1966 | 0.03 |
| 4 | [5, 6) | 1943 | 0.03 |
| 5 | [10, 11) | 993 | 0.01 |
| 6 | [6, 7) | 866 | 0.01 |
| 7 | [11, 500) | 516 | 0.01 |
| 8 | [9, 10) | 239 | 0.00 |
| 9 | [8, 9) | 220 | 0.00 |
| 10 | [7, 8) | 123 | 0.00 |
从购买数量占比分布来看,绝大部分订单的购买数量为 1,同时,有 516 笔订单的购买数量大于或等于 11,占总订单数的
在处理异常值的过程中,我们在与业务人员沟通后引入业务常识:在这个场景中,根据以往经验,单笔购买数量超过 10 的用户,刷单或“薅羊毛”的概率较大,且在此案例中的比例不大,可以当作异常值剔除。
df=df. loc[df['购买数量'] <= 10,:] df '购买数量','实付金额'. describe ()
剔除后我们再次描述统计结果:
| 购买数量 | 实付金额 | |
| count | 77068.00 | 77068.00 |
| mean | 1.56 | 438.63 |
| std | 1.50 | 525.80 |
| min | 1.00 | 0.00 |
| 25% | 1.00 | 150.00 |
| 50% | 1.00 | 299.00 |
| 75% | 1.00 | 467.00 |
| max | 10.00 | 6719.00 |
在剔除购买数量的异常值时,之前高达 72054 元的实付金额最大值也被同时剔除,目前实付金额最高为 6719 元,虽然偏高,但在业务人员认为的可控范围内。
异常值的处理还有其他方法,例如前文介绍过的四分位数法,还有基于 3 sigma 原则判断等。之所以这里采用“看分布,和业务人员沟通”的方式,是因为在实际分析工作中,分析是为了解决业务和商业问题,最终策略建议的执行也要靠业务人员,及时沟通并达成共识极其重要。
字段格式规整
格式方面没有太大的问题,数值型的订单号并不会影响后续的分析。不过,细心的读者可能已经注意到了,上面预览数据时,付款时间字段的格式是字符串,并非我们常用的 datetime,需要进行转换:
df['付款时间'] = pd. to_datetime (df['付款时间']) df['付款时间']
同时,考虑到付款时间是精确到时、分、秒的,而在后续分析时,常用的时间分组是年份、年月、年月日,为了方便,在这里加上这几个时间字段:
年份前面其实已经构造过了 df['年份'] = df['付款时间']. dt. year # 返回年份,如 2023 df['年月'] = df['付款时间']. astype (str). str[: 7] # 返回年月,如 2023- 01 df['年月日'] = df['付款时间']. astype (str). str[: 10] # 返回年月日,如 2023- 01- 01
订单状态筛选
对于订单类数据,订单状态的筛选会影响最终的结果。统计一下订单状态分布:
df['子订单状态']. value_counts ()
得到如下结果:
交易成功 76877 付款以前,卖家或买家主动关闭交易 123 付款以后用户退款成功,交易自动关闭 68 Name: 子订单状态, dtype: int 64
数据集中有 3 种订单状态,以交易成功为主,这里只针对交易成功的订单进行分析,做个筛选即可:
df = df. loc[df['子订单状态'] == '交易成功', :]
接下来,我们正式开启探索性数据分析之旅。数据分析有一定的探索性,但并不意味着漫无目的。对于这份订单数据,我们将采取先总后分的大逻辑,围绕电商核心指标展开。
15.3 数据总览分析
品牌体系化运营是从 2022 年开始的,因此我们的分析也主要聚焦在 2022 年和 2023 年。下面先从年的维度对数据进行总览分析。
年度销售额变化
销售额是电商的核心指标之一。要看两年销售额的变化,可以直接分组统计。
筛选出 2022 年和 2023 年的订单 data
按年份分组得到两年的销售额,并计算 2023 年销售额相较于 2022 年的环比变化情况。
年份实付金额 0 2022 86144181 2023 23233046 销售年环比增长:1.6970
从年度来看,品牌销售额可谓飙升,从 2022 年的 861 万元提升到 2023 年的 2323 万元,环比增长
年度用户数和客单价变化
从宏观视角分析用户交易数据变化,可以分为用户数、客单价两部分,代码直接参考年度销售变化的逻辑。
年度用户数变化 buyers_year
分别得到了年度用户数、客单价及对应的倍数,其中 nunique()跟在分组后面,统计的是年度去重用户数,运行结果如下:
年份用户数客单价 0 2022 5913 1456.861 2023 30403 764.17 用户数环比变化:4.1417 客单价环比变化:- 0.4755
结果显而易见,销售额增长背后的核心驱动力是用户数环比
看完了总览,我们再从用户和商品的角度做更细致的探索性数据分析。
15.4 用户数据分析
销售额和用户数月度趋势
通过数据总览分析,我们知道了销售额和用户数的快速增长态势,那么年度的增长对应到月份是怎样的趋势?是每个月都有差不多的提升,还是在某几个月集中爆发?
因此,我们要做月度趋势分析。先按月统计相关的指标:
按月统计用户数和实付金额 monthly_buyers = data.groupby (['年月']). agg ({'用户 ID': 'nunique', '实付金额': 'sum'}). reset_index () monthly_buyers['客单价'] = monthly_buyers['实付金额'] / monthly_buyers['用户 ID'] monthly_buyers. columns = ['年月', '用户数', '实付金额', '客单价']monthly_buyers.head ()
运行上述代码,得到 2022~2023 年按月统计的结果(这里仅列出前 5 项)。
| 年月 | 用户数 | 实付金额 | 客单价 | |
| 0 | 2022-01 | 376 | 211299 | 561.97 |
| 1 | 2022-02 | 248 | 163072 | 657.55 |
| 2 | 2022-03 | 485 | 632687 | 1304.51 |
| 3 | 2022-04 | 440 | 548360 | 1246.27 |
| 4 | 2022-05 | 435 | 512457 | 1178.06 |
然后绘制销售额和用户数的月度趋势图。
这里重温一下进行数据可视化需要导入的内容 import matplotlib. pyplot as pltimport numpy as np #这里只会用到NumPy生成1- 12 的序列
解决中文显示错误的问题 plt. rcParams['font. sans- serif'] = 'SimHei'让 Matplotlib 在 Jupyter Notebook 中输出高清矢量图%config InlineBackend. figure_format = 'svg'使画图可以直接在 Jupyter Notebook 中显示%matplotlib inline
柱子宽度 bar_width = 0.4
提取 2022 年相关的数据 monthly_buyers_2022 = monthly_buyers. loc{monthly_buyers['年月']. str[: 4] == '2022', :]提取 2023 年相关的数据 monthly_buyers_2023 = monthly_buyers. loc{monthly_buyers['年月']. str[: 4] == '2023', :]
fig = plt.figure (figsize = (10,7))
在上面的子图中绘制销售额柱状图 axl=plt. subplot(2,1,1)2022 年每月的销售额柱状图 plt. bar(np. arange(1,13)- bar_width/2,monthly_buyers_2022[实付金额/10000,width
2023 年每月的销售额柱状图 plt. bar(np. arange(1,13)+bar_width/2, monthly_buyers_2023[实付金额/10000,width
plt.title ('2022- 2023 年销售额月度趋势,size=13) plt.xticks (np.arange (1,13))
plt.legend ()
在下面的子图中绘制用户数趋势图 ax 2=plt. subplot(2,1,2)
2022 年每月的用户数柱状图
plt.bar (np.arange (1,13)- bar_width/2, monthly_buyers_2022[用户数],width
2023 年每月的用户数柱状图
plt.bar (np.arange (1,13)+bar_width/2, monthly_buyers_2023[用户数],width
plt. ylabel('用户数)
plt.title ('2022- 2023 年用户数月度趋势,size=13)
plt.xticks (np.arange (1,13))
plt.legend ()
结果如图 15- 2 所示。
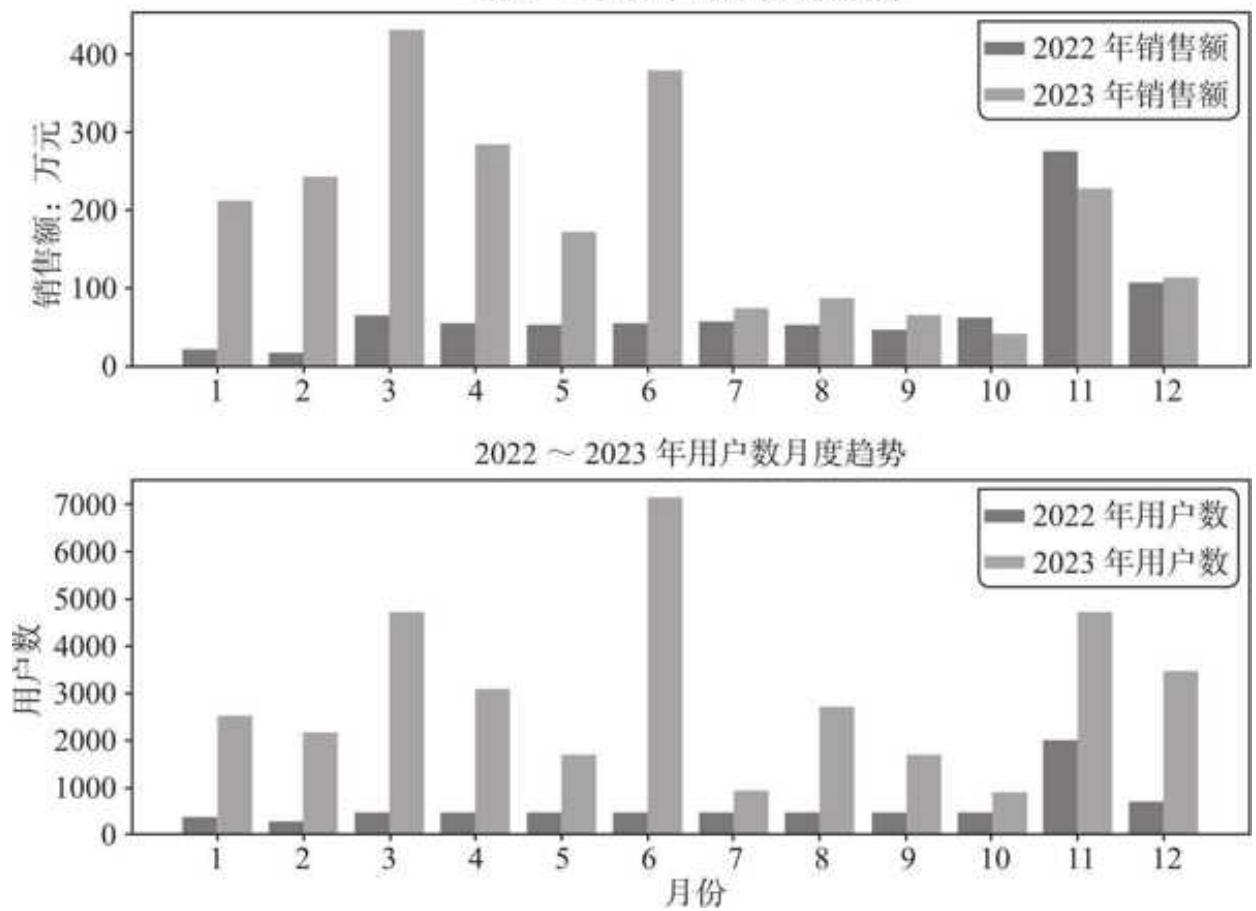
图 15-2 销售额和用户数月度趋势
销售额方面,2022 年销售额(黑色柱子)前期波澜不惊,全年只有 11 月销售大爆发,高达 277 万元,12 月迅速回落。2023 年开年即高歌猛进,前 6 月销售额均远远甩开去年同期,尤其是 3 月份达到了全年最高。但下半年略显疲态,7~10 月销售额下降至 2022 年同期水平,11 月较 10 月虽有成倍的增长,但不及 2022 年同期。
用户数月度趋势表现出和销售额较高的关联性,总体呈现出正向相关的关系。奇怪的是,2023 年 3 月的销售额高于 2023 年 6 月,但用户数则却远低于 2023 年 6 月,呈同样趋势的还有 2022 年 11 月与 2023 年 11 月。
客单价月度趋势
结合客单价的趋势数据,我们能建立对数据集所代表业务逻辑的更深的认识。按照同样的逻辑绘制客单价月度趋势图:
fig
两年的客单价趋势如图 15- 3 所示
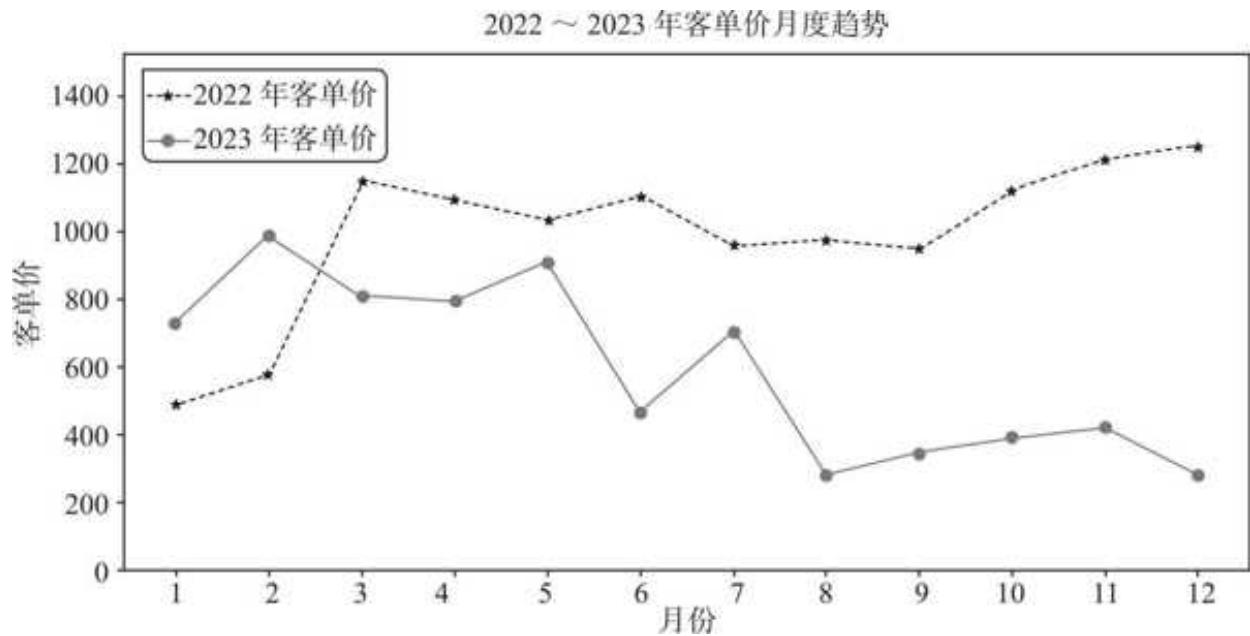
图 15-3 2022~2023 年客单价月度趋势
图 15- 3 清楚地刻画了两年的客单走势,除 2023 年前两个月客单价高于 2022 年同期外,其他月份均低于 2022 年同期,且客单价差距有不断拉大的趋势。
看上去 2023 年尤其是下半年品牌销售策略倾向于“薄利多销”,但从图 15- 2 可以看到,2023 年品牌销售增长主要归功于上半年的爆发,下半年销售十分疲软,品牌低价策略并未达到预期效果。
等一下,我们下这个定论是否过于轻率了?因为客单价并不是最细粒度的指标,客单价不断走低,既可能是用户买得更少了,也可能是用户买得更便宜了。
客单价细拆
为了更好地回答刚才提出的问题,我们可以进一步把客单价拆分为人均件数和件单价。人均件数是指每个用户平均购买几件商品,件单价则是平均每件商品的价格。
每月用户人数,购买数量(件数),消费金额 monthly_nums
运行之后,得到月度的人均件数和件单价数据(仅列出前 5 项)。
| 年月 | 用户数 | 购买件数 | 实付金额 | 人均件数 | 件单价 | |
| 0 | 2022-01 | 376 | 1434 | 211299 | 3.81 | 147.35 |
| 1 | 2022-02 | 248 | 1025 | 163072 | 4.13 | 159.09 |
| 2 | 2022-03 | 485 | 2047 | 632687 | 4.22 | 309.08 |
| 3 | 2022-04 | 440 | 1952 | 548360 | 4.44 | 280.92 |
| 4 | 2022-05 | 435 | 1842 | 512457 | 4.23 | 278.21 |
可视化一下,结果如图 15- 4 所示。可视化代码和前面的画图逻辑基本一致,将变量微调一下即可。为了更关注分析本身,这里省略了后续可视化的代码。
件单价月度趋势整体分成两个阶段:
口 2023 年
口 2023 年 6 月开始,件单价阶梯式大幅下滑,且维持在低位直到年末,件单价在 200 元左右徘徊。更低的件单价理应换来更多的购买数量,我们预期下半年的人均件数有较高的增长。
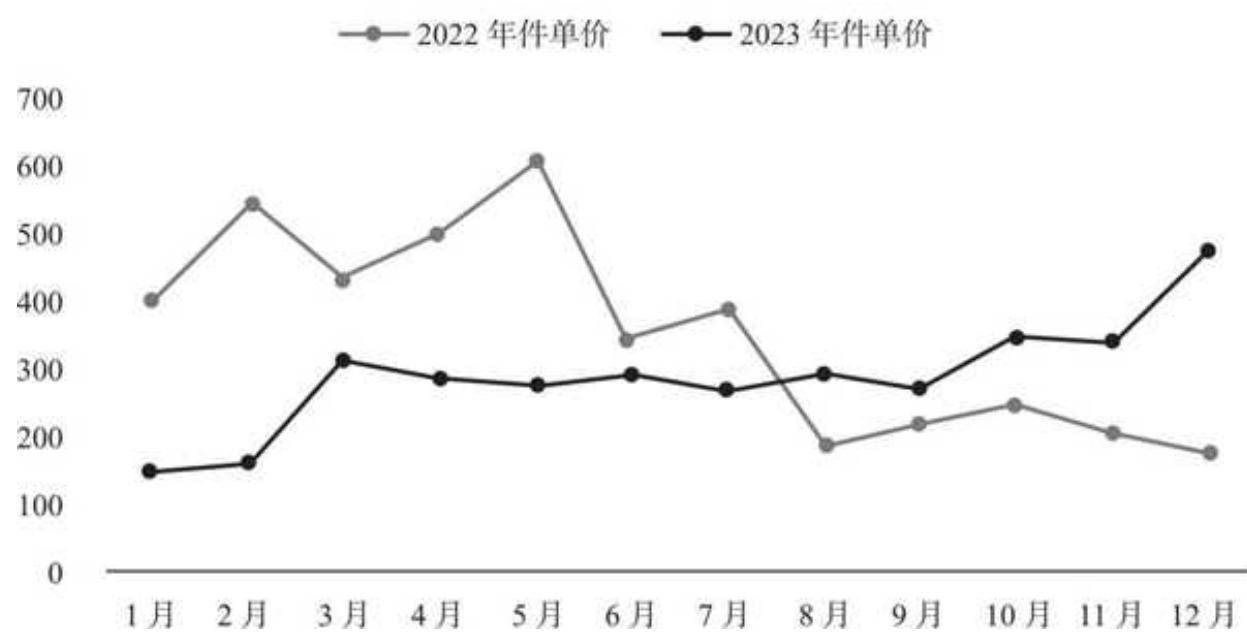
图 15-4 件单价月度趋势
件单价月度趋势
结合人均件数来看,如图 15- 5 所示。
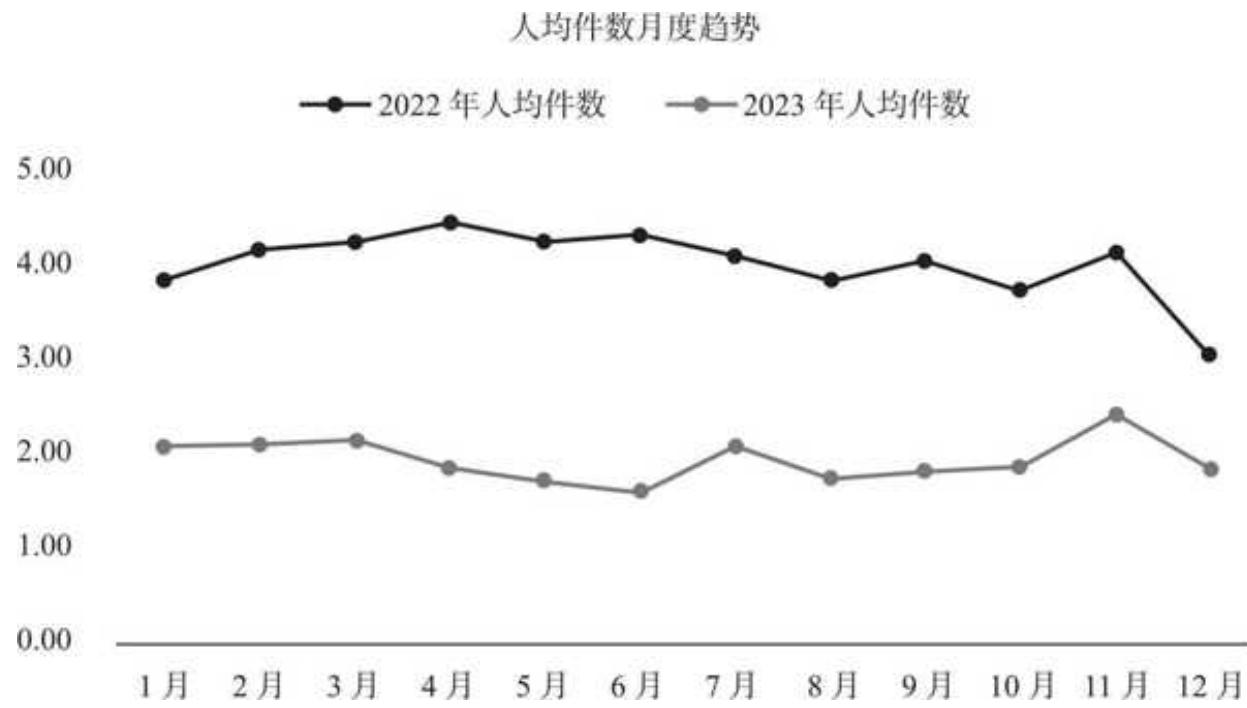
图 15-5 人均件数月度趋势
两年的购买件数有一种互不理睬的疏离感。2023 年人均件数稳定在 2 件上下,下半年件单价的降低并未带来预期中的人均件数的增长。“薄利”并未带来“多销”,件价(人均件数与件单价)齐降,这导致了 2023 年下半段客单价的明显下降。
新老用户分析
上述关于销售额、用户数、件单价及人均件数的拆解分析都是基于总体而言的,而在实际场景中,新老用户的购买行为和价值经常有很大差异,需要单独分析。
以 2022 年新老用户为例来分析。
口 2022 年新用户:2022 年 1 月 1 日前从未下过单,第一次下单是在 2022 年的用户。
口 2022 年老用户:2022 年 1 月 1 日前已经购买过,且又在 2022 年下单的用户。
其中新老用户之和即总用户数。
我们分别筛选出 2022 年和 2023 年的用户,并判断他们在之前是否购买过。
筛选出 2022 年和 2023 年的订单
data_2022
判断用户在之前是否购买过,返回 True 则表示之前购买过,为老用户
data_2022['用户类型']
data_com
判断完成之后,把对应的 True 和 False 转换成新老用户标签:
def if_new (x):
if
return‘老用户
else:
return‘新用户
data_com['用户类型']
data_com.head ()
如果为 True,则表示用户 ID 在之前出现过,是老用户,反之则是新用户。我们定义了一个简单的 if_new 函数并将其与 apply()方法结合,得到如图 15- 6 所示的新老用户的判断结果。
图 15-6 新老用户的判断结果
然后统计 2022 年和 2023 年新老用户对应的关键指标:
统计不同年份下新老用户的实付金额、用户数和购买数量
customers
客单价、人均件数、件单价
customers
customers
运行之后便得到图 15- 7 所示的结果,包含年份和新老用户交叉下的销售额(实付金额)、用户数、购买数量、客单价、人均件数、件单价等指标。
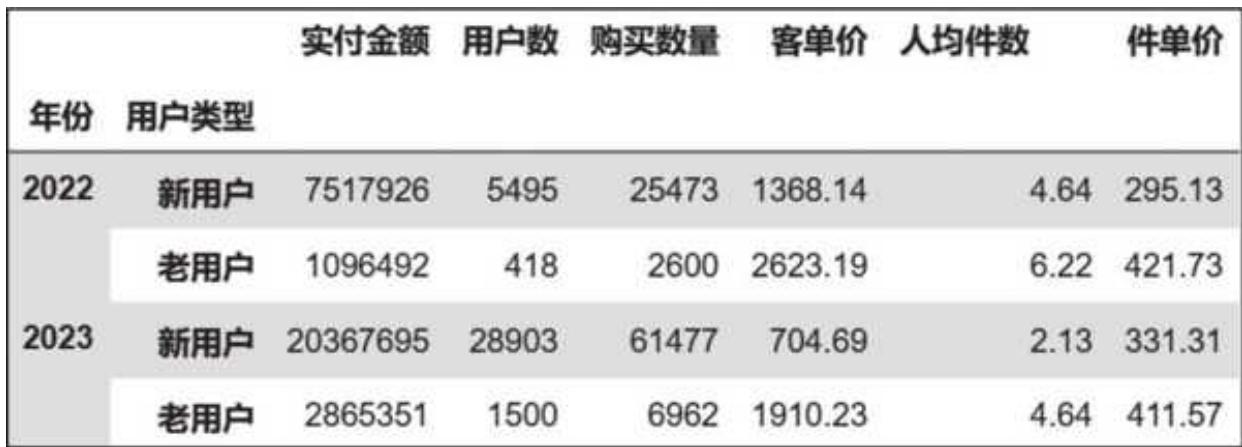
图 15-7 基于年度的新老用户数据
这种形式下计算环比不太方便,转置之后计算各项指标的变化趋势:
customers
新老用户对应的环比一目了然,如图 15- 8 所示。
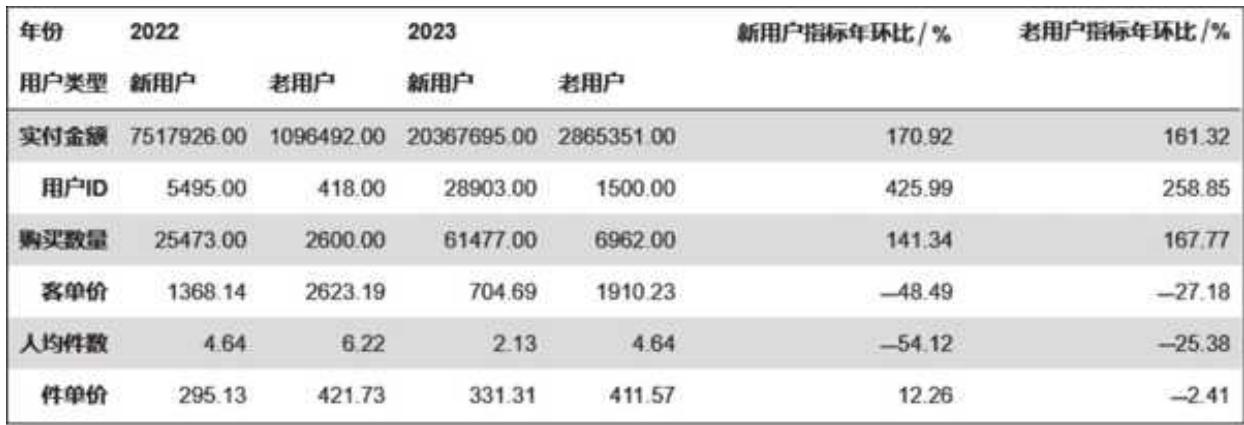
图 15-8 新老用户关键指标对比
新老用户共同推动了总体销售额的增长,新老用户销售额分别环比增长
复购率分析
复购率指统计时间范围内购买 2 次及以上用户的占比,是电商中衡量用户忠诚度的一个重要指标。
不过,现在很多品牌都有追单策略,即在用户下单之后的很短时间内给用户优惠券,引导用户再次下单。还有很多用户喜欢散漫性购买,上午 10 点下一单,下午 4 点逛了他又下一单。从数据上看,有不少用户连续两单的购买时间间隔极短,甚至在一天之内,这种行为严格来说不能算作复购(前面我们就采用的是这种处理逻辑)。
所以,这里我们还是按照“天”来计算复购率,即用户一天内购买多次只算一次。要实现这个效果,我们需要按天对用户购买进行合并:
repur_day
通过按用户 ID 和年月日字段分组,我们把 1 天内的用户购买行为合并,得到每个用户每天的实付金额。
用户 ID 年月日实付金额 0 u 123382345 2022- 09- 01 31581 u 123382345 2023- 02- 28 4672 u 123382346 2023- 02- 25 2643 u 123382353 2022- 11- 11 15684 u 123382353 2023- 11- 11 379
复购率的计算通常涉及较大的时间范围。接下来我们计算两年度的复购率,计算前先统计每年每个用户的购买天数:
为复购数据增加年份字段 repur_day['年份']
运行结果如下:
年份用户 ID 购买天数 0 2022 u 123382345 11 2022 u 123382353 1
2 2022 u 123382358 1 3 2022 u 123382364 1 4 2022 u 123382368 1
然后统计两年度购买天数大于或等于 2 的用户数:
统计每年总购买用户,上面的代码其实已经计算过,结果和这里的一样 buyers = repur_year.groupby (['年份']))['用户 ID']. count () # 计算每年购买天数大于或等于 2 的用户数 repur_count = repur_year. loc[repur_year['购买天数'] - - 2, :]. groupby (['年份'])['用户 ID']. count () print (buyers) print (repur_count)
得到如下结果:
年份 2022 5913 2023 30403 Name: 用户 ID, dtype: int 64
年份 2022 942 2023 4462 Name: 用户 ID, dtype: int 64
用购买天数大于或等于 2 的用户数除以总体用户: repur_count / buyers
运行之后便得到最终的两年复购率数据:
年份 2022 0.15932023 0.1468 Name: 用户 ID, dtype: float 64
相比于 2022 年,2023 年的复购率有所降低,可知整体用户忠诚度略有下降。
用户购买时间间隔
通过分析用户的购买时间间隔,找到用户的购买时间规律,可以有效支持 CRM(客户关系管理)做更精准的用户运营动作。
这里我们计算每个用户首次购买和第二次购买的间隔天数,并观察它们的分布。先把每个用户的购买时间进行天内合并,即一天的购买记录只取最早的一笔,和上一小节一样,以避免出现天内复购的情况。
每个用户天内合并,取当天最早一次购买时间,并按照升序排列 data_times
分组、排序,筛选出每个用户前两次的购买时间:
用户 ID 年月日购买时间 0 u 123382345 2022- 09- 01 2022- 09- 01 21:59:241 u 123382345 2023- 02- 28 2023- 02- 28 14:12:272 u 123382346 2023- 02- 25 2023- 02- 25 12:55:323 u 123382353 2022- 11- 11 2022- 11- 11 00:17:474 u 123382353 2023- 11- 11 2023- 11- 11 00:12:55
如果用户购买了多次,会返回前两次的购买时间;如果用户只购买了一次,则只能获取该用户的单次购买记录。而要计算购买时间间隔,是需要用户至少购买两次的,因此需要做一轮筛选:
统计每个用户的购买次数 users_count
运行之后,得到所有复购用户的购买时间。
| 用户 ID | 年月日 | 购买时间 | ||
| 0 | u 123382345 | 2022-09-01 | 2022-09-01 | 21:59:24 |
| 1 | u 123382345 | 2023-02-28 | 2023-02-28 | 14:12:27 |
| 3 | u 123382353 | 2022-11-11 | 2022-11-11 | 00:17:47 |
| 4 | u 123382353 | 2023-11-11 | 2023-11-11 | 00:12:55 |
| 7 | u 123382368 | 2022-04-17 | 2022-04-17 | 00:32:19 |
| 8 | u 123382368 | 2023-12-28 | 2023-12-28 | 14:00:41 |
在此基础上,筛选出每个用户首次购买时间和第二次购买时间,并计算时间间隔:
从筛选出的复购用户购买时间中,找到每个用户的首次购买时间和第二次购买时间 users_first
代码运行后,得到了每个用户的首次购买时间、第二次购买时间和它们之间的间隔天数:
| 用户 ID | 首次购买时间 | 第二次购买时间 | 首次和第二次购买的间隔天数 |
| 0 | u 123382345 | 2022-09-01 21:59:24 | 2023-02-28 14:12:27 |
| 1 | u 123382353 | 2022-11-11 00:17:47 | 2023-11-11 00:12:55 |
| 2 | u 123382368 | 2022-04-17 00:32:19 | 2023-12-28 14:00:41 |
| 3 | u 123382416 | 2022-01-19 16:16:28 | 2022-03-19 15:36:52 |
| 4 | u 123382445 | 2022-05-24 09:45:02 | 2022-07-20 17:16:58 |
有了这些数据,再做统计和分析就很容易了。统计首次和第二次购买间隔天数的分布:
users_com[首次和第二次购买的间隔天数']. value_counts (). reset_index ()
运行结果是不同间隔天数对应的人数:

把数据按照间隔天数分组统计并可视化,得到图 15- 9 所示的结果。
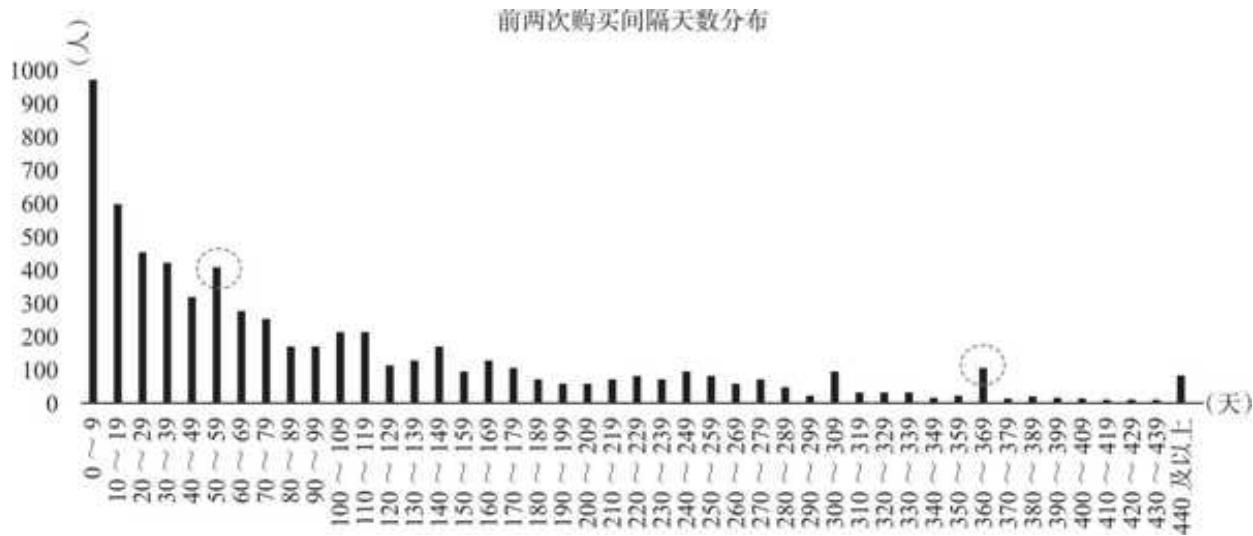
图 15-9 用户购买时间间隔分布
有很大一部分用户的第二次购买是在首次购买后 40 天内完成的,且 10 天内用户复购人数最多。值得注意的是,尽管我们对用户购买行为做了天内合并,但还是有 159 个用户的两次购买时间间隔归为 0 天,这是因为在 Pandas 计算中,间隔时间不足 24 小时(例如在 1 日 20 点首次购买,在 2 日 7 点第二次购买)算作 0 天。
50~59 天是另一个高峰区间,显著高于后续的区间人数,这个区间可以作为用户二次唤醒的时间节点。有意思的是,在后续的分布中,360~369 天的区间人数给人以“鹤立鸡群”之感,说明有一群人第二次购买和第一次隔了整整一年,他们很可能是价格敏感型用户甚至“薅羊毛”用户,等待最低价出手。
15.5 商品数据分析
基于用户关键指标月度趋势、客单价细拆、新老客分析、复购率和购买时间间隔分析,我们对于品牌用户有了一定的认知,下面切换视角,从商品维度进一步加深对于品牌业务的理解。
品类销售结构
品牌销售的是一个个具体的商品,这一个个商品属于不同的类目,例如精油、身体乳类目等。我们先从品类的维度看看店铺两年品类结构发生了怎样的变化。
cate_sales
用数据透视表 pivottable 交叉类目和年份这两个字段,看不同类目在两年间的用户数和销售变化情况,如图 15- 10 所示。
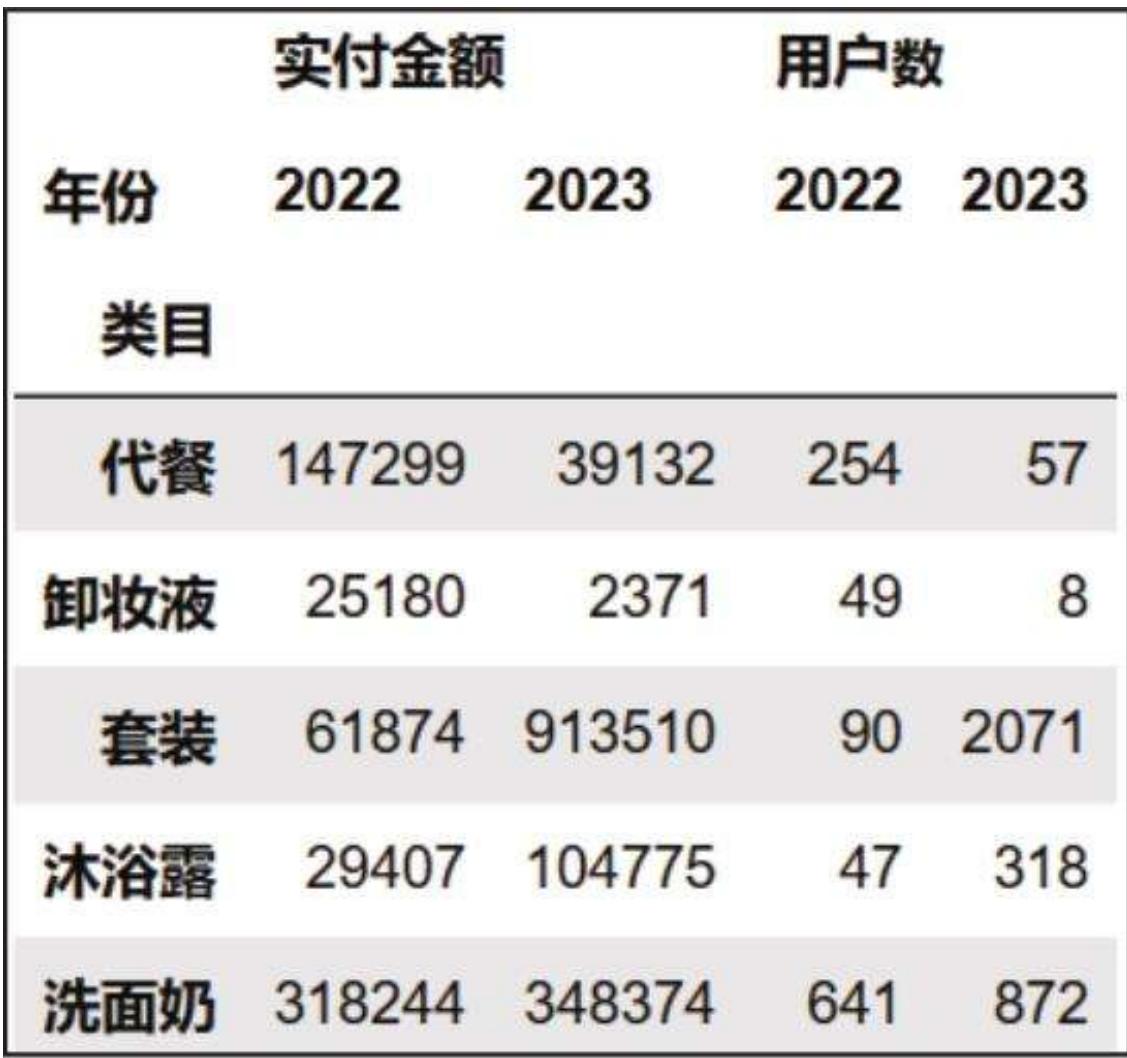
图 15-10 品类维度两年数据对比
对于几万、几百万的数值,大部分人是缺乏感知的,需要结合占比才能更清楚地看出不同品类的重要度。但 Pandas 透视表结果的 columns 是多层索引,进行占比和排序计算有点麻烦。
IN: print (cate_sales. columns)
MultiIndex([('实付金额',2022),(实付金额',2023),('用户数',2022),('用户数',2023)], names
可以通过先采用 reset_index()方法再改变 columns 名称来将索引转换成我们熟悉的索引:
cate_sales
把多层索引转换为单层
cate_sales. columns
计算对应类目的销售额占比
cate_sales['2022 年金额占比
代码运行后,得到图 15- 11 所示的结果。
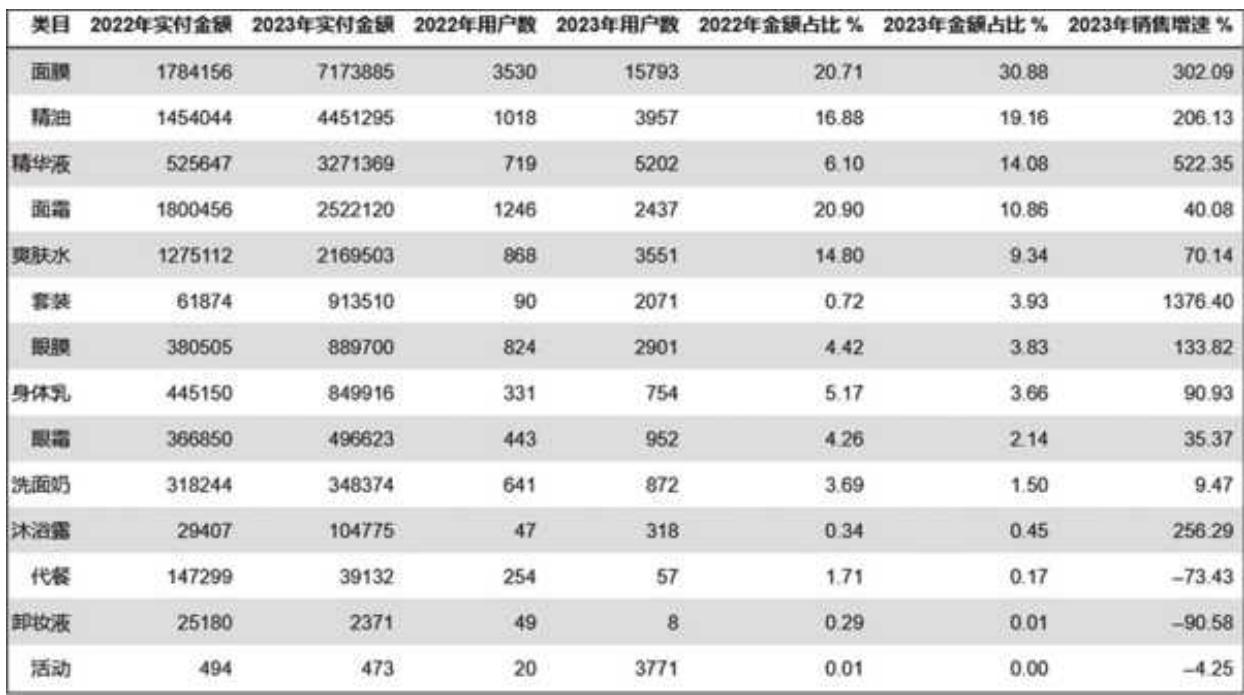
图 15-11 分品类的两年金额和人数对比
在上述数据的基础上进行可视化,结果如图 15- 12 所示。
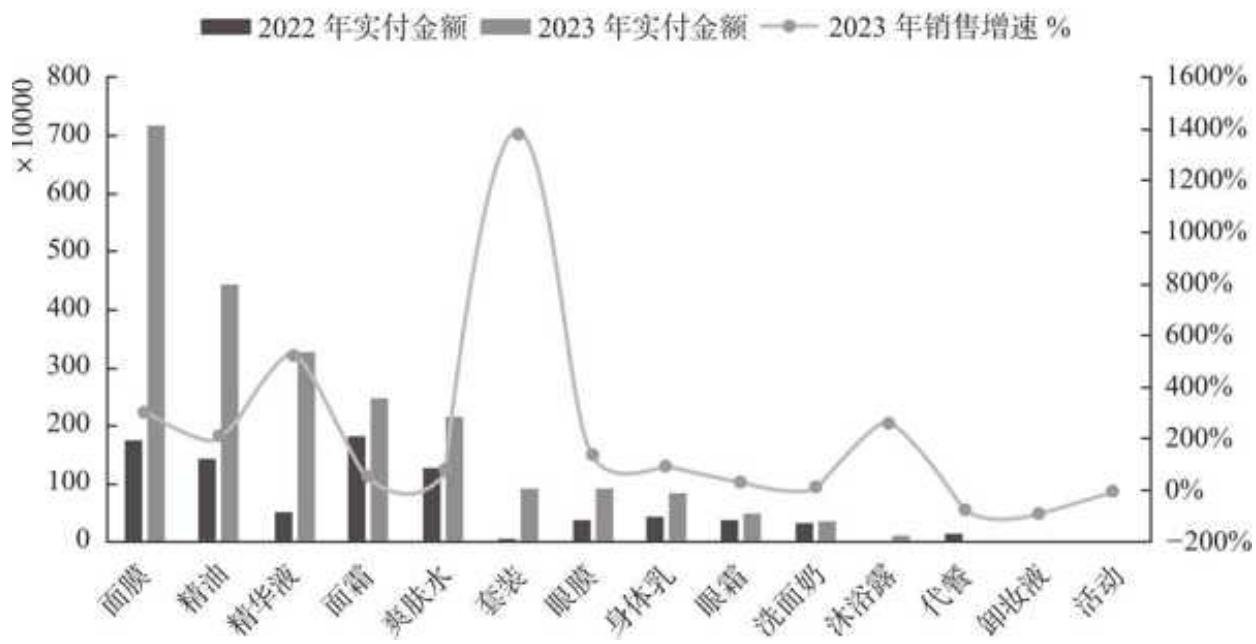
2022~2023 年各类目销售分布及增速图 15-12
由图 15- 12 可知,品牌两年的商品结构发生了显著变化。
口 2022 年多类目齐头并进,面膜、面霜是两大主力,销售占比为
口 2023 年类目策略调整,面膜成为绝对主力,一骑绝尘,销售占比提升至
从增速来看,(护肤)套装销售额年环比增速高达 1376%,不过由于 2022 年只有 6 万元销售额,如此高的销售增速下,(护肤)套装 2023 年销售额还是未破百万元。排名前三的面膜、精油和精华液增长迅猛,增速分别是 302%、206%和 522%。
价格带分析
我们常说的价格带是指一个范围,即对于某一分类下的商品,由其最低价格和最高价格形成的区间,如图 15- 13 所示。
| 分类 | A 款 | B 款 | C 款 | 价格带 |
| 衬衣 | 100 元 | 250 元 | 500 元 | 100~500 元 |
| 洗衣粉 | 20 元 | 50 元 | 120 元 | 20~120 元 |
图 15-13 价格带示例
在订单数据中,由于没有直接可用的价格字段,我们可以用实付金额除以购买数量,得到每件商品的实际成交金额并将其作为价格来辅助计算。这个实际成交金额是指除了优惠之后,用户最终支付的金额。
同一商品的实际成交金额会随着时间浮动,例如某商品的日常价是 10 元,而在 618 大促期间的价格是 8 元。这里我们以 2023 年为例,用每个商品的实付金额汇总除以购买数量汇总,得到一个平均的金额并将其作为价格。
data_23
代码运行后,得到每个类目下每件商品的成交价:
| 类目 | 商品 ID | 购买数量 | 实付金额 | 成交价 | |
| 0 | 代餐 | P 3282 | 12 | 3623 | 301.92 |
| 1 | 代餐 | P 3311 | 1 | 337 | 337.00 |
| 2 | 代餐 | P 3791 | 9 | 2718 | 302.00 |
| 3 | 代餐 | P 4178 | 16 | 4591 | 286.94 |
| 4 | 代餐 | P 4244 | 96 | 27863 | 290.24 |
在价格带数据的基础上,我们能够进行价格带的宽度、深度和广度分析。
1. 价格带的宽度
价格带的宽度指最高价格和最低价格的差值。宽度越大,表明价格范围越大,可能满足越多不同价格偏好的用户。
统计每个类目的最低和最高成交价 data_23_width
上述代码算出了 2023 年所有类目的价格带宽度,结果如下:
| 类目 | 最低成交价 | 最高成交价 | 价格带宽度 | |
| 10 | 精油 | 203.62 | 4407.00 | 4203.38 |
| 13 | 面霜 | 106.88 | 4197.00 | 4090.12 |
| 9 | 精华液 | 18.52 | 3486.00 | 3467.48 |
| 2 | 套装 | 4.00 | 3275.00 | 3271.00 |
| 12 | 面膜 | 0.00 | 2798.00 | 2798.00 |
| 8 | 眼霜 | 212.90 | 2152.00 | 1939.10 |
| 11 | 身体乳 | 138.69 | 1965.00 | 1826.31 |
| 4 | 洗面奶 | 76.00 | 1801.00 | 1725.00 |
| 6 | 爽肤水 | 83.66 | 1680.00 | 1596.34 |
| 7 | 眼膜 | 13.23 | 969.00 | 955.77 |
| 3 | 沐浴露 | 129.50 | 442.02 | 312.52 |
| 0 | 代餐 | 286.94 | 337.00 | 50.06 |
| 1 | 卸妆液 | 270.00 | 300.14 | 30.14 |
| 5 | 活动 | 0.00 | 14.25 | 14.25 |
不同类目的价格带宽度差异极大。例如:精油类目下,最便宜的商品成交价 203.62 元,最高竟然达到 4407 元,价格带宽度达 4203.38 元。价格带宽度最低的活动类目下,价格带宽度只有 14.25 元,商家以极低的价格吸引用户购买。
2. 价格带的深度
价格带的深度可以理解为价格带中有多少款商品,越深表示这个价格带有越多的产品可供选择。价格带深度的计算更加容易:
data_23_depth
以上代码按照商品分组,统计了每个分组下的商品数量,结果如下:
| 类目 | 价格带深度 | |
| 12 | 面膜 | 249 |
| 10 | 精油 | 109 |
| 13 | 面霜 | 74 |
| 6 | 爽肤水 | 71 |
| 4 | 洗面奶 | 42 |
| 7 | 眼膜 | 38 |
| 9 | 精华液 | 34 |
| 11 | 身体乳 | 34 |
| 8 | 眼霜 | 20 |
| 2 | 套装 | 13 |
| 5 | 活动 | 7 |
| 3 | 沐浴露 | 6 |
| 0 | 代餐 | 5 |
| 1 | 卸妆液 | 2 |
面膜价格带宽度不如精油,但价格带深度却是精油的 2 倍多,有非常丰富的商品线。沐浴露、代餐和卸妆液只是品牌的长尾品类,商品数量不足 10 个。
3. 价格带的广度
价格带的广度看的是价格带中不同价格的数量。例如,A 品类价格带是 10~100 元,宽度为 90 元,其中 10 元的商品有 4 个,50 元的商品有 6 个,100 元的商品有 30 个。从价格带的广度能够很快发现,A 品类 100 元左右的商品有很多选择。
广度的计算用一行代码就可以完成:
data_23_breadth = data_23.groupby (['类目','成交价'])['商品 ID']. count (). reset_index () data_23_breadth
运行之后得到我们想要的结果:
| 类目 | 成交价 | 商品 ID | |
| 0 | 代餐 | 286.94 | 1 |
| 1 | 代餐 | 290.24 | 1 |
| 2 | 代餐 | 301.92 | 1 |
| 3 | 代餐 | 302.00 | 1 |
| 4 | 代餐 | 337.00 | 1 |
| ... | ... | ... | ... |
| 468 | 面霜 | 1750.00 | 4 |
| 469 | 面霜 | 1783.00 | 2 |
| 470 | 面霜 | 2236.00 | 1 |
| 471 | 面霜 | 3846.00 | 2 |
| 472 | 面霜 | 4197.00 | 1 |
| 473 | rows × 3 columns |
刚才计算价格的时候我们精确到了两位小数,所以价格会比较散,在实际分析中,我们可以根据情况对价格进行分组,例如面霜
商品销售集中度分析
商品的销售集中度分析能够帮助我们进一步明确品牌的商品销售策略。所谓销售集中度分析,是把商品按销售额进行降序排列,计算前 N 个商品的销售额占总销售额的比重,以观察销售额的集中情况。例如,计算发现 2023 年销售额前 10 的商品合计销售额占比 50%,而 2022 年这一占比只有 30%,说明销售额在进一步向头部商品集中。
不过,如果品牌两年的商品数量发生了巨大变化,假如 2022 年有 100 款商品,2023 年有 1000 款商品,只筛选各自排名前 10 的商品对比,从数量上看对 2023 年是不太公平的。这时候可以借鉴分位数的概念,把两年的商品按照前 10%、前 20%分位对数据进行切分,通过对比对应分组的数据变化,观察品牌增长来源于头部还是长尾,是向头部商品集中还是更加分散。
用 Pandas 来实现的逻辑是先按商品 ID 聚合,排序再切分:
2022 年商品的处理逻辑 data_prod_22
金额降序排列后,用 qcut()方法把数据分成了 10 等份,并打上对应的分组排名标签:
| 商品 ID | 实付金额 | 累计金额占比 | 商品分组排名 | |
| 205 | P 3376 | 329348 | 0.04 | 前 10% |
| 38 | P 3207 | 303730 | 0.07 | 前 10% |
| 213 | P 3384 | 295677 | 0.11 | 前 10% |
| 307 | P 3479 | 267924 | 0.14 | 前 10% |
| 237 | P 3408 | 217562 | 0.16 | 前 10% |
| ... | ... | ... | ||
| 287 | P 3458 | 29 | 1.00 | 90%~100% |
| 219 | P 3390 | 29 | 1.00 | 90%~100% |
| 212 | P 3383 | 29 | 1.00 | 90%~100% |
| 457 | P 3629 | 13 | 1.00 | 90%~100% |
| 166 | P 3336 | 11 | 1.00 | 90%~100% |
刚才处理的是 2022 年商品的数据,对于 2023 年的数据采用完全一样的处理逻辑,我们把结果保存在变量 data_prod_23 中,然后分别把两年的数据按商品分组排名,统计对应的销售额及占比:
按商品分组排名后统计 prod_gp_22 = data_prod_22.groupby ('商品分组排名')['实付金额']. sum (). reset_index (). sort_values ('实付金额', ascending=False) prod_gp_23 = data_prod_23.groupby ('商品分组排名')['实付金额']. sum (). reset_index (). sort_values ('实付金额', ascending=False)# 计算对应的累计占比 prod_gp_22['累计金额占比'] = prod_gp_22['实付金额']. cumsum () / prod_gp_22['实付金额']. sum () prod_gp_23['累计金额占比'] = prod_gp_23['实付金额']. cumsum ()/ prod_gp_23['实付金额']. sum ()# 两年数据合并 prod_gp_com = pd.merge (prod_gp_22, prod_gp_23, left_on = '商品分组排名', right_on = '商品分组排名', how = 'inner') prod_gp_com. columns = ['商品分组排名', '2022 年金额', '2022 年累计金额占比', '2023 年金额', '2023 年累计金额占比']prod_gp_com 代码运行之后,返回了两年不同分组排名的商品的对应金额及占比:
代码运行之后,返回了两年不同分组排名的商品的对应金额及占比:
| 商品分组排名 | 2022 年金额 | 2022 年累计金额占比 | 2023 年金额 | 2023 年累计金额占比 |
| 0 | 前 10% | 549131 | 0.64 | 17531205 |
| 1 | 10%-20% | 1427228 | 0.80 | 2709950 |
| 2 | 20%-30% | 772921 | 0.89 | 1306955 |
| 3 | 30%-40% | 394952 | 0.94 | 710195 |
| 4 | 40%-50% | 227241 | 0.97 | 434120 |
| 5 | 50%-60% | 138981 | 0.98 | 263477 |
| 6 | 60%-70% | 85684 | 0.99 | 150393 |
| 7 | 70%-80% | 45977 | 1.00 | 74472 |
| 8 | 80%-90% | 23199 | 1.00 | 38540 |
| 9 | 90%-100% | 6924 | 1.00 | 13739 |
用可视化的方式展示,如图 15-14 所示。
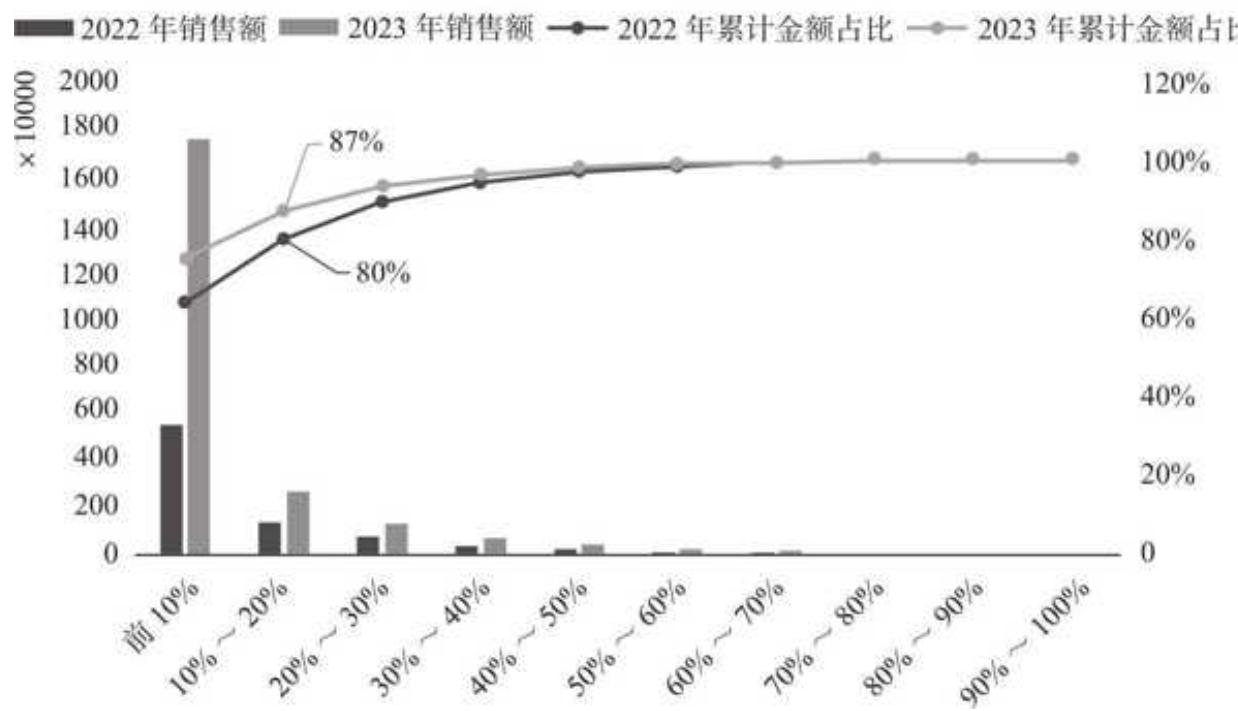
2022~2023 年商品集中度分析图 15-14 两年商品集中度分析
品牌的商品集中效应显著,且这一集中趋势还在增强。2022 年前
15.6 购物篮关联分析
什么是购物篮关联分析
我们把用户单次购买的一系列商品想象成一个购物篮,就像平时逛超市提的购物篮那样。通过分析所有用户购物篮中商品组合购买情况,找到不同商品之间的关系,从而为组合促销、关联推荐提供精准的指导。
实现购物篮关联分析有很多种算法,这里我们对常见的关联算法做了基于实践的改良,提炼出最核心的指标,构建起品牌的关联分析模型。
购物篮关联分析的三大核心指标
购物篮关联分析的三大核心指标分别是支持度、置信度和提升度。
1. 支持度
支持度衡量的是某商品组合同时出现的概率,计算公式如下:

例如,假设同时购买 A 和 B 两种商品的订单有 100 单,对应时间范围内的总订单数是 1000 单,则 A 商品和 B 商品的支持度就等于
2. 置信度
置信度计算的是在买 A 商品的基础上买 B 商品的概率,计算公式如下:

某段时期 A 商品相关的订单一共有 125 单,里面有 100 单是 A 和 B 两种商品同时出现,则 A 商品和 B 商品的置信度等于
需要注意的是,置信度的计算有一个视角问题,这里我们是从 A 商品的视角看 A 和 B 两种商品的置信度,如果从 B 商品的视角来看,就需要用 A 和 B 两种商品同时出现的订单数除以 B 商品相关的订单数。
如果置信度很高,则表示同时购买的概率很大。上面例子中,A 商品和 B 商品的置信度达到了
千万不要操之过急,从置信度看 A 和 B 两种商品同时购买的概率大,可能仅仅是因为 B 商品本身过于畅销。试想一个极端情况,总订单数是 1000,这 1000 单里面有 900 单都含有 B 商品,在这种情况下,无论是哪款商品,和 B 商品同时出现的概率都很大。因此,仅仅看置信度是不够的,还需要结合提升度来分析。
3. 提升度
提升度的作用是帮助我们找到更真实的商品连带购买关系,我们用一个更具体的案例来加强理解,如图 15- 15 所示。
1)计算用户购买精华液的可能性。总订单 100 单,精华液相关的订单有 60 单,用户购买精华液的可能性是
2)计算购买面膜的同时购买精华液的可能性。用在购买面膜的基础上购买精华液的订单数 30 除以面膜相关的订单数 70,得到
3)计算提升度。用购买面膜的同时购买精华液的可能性除以用户购买精华液的可能性,得到一个相对数值 0.72。只有提升度大于 1,才说明关联购买的情况真实存在,且提升度越大,这种关联情况越显著。
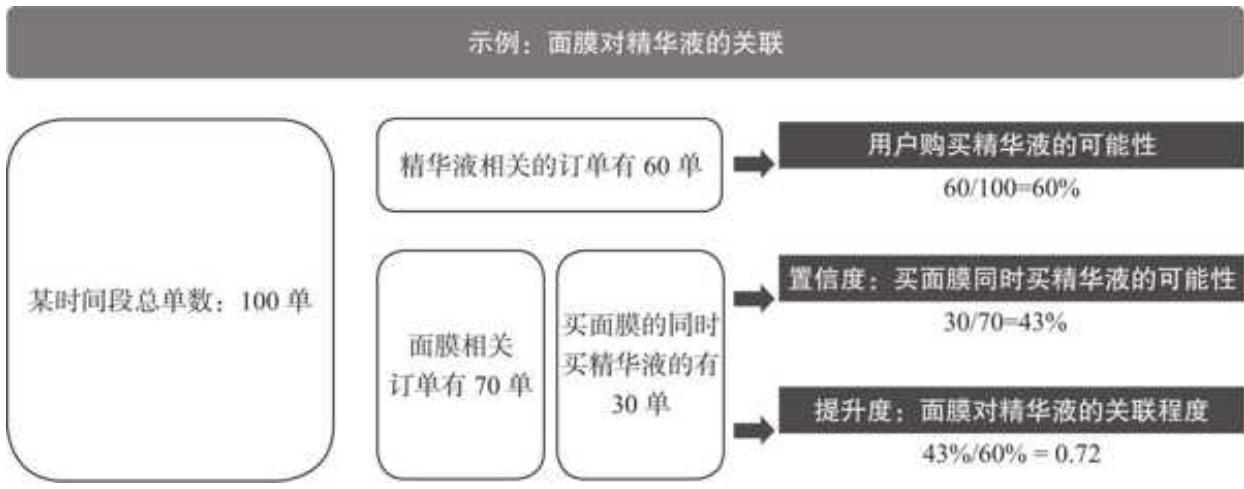
图 15-15 置信度和提升度图解
购物篮关联分析实战
购物篮关联分析的应用非常灵活,既可以是商品层面,如 A 商品和 B 商品的关联,也可以是品类层面,如面膜和精华液的关联。同时,关联规则既有常见的两个商品之间的关联,也有多个商品规则之间的关联。
对于多品类的品牌来说,到商品颗粒度的关联过于细致,品牌更关注不同类目之间可以怎样搭配。受限于人员和资源,做好两类目关联运营就已经很难得了。所以,我们用 Pandas 进行购物篮关联分析,主要解决的是“类目层面,两两类目之间"的关联分析问题。
1. 构造购物篮数据
进行购物篮分析之前,首先需要构造购物篮数据。这里我们把用户单次同时购买的商品看作一个购物篮,按照主订单号进行分组统计,因为一个主订单包括用户同一时间购买的一种或多种商品。
由于我们的分析目标是类目层面,所以统计的是每一个主订单涉及的类目:
自定义一个函数,用来构造每个订单的购物篮
def get_sets(x):
s=[] foriinx: s.append (i) return set (s)
统计每个主订单涉及的品类,品类会去重
item_data
增加一个辅助判断类目,该类目为字符串格式,用于后续统计订单数 item_data['辅助判断类目']
item_data.head ()
这里定义了一个 get sets 函数,它把一个主订单内涉及的多个商品所对应的类目,利用 Python 里集合的特性做了去重处理(集合 set 的元素要求是唯一的)。代码运行结果如下:
| 主订单编号 | 类目 | 辅助判断类目 | |
| 0 | 34896213464 | {面膜} | {& #x27 ; 面膜& #x27 ;} |
| 1 | 34896213465 | {精油, 身体乳} | {& #x27 ; 精油& #x27 ;, & #x27 ; 身体乳& #x27 ;} |
| 2 | 34896213466 | {精油} | {& #x27 ; 精油& #x27 ;} |
| 3 | 34896213467 | {面膜} | {& #x27 ; 面膜& #x27 ;} |
| 4 | 34896213468 | {面霜} | {& #x27 ; 面霜& #x27 ;} |
得到了购物篮表,记录了每个购物篮所涉及的类目数据,同时为了后续的统计分析,增加了字符串格式的辅助判断类目列。
2. 构造类目两两组合
最终我们希望得到两两类目组合下对应的关联数据,这一步,先构造两两类目组合,为后续的循环分析做准备。
from itertools import product
lst
这里我们要统计两两类目组合,作为后续遍历分析的基础,用 itertools 的 product 实现(类似于生成笛卡儿根)as_rule_data
我们用 itertools 的 product 实现了笛卡儿积,即每两个类目之间进行组合,并剔除掉和自己组合的结果,得到两两类目组合的数据:

为了后续的统计分析,还需要构造集合形式的类目组合列和字符串形式的匹配列:
定义函数来组合两列的值,把它变成 set 集合类型 def combine_values(row): return set([row['类目 A'], row['类目 B']]) #类目组合列 ,用于判断每个类目组合出现的次数 as_rule_data['类目组合
两两类目组合表已经构造完成,代码运行后返回如下结果:
| 类目 A | 类目 B | 类目组合 | 辅助匹配类目 |
| 1 | 精油 | {精油, 身体乳} | {& #x27 ; 精油& #x27 ;,& #x27 ; 身体乳& #x27 ;} |
| 2 | 精油 | {精油, 面膜} | {& #x27 ; 精油& #x27 ;,& #x27 ; 面膜& #x27 ;} |
| 3 | 精油 | {精油, 面霜} | {& #x27 ; 精油& #x27 ;,& #x27 ; 面霜& #x27 ;} |
| 4 | 精油 | {精油, 爽肤水} | {& #x27 ; 精油& #x27 ;,& #x27 ; 爽肤水& #x27 ;} |
| 5 | 精油 | {精油, 代餐} | {& #x27 ; 精油& #x27 ;,& #x27 ;代餐& #x27 ;} |
之所以用这种类型来承载类目组合,是因为后续我们要循环判断各种类目组合在购物篮中出现了多少次。集合中的 issubset()方法可以有效判断集合是否为子集,帮助我们完成后续的统计。
集合中 issubset()方法的简单示例如下。
输入:{'面膜','精油'}. issubset({'面膜','爽肤水','精油'}) 返回结果:True
3. 必备基础指标的计算
以面膜和精油的组合为例,要得到支持度、置信度和提升度的值,需要哪些数据呢?根据它们的计算公式,计算这 3 个指标只需要 4 个字段:购物篮总订单数、面膜相关订单数、精油相关订单数、面膜和精油同时购买的订单数。
(1)购物篮总订单数
购物篮总订单数最容易计算,直接统计购物篮订单数即可:
order_num_sum = len (item_data)
order_num_sum 返回了结果,共计 47707 笔订单。
(2)单类目相关订单数
单类目相关订单数用循环遍历的方式计算。判断类目组合表中每一个类目组合在购物篮订单中出现了多少次:
用 item_count 统计各类目对应订单数 item_count = pd.DataFrame ()
遍历类目
for item in as_rule_data['类目 A']. unique (): #统计类目出现的次数 ,用字符串的 find () 方法实现 order_num = len (item_data. loc[item_data['辅助判断类目']. str.find (item) != - 1,)) #构造DataFrame order_df = pd.DataFrame ({'类目':[item, '相关订单数':[order_num]}) #汇总统计 item_count = pd.concat ([item_count, order_df])
得到每个单类目订单数 item_count 后,为了方便计算,将其与两两类目组合表 as_rule_data 关联:
as result
运行之后,完成了类目对应订单数的计算,结果如下:
| 类目 A | 类目 B | 类目组合 | 辅助匹配类目 | 类目 A 的订单数 | 类目 B 的订单数 |
| 0 | 精油 | {身体乳,{身体乳,精油} | {& #x27 ; 身体乳& #x27 ;, & #x27 ; 精油& #x27 ;} | 5803 | 1197 |
| 1 | 面膜 | {面膜,身体乳} | {& #x27 ; 面膜& #x27 ;, & #x27 ; 身体乳& #x27 ;} | 23153 | 1197 |
| 2 | 面霜 | {身体乳,面霜} | {& #x27 ; 身体乳& #x27 ;, & #x27 ; 面霜& #x27 ;} | 4272 | 1197 |
| 3 | 爽肤水 | {身体乳,爽肤水} | {& #x27 ; 身体乳& #x27 ;, & #x27 ; 爽肤水& #x27 ;} | 4954 | 1197 |
| 4 | 代餐 | {身体乳,代餐} | {& #x27 ; 身体乳& #x27 ;, & #x27 ; 代餐& #x27 ;} | 371 | 1197 |
(3)类目组合相关订单数
计算两两类目同时购买的订单数,我们用类目组合表中的两两类目组合,依次去遍历购物篮订单表中的每一个购物篮所包含的组合,判断这个类目组合在购物篮表中出现了(作为子集)多少次,如图 15- 16 所示。
上述逻辑用代码实现如下:
统计类目组合出现的次数
com_item = pd.DataFrame ()
从类目组合表中依次循环对应的类目组合
for item_subset in as_result['类目组合']: count = 0 #统计类目组合表中对应类目组合在购物篮订单中出现的次数 for item_set in item_data['类目']: #如果类目是购物篮订单组合的子集 ,则计数加 1

图 15-16 两两类目同时购买订单的判断逻辑
上述代码循环计算了类目组合表中每一种组合的订单数,结果如下:
依然是为了计算便利,我们把这部分数据和类目组合表匹配整合:
as_result = pd.merge (as_result, com_item '辅助匹配类目', '订单数', left_on = '辅助匹配类目', right_on = '辅助匹配类目', how = 'left') as_result.rename (columns = {'订单数': '关联订单数'}, inplace = True) as_result.head ()
返回的结果的类目组合表包含了关联分析所有的基础指标。
| 类目 A | 类目 B | 类目组合 | 辅助匹配类目 | 类目 A 的订单数 | 类目 B 的订单数 | 关联订单数 |
| 0 | 精油 | {身体乳,精油} | {& #x27 ; 身体乳,& #x27 ;,& #x27 ; 精油& #x27 ;} | 5803 | 1197 | 221 |
| 1 | 面膜 | {面膜,身体乳} | {& #x27 ; 面膜,& #x27 ;,& #x27 ; 身体乳& #x27 ;} | 23153 | 1197 | 276 |
| 2 | 面霜 | {身体乳,面霜} | {& #x27 ; 身体乳,& #x27 ;,& #x27 ; 面霜& #x27 ;} | 4272 | 1197 | 160 |
| 3 | 皮肤水 | {身体乳,皮肤水} | {& #x27 ; 身体乳,& #x27 ;,& #x27 ; 皮肤水& #x27 ;} | 4954 | 1197 | 189 |
| 4 | 代餐 | {身体乳,代餐} | {& #x27 ; 身体乳,& #x27 ;,& #x27 ; 代餐& #x27 ;} | 371 | 1197 | 8 |
4. 购物篮结果分析
(1)核心指标计算
有了前几步的数据准备,购物篮分析核心指标支持度、置信度、提升度的计算变得十分简单,代码如下:
支持度
代码运行之后,得到所有两两类目组合的三大核心指标,如图 15- 17 所示。
| 类目 A | 类目 B | 类目组合 | 类目 A 的订单数 | 类目 B 的订单数 | 关联订单数 | 支持度 | 置信度 | 提升度 |
| 0 | 精油 | (精油, 身体乳) | 5803 | 1197 | 221 | 0.00 | 0.04 | 1.52 |
| 1 | 面膜 | (身体乳, 面膜) | 23153 | 1197 | 276 | 0.01 | 0.01 | 0.48 |
| 2 | 面霜 | (身体乳, 面膜) | 4272 | 1197 | 160 | 0.00 | 0.04 | 1.49 |
| 3 | 爽肤水 | (身体乳, 爽肤水) | 4954 | 1197 | 189 | 0.00 | 0.04 | 1.52 |
| 4 | 代餐 | (代餐, 身体乳) | 371 | 1197 | 8 | 0.00 | 0.02 | 0.86 |
图 15- 17 所有两两类目组合的三大核心指标
(2)根据核心指标进行分析
先看看对两年销售额贡献最高的面膜关联情况
as_result. loc[as_result['类目 A'] == '面膜', i]. sort_values ('支持度', ascending = False)
面膜关联数据如图 15- 18 所示。
| 类目 A | 类目 B | 类目组合 | 类目 A 的订单数 | 类目 B 的订单数 | 关联订单数 | 支持度 | 置信度 | 提升度 | |
| 106 | 面膜 | 精华液 | {精华液, 面膜} | 23153 | 6806 | 1667 | 0.03 | 0.07 | 0.50 |
| 80 | 面膜 | 眼膜 | {面膜, 眼膜} | 23153 | 4419 | 1378 | 0.03 | 0.06 | 0.64 |
| 170 | 面膜 | 精油 | {精油, 面膜} | 23153 | 5803 | 1271 | 0.03 | 0.05 | 0.45 |
| 28 | 面膜 | 面霜 | {面膜, 面霜} | 23153 | 4272 | 960 | 0.02 | 0.04 | 0.46 |
| 41 | 面膜 | 爽肤水 | {面膜, 爽肤水} | 23153 | 4954 | 926 | 0.02 | 0.04 | 0.39 |
| 67 | 面膜 | 洗面奶 | {面膜, 洗面奶} | 23153 | 1594 | 539 | 0.01 | 0.02 | 0.70 |
| 93 | 面膜 | 眼霜 | {面膜, 眼霜} | 23153 | 1503 | 387 | 0.01 | 0.02 | 0.53 |
| 132 | 面膜 | 套装 | {套装, 面膜} | 23153 | 2285 | 311 | 0.01 | 0.01 | 0.28 |
| 1 | 面膜 | 身体乳 | {面膜, 身体乳} | 23153 | 1197 | 276 | 0.01 | 0.01 | 0.48 |
| 54 | 面膜 | 代餐 | {面膜, 代餐} | 23153 | 371 | 131 | 0.00 | 0.01 | 0.73 |
| 158 | 面膜 | 沐浴露 | {面膜, 沐浴露} | 23153 | 388 | 80 | 0.00 | 0.00 | 0.42 |
| 145 | 面膜 | 卸妆液 | {面膜, 卸妆液} | 23153 | 61 | 22 | 0.00 | 0.00 | 0.74 |
| 119 | 面膜 | 活动 | {活动, 面膜} | 23153 | 3796 | 1 | 0.00 | 0.00 | 0.00 |
图 15-18 面膜关联数据
支持度作为购物篮关联算法的守门员指标,主要作用是剔除关联规则中出现频次较低的组合,筛选出高频组合。高频组合在一些算法中称为频繁项集。面膜相关订单有 23153 单,但在面膜组合品类中,支持度最高只有 0.03,对应 1667 笔订单。为了保证筛选出来的类目组合订单数具备一定规模,我们以关联订单数 200 为门槛,筛选出 200 及以上的品类组合。
as_result = as_result. loc[as_result['关联订单数'] >= 200,:]
和面膜同时出现频次最高的品类是精华液,置信度为 0.07,即 100 笔买面膜的订单中会有 7 笔订单同时购买精华液。值得注意的是,结合提升度我们发现,面膜相关的所有品类提升度均小于 1,最大的也只有洗面奶的 0.7,这说明了面膜品类虽然畅销,但绝大部分订单并非连带购买。
item_data['购买品类数'] = item_data['类目']. apply (len) item_data. loc[item_data['辅助判断类目']. str.find ('面膜') != - 1, '购买品类数'. value_counts ()
增加一列计算每个购物篮购买的品类数,然后统计面膜相关的购物篮品类数分布:
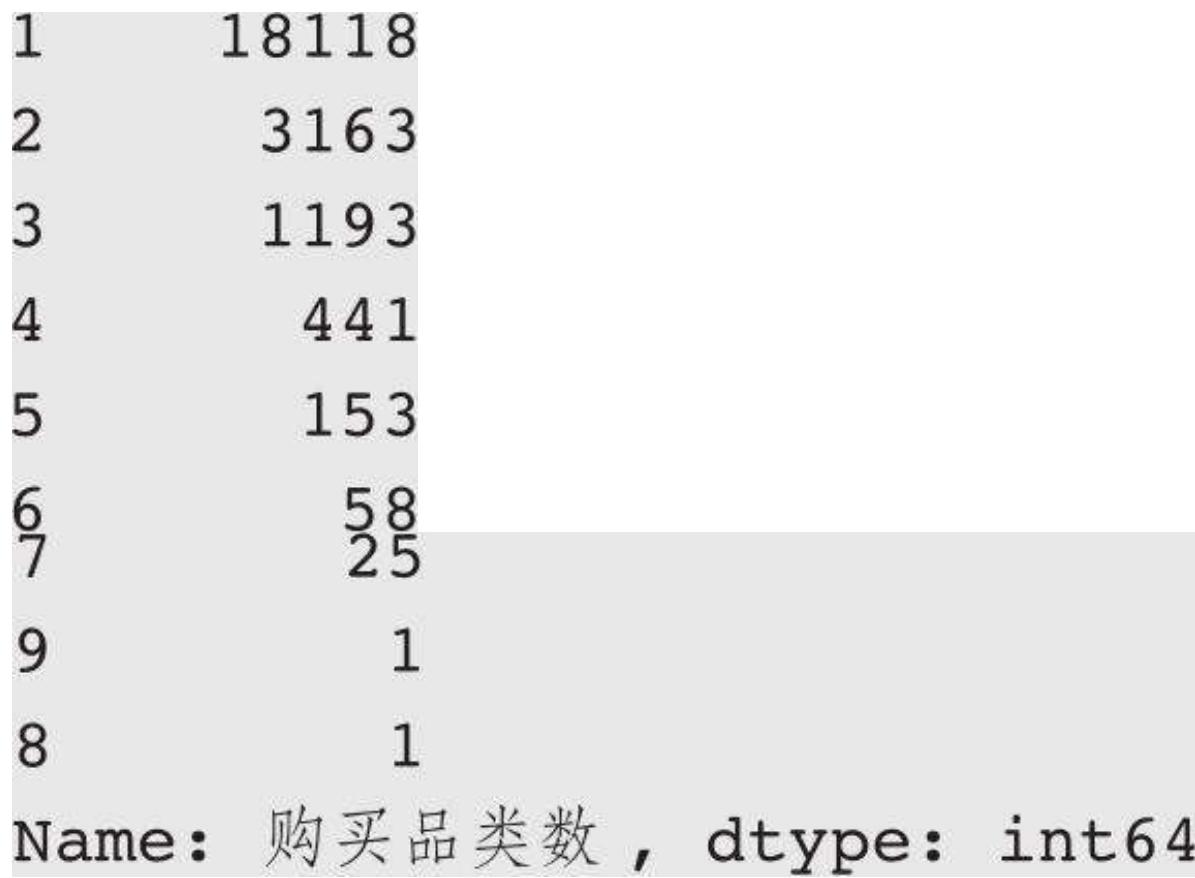
果然,面膜相关订单中有 18118 单只购买了面膜品类,占比接近
我们再来看看精油的情况,代码如下,结果如图 15- 19 所示
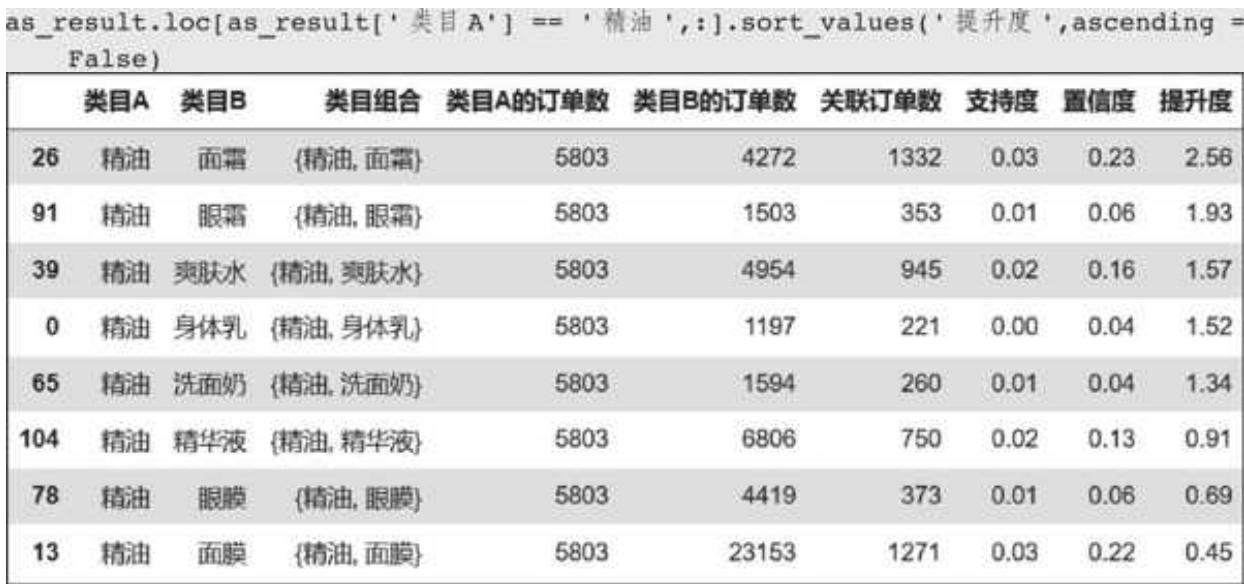
图 15-19 精油关联类目分析
精油类目表现出较好的关联特征,按照提升度排序,精油和面霜的提升度高达 2.56,置信度也有
(3)进阶形式的分析
我们把精油相关的数据转换成图 15- 20 所示的形式。
横坐标是提升度,纵坐标是置信度,气泡大小代表关联订单数(和支持度强相关)。同时,我们加了两条辅助线,一条是置信度均值(横线),另一条则在提升度等于 1 的位置(竖线)。
通过这张气泡图,可以一眼看出精油相关购物篮的关联秘密。
口后续应考虑将面霜和爽肤水与精油强捆绑运营。它们兼具三高特征——高支持度、高置信度、高提升度,具有很强的连带关系。
口眼霜、身体乳、洗面奶为第二梯队关联品类。这 3 个品类与面膜的置信度不高,没能达到均值,但提升度表现亮眼,尤其是眼霜的提升度达到
口面膜独占气泡图的左上角,它与精油的支持度和置信度都很高,不过提升度不足
口精华液和眼膜因为提升度不达标,不在与精油的关联推荐之列。
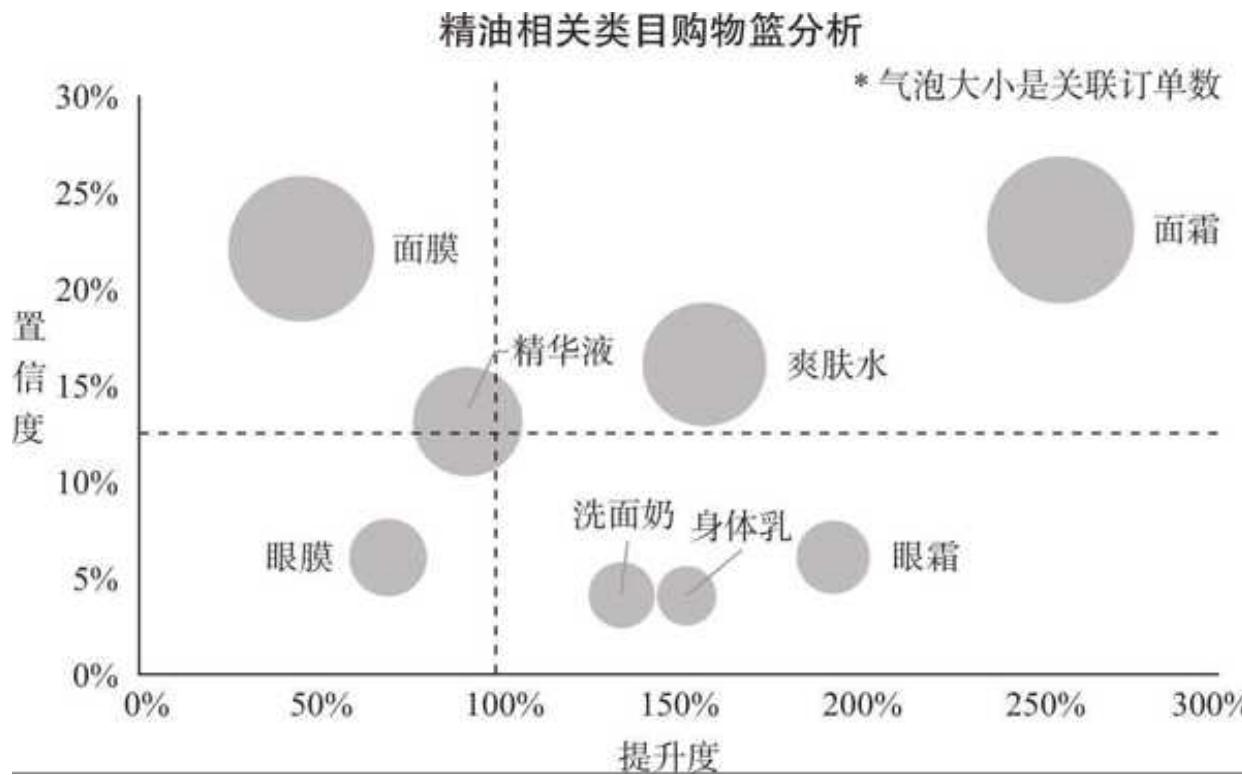
图 15-20 购物篮分析气泡图
用气泡图结合四象限的方法,把品类关联指标平铺开来,帮助我们快速找到有关联机会的品类和体量不够大但有提升空间的品类。当然,更可以用 BI 作为数据的载体,选择任何一个类目,都可以呈现出上述的关联分析气泡图。
15.7 本章小结
在这一章,我们首先了解了不一样的探索性数据分析,这种探索性分析更侧重于业务实际,帮助我们把握数据背后隐藏的机会。随后,基于订单数据,重温由数据预览、重复值校验、缺失值处理、异常值清洗和订单时间筛选构成的完整的数据预处理流程。
处理完数据后,用总览视角看年度销售和用户变化,再从用户出发,更细致地分析了用户核心指标变化趋势,并做了新老客维度、复购率、购买时间间隔的分析,刻画用户购买行为变迁。商品维度分析主要集中在类目销售结构变化,价格带的宽度、深度和广度以及商品的集中度趋势。
最后,我们用购物篮关联分析收尾,从实用的角度介绍了最关键的支持度、置信度和提升度三个指标,同时用两两类目关联分析实例,逐步讲解了关联分析模型的计算过程和分析方法。