散点图
什么是散点图?
散点图(也称为散点图、散列图)使用点来表示两个不同数值变量的值。每个点在水平和垂直轴上的位置表示单个数据点的值。散点图用于观察变量之间的关系。
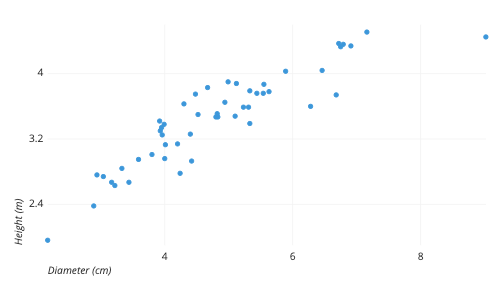
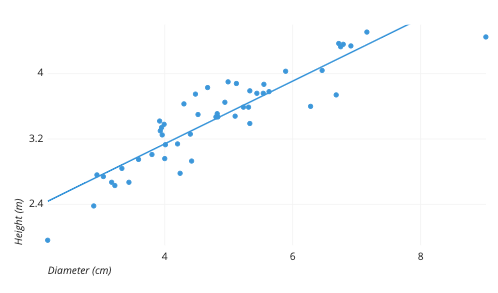
上例中的散点图展示了虚构树木样本的直径和高度。每个点代表一棵树;每个点的水平位置表示该树的直径(单位:厘米),垂直位置表示该树的高度(单位:米)。从图中我们可以看到树木的直径和高度之间存在普遍的紧密正相关。我们还可以观察到一个异常点,即一棵直径远大于其他树木的树。这棵树相对于其周长来说显得比较矮,这可能需要进一步调查。
什么时候应该使用散点图
散点图的主要用途是观察和展示两个数值变量之间的关系。散点图中的点不仅报告单个数据点的值,而且当数据被视为整体时,还能显示出模式。
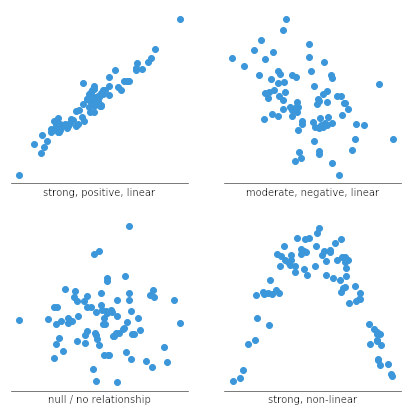
散点图常用于识别相关性关系。在这种情况下,我们想知道,如果我们给定一个特定的水平值,垂直值的一个良好预测会是多少。你通常会看到水平轴上的变量被标记为自变量,垂直轴上的变量为因变量。变量之间的关系可以用多种方式描述:正向或负向、强或弱、线性或非线性。
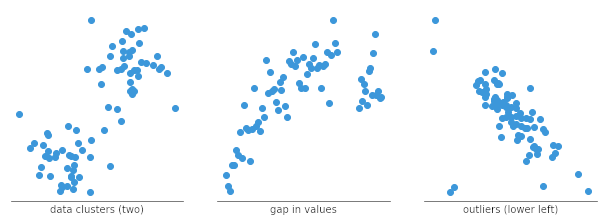
散点图也有助于识别数据中的其他模式。我们可以根据点集聚集的紧密程度将数据点分组。散点图还可以显示数据中是否存在任何意外的空白区域,以及是否存在任何离群点。如果我们想将数据分割成不同的部分,比如在用户角色开发中,这会很有用。
数据结构示例
| DIAMETER | HEIGHT |
|---|---|
| 4.20 | 3.14 |
| 5.55 | 3.87 |
| 3.33 | 2.84 |
| 6.91 | 4.34 |
要创建散点图,我们需要从数据表中选择两列,分别对应图表的两个维度。表中的每一行将成为图中的一个点,其位置根据列的值确定。
使用散点图时的常见问题
过度堆叠
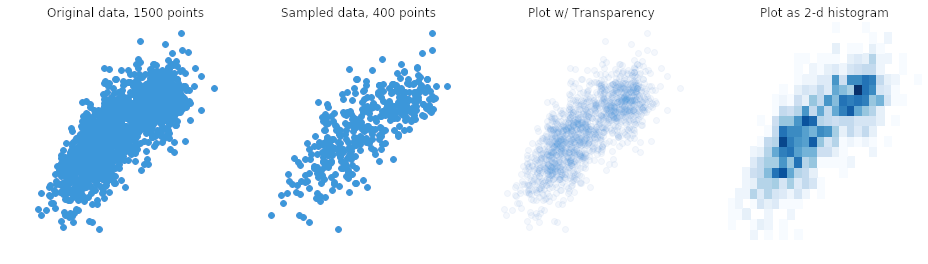
当我们要绘制大量数据点时,可能会遇到过度堆叠的问题。过度堆叠是指数据点重叠到一定程度,以至于我们难以看清点与变量之间的关系。当许多数据点集中在小区域时,很难判断这些点的密集程度。
有几种常见的方法可以缓解这个问题。一种替代方案是仅采样数据点的一个子集:随机选择的一些点仍然应该能给出完整数据中模式的大致概念。我们也可以改变点的形式,增加透明度以允许重叠可见,或减小点的大小以减少重叠。作为第三种选择,我们甚至可以选择另一种图表类型,比如热力图 ,其中颜色表示每个箱中的点数。在这种情况下,热力图也被称为二维直方图。
将相关性误认为因果关系
这与其说是创建散点图的问题,不如说是对其解读的问题。仅仅因为在散点图中观察到两个变量之间存在关系,并不意味着一个变量的变化是另一个变量变化的原因。这便引出了统计学中常见的说法—— 相关性不意味着因果关系 。观察到的关系可能是由某个影响两个变量的第三个变量驱动的,因果关系可能是相反的,或者这种模式仅仅是巧合。
例如,如果仅通过城市拥有的绿地面积和犯罪数量等统计数据就得出两者之间存在因果关系,这是错误的。这样做可能会忽略这样一个事实:人口更多、规模更大的城市往往在这两方面都表现得更突出,并且它们之间的相关性可能是由其他因素造成的。若要建立因果关系,就需要进行进一步分析,以控制或考虑其他潜在变量的影响,从而排除其他可能的解释。
常见的散点图选项
添加趋势线
当使用散点图来观察变量之间的预测或相关性关系时,通常会在图中添加一条趋势线,以显示数据在数学上的最佳拟合。这可以提供关于两个变量之间关系强度的额外信号,并判断是否存在任何异常点影响趋势线的计算。
分类的第三个变量
基本散点图的一种常见修改是添加第三个变量。第三个变量的值可以通过改变点的绘制方式来编码。对于表示分类值(如地理区域或性别)的第三个变量,最常见的编码方式是通过点的颜色。给每个点分配不同的色调,可以轻松地展示每个点分别属于哪个组。
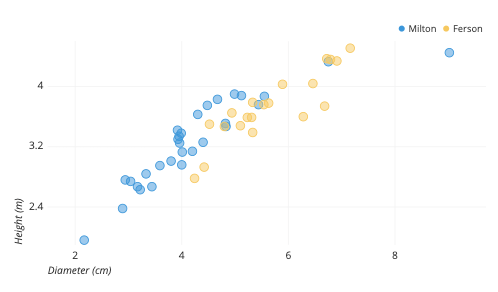
通过按树木类型着色点可以看出,费尔森(黄色)通常比米尔顿(蓝色)更宽,但在相同直径下也更矮。
第三变量编码的另一种选择有时是形状。形状的一个潜在问题是不同的形状可以有不同的尺寸和表面积,这可能会影响对组别的感知。然而,在某些情况下,例如在印刷品中无法使用颜色时,形状可能是区分组别的最佳选择。

上面的形状已经按相同的墨量进行了缩放。
数值型第三变量
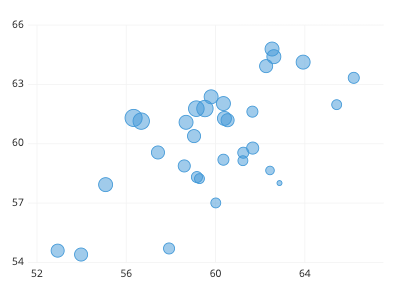
对于具有数值的第三个变量,一种常见的编码方式是改变点的大小。一个基于第三个变量的点大小散点图实际上有一个独特的名称,即气泡图 。较大的点表示较高的值。关于如何构建气泡图的更详细讨论,可以阅读其专门文章。
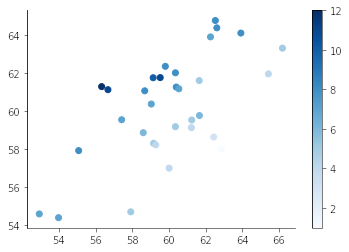
色相也可以用来表示数值,作为另一种替代方案。与在分类情况下使用不同颜色表示点不同,我们希望使用连续的颜色序列,例如,较深的颜色表示较高的值。请注意,对于大小和颜色,图例对于解释第三个变量都很重要,因为我们的眼睛在辨别大小和颜色方面远不如辨别位置那么容易。
使用注释和颜色突出显示
如果你想要使用散点图来展示见解,可以通过注释和颜色突出显示特定的兴趣点。将不重要的点去饱和化可以使剩余的点更加突出,并提供一个参考,以便将剩余的点与之比较。
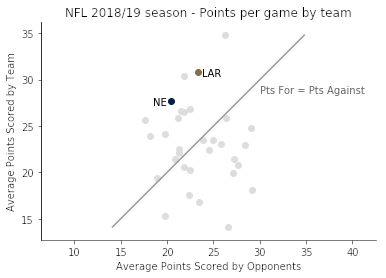
相关图
散点图
当散点图中的两个变量是地理坐标——纬度和经度时,我们可以将点叠加在地图上,从而得到散点地图(也称为点地图)。当地理背景有助于获取特定见解时,这种方法会非常方便,并且可以与其他第三变量的编码(如点的大小和颜色)结合使用。
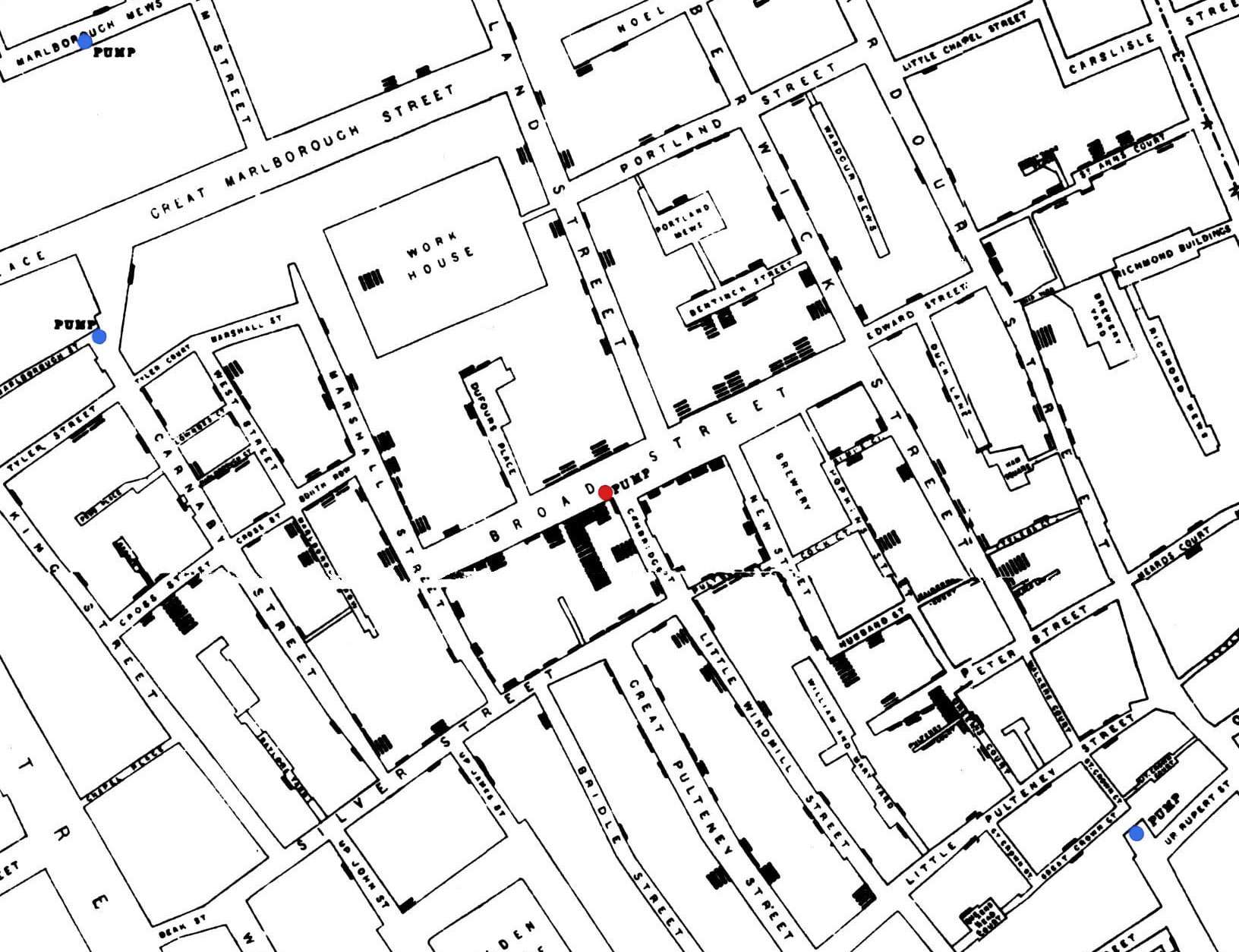
散点图的一个著名例子是约翰·斯诺在 1854 年绘制的霍乱爆发地图,该地图显示霍乱病例(黑色条形)集中在布罗德街(中心点)的一个特定水泵周围。来源:维基共享资源
热力图
如上所述,当需要绘制大量数据点且其密度导致重叠问题时, 热图 可以作为散点图的良好替代方案。然而,热图也可以以类似的方式使用,以展示变量之间的关系,特别是当其中一个或两个变量不是连续的数值型时。如果我们尝试用散点图描绘离散值,同一级别的所有点都会排成一条直线。热图可以通过将值分箱到计数框中来克服这种重叠问题。
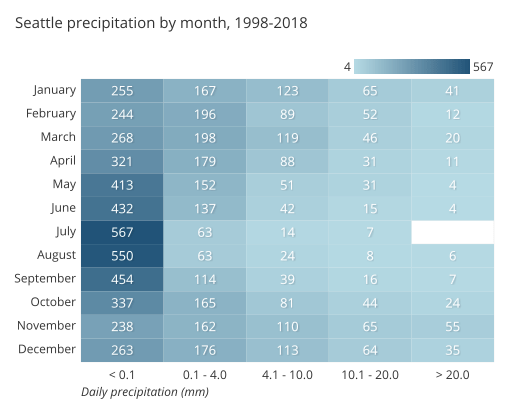
连接式散点图
如果我们想要添加到散点图中的第三个变量表示时间戳,那么可以选择的一种图表类型是连接式散点图。我们不是通过改变点的形式来表示日期,而是使用线段按顺序连接观测值。这可以更容易地看出两个主要变量不仅相互关联,而且这种关系如何随时间变化。如果水平轴也对应时间,那么所有的线段将始终从左到右连接点,我们就得到了一个基本的折线图 。
可视化工具
散点图是任何可视化工具或解决方案都应该能够创建的基本图表类型。计算基本的线性趋势线也是一个相当常见的选项,同样,根据第三个分类变量的级别对点进行着色也是一个常见选项。然而,非线性趋势线和通过形状编码第三个变量的值等选项并不常见。即使没有这些选项,散点图仍然是一个非常有价值的图表类型,当你需要调查数据中数值变量之间的关系时可以使用。
散点图是许多不同图表类型中的一种,可用于数据可视化。从我们的关于基本图表类型、如何选择数据可视化类型的文章中了解更多,或浏览图表类别中的所有文章。